Emerging Properties in Unified Multimodal Pretraining
作者: Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, Haoqi Fan
分类: cs.CV
发布日期: 2025-05-20 (更新: 2025-07-27)
备注: 37 pages, 17 figures
💡 一句话要点
BAGEL:一个支持多模态理解与生成的开源统一预训练模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态预训练 统一模型 多模态理解 多模态生成 Transformer解码器 开源模型 大规模数据 多模态推理
📋 核心要点
- 现有专有系统在多模态理解和生成方面表现出色,但开源模型仍有差距,限制了研究的广泛开展。
- BAGEL通过统一的解码器架构和在海量多模态交错数据上的预训练,实现了多模态理解和生成的统一。
- 实验表明,BAGEL在多模态生成和理解任务上超越了现有开源模型,并展现出图像操作、未来预测等高级推理能力。
📝 摘要(中文)
本文介绍BAGEL,一个开源的基础模型,原生支持多模态理解和生成。BAGEL是一个统一的、仅解码器的模型,在从大规模交错的文本、图像、视频和网络数据中整理出的数万亿token上进行预训练。当使用这种多样化的多模态交错数据进行扩展时,BAGEL在复杂的多模态推理中表现出新兴的能力。因此,它在标准基准测试中显著优于开源统一模型的多模态生成和理解,同时表现出先进的多模态推理能力,如自由形式的图像操作、未来帧预测、3D操作和世界导航。为了促进多模态研究的进一步机会,我们分享了关键发现、预训练细节、数据创建协议,并将我们的代码和检查点发布给社区。
🔬 方法详解
问题定义:现有的大型多模态模型通常是闭源的,限制了学术界和工业界的研究和应用。开源模型在多模态理解和生成能力上与闭源模型存在显著差距,尤其是在复杂的多模态推理任务上。因此,需要一个高性能、开源且易于使用的多模态基础模型,以促进相关领域的研究。
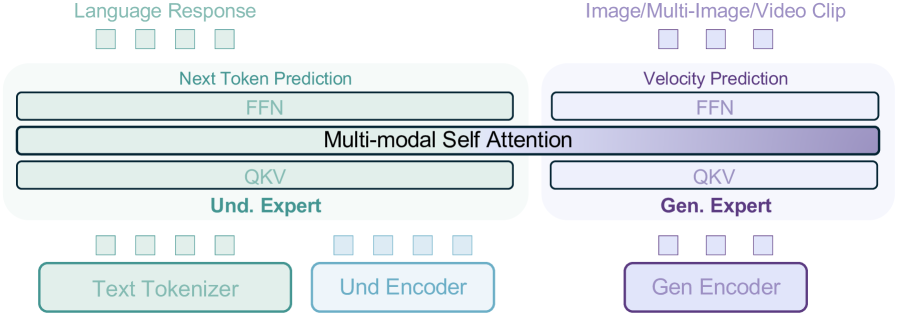
核心思路:BAGEL的核心思路是构建一个统一的、仅解码器的模型,并在大规模的多模态交错数据上进行预训练。通过这种方式,模型可以学习到不同模态之间的关联,并具备多模态理解、生成和推理能力。选择仅解码器架构是为了方便生成任务,并简化模型结构。
技术框架:BAGEL采用Transformer解码器架构,整体流程包括数据收集与清洗、模型预训练和下游任务微调三个阶段。数据收集阶段构建包含文本、图像、视频等多种模态的大规模数据集。预训练阶段使用自回归目标训练模型,使其能够根据上下文预测下一个token。微调阶段则根据具体任务对模型进行调整。
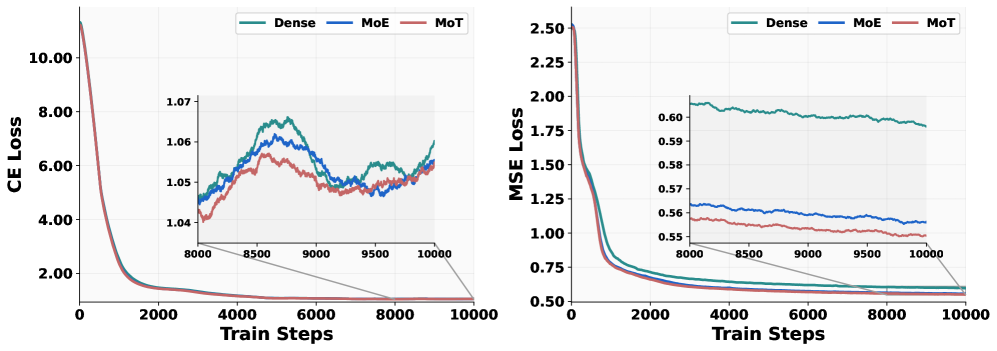
关键创新:BAGEL的关键创新在于其统一的架构和大规模的多模态交错数据预训练。与以往的多模态模型相比,BAGEL能够更好地利用不同模态之间的信息,从而在多模态理解、生成和推理任务上取得更好的性能。此外,BAGEL的开源特性也使其能够被更广泛地使用和研究。
关键设计:BAGEL的关键设计包括:1) 使用大规模的多模态交错数据进行预训练,数据来源于文本、图像、视频和网页等多种来源;2) 采用Transformer解码器架构,并使用自回归目标进行训练;3) 通过调整模型大小和训练时长来平衡性能和计算成本;4) 提供详细的预训练细节和数据创建协议,方便其他研究者复现和改进。
🖼️ 关键图片

📊 实验亮点
BAGEL在多个标准多模态基准测试中显著优于现有的开源统一模型。例如,在多模态生成任务中,BAGEL取得了SOTA的结果。此外,BAGEL还展现出强大的多模态推理能力,例如自由形式的图像操作、未来帧预测、3D操作和世界导航,这些能力在以往的开源模型中很少见到。
🎯 应用场景
BAGEL具有广泛的应用前景,包括但不限于:多模态对话系统、图像/视频编辑、机器人控制、虚拟现实等。它可以用于构建更智能、更自然的交互界面,并为各种应用提供强大的多模态理解和生成能力。开源的特性也使得BAGEL可以被广泛应用于学术研究和工业实践,促进多模态人工智能的发展。
📄 摘要(原文)
Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. In this work, we introduce BAGEL, an open-source foundational model that natively supports multimodal understanding and generation. BAGEL is a unified, decoder-only model pretrained on trillions of tokens curated from large-scale interleaved text, image, video, and web data. When scaled with such diverse multimodal interleaved data, BAGEL exhibits emerging capabilities in complex multimodal reasoning. As a result, it significantly outperforms open-source unified models in both multimodal generation and understanding across standard benchmarks, while exhibiting advanced multimodal reasoning abilities such as free-form image manipulation, future frame prediction, 3D manipulation, and world navigation. In the hope of facilitating further opportunities for multimodal research, we share the key findings, pretraining details, data creation protocal, and release our code and checkpoints to the community. The project page is at https://bagel-ai.org/