Scaling and Enhancing LLM-based AVSR: A Sparse Mixture of Projectors Approach
作者: Umberto Cappellazzo, Minsu Kim, Stavros Petridis, Daniele Falavigna, Alessio Brutti
分类: eess.AS, cs.CV, cs.MM, cs.SD
发布日期: 2025-05-20 (更新: 2025-05-21)
备注: Interspeech 2025
💡 一句话要点
提出Llama-SMoP:一种基于稀疏混合投影器的可扩展LLM语音识别方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频-视频语音识别 多模态学习 大型语言模型 稀疏混合专家 模型压缩 噪声鲁棒性 Llama-SMoP
📋 核心要点
- 现有AVSR方法计算成本高昂,难以在资源受限的环境中部署大型语言模型(LLM)。
- Llama-SMoP利用稀疏混合投影器(SMoP)扩展模型容量,在不增加推理成本的前提下,提升性能。
- 实验表明,Llama-SMoP DEDR配置在ASR、VSR和AVSR任务上均表现出色,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Llama-SMoP的高效多模态LLM,用于提升音频-视频语音识别(AVSR)在噪声环境下的鲁棒性。该模型采用稀疏混合投影器(SMoP)模块,在不增加推理成本的前提下扩展模型容量。Llama-SMoP通过结合稀疏门控混合专家(MoE)投影器,能够在保持强大性能的同时使用更小的LLM。论文探索了三种SMoP配置,结果表明,使用模态特定路由器和专家的Llama-SMoP DEDR(Disjoint-Experts, Disjoint-Routers)在ASR、VSR和AVSR任务上表现最佳。消融研究证实了其在专家激活、可扩展性和噪声鲁棒性方面的有效性。
🔬 方法详解
问题定义:本文旨在解决将大型语言模型(LLM)应用于音频-视频语音识别(AVSR)时,计算成本过高的问题。现有方法在资源受限的环境中难以部署,限制了LLM在AVSR领域的应用。
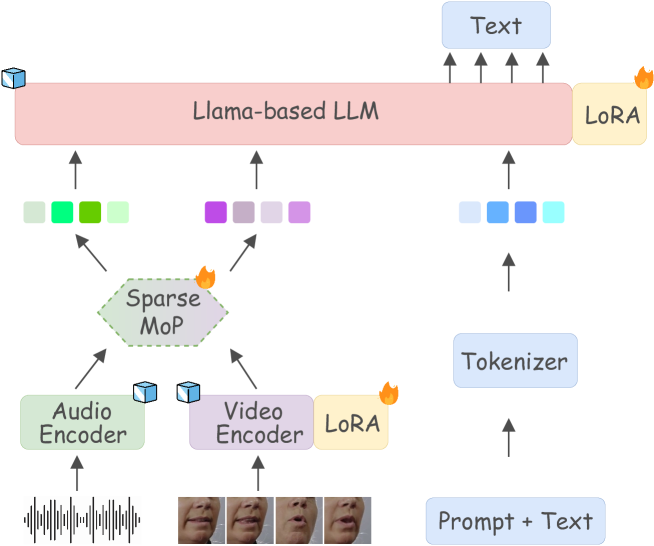
核心思路:论文的核心思路是利用稀疏混合专家(MoE)的思想,通过稀疏门控的投影器(SMoP)来扩展模型容量,从而在不显著增加推理成本的前提下,提升AVSR的性能。这样既能利用LLM的强大能力,又能降低计算负担。
技术框架:Llama-SMoP模型的核心是SMoP模块,它被集成到LLM中。整体流程包括:首先,音频和视频特征被提取并输入到LLM中;然后,SMoP模块根据输入特征,动态地选择激活部分专家投影器;最后,激活的专家投影器的输出被用于后续的LLM处理和语音识别任务。论文探索了三种SMoP配置,包括共享专家和路由器、共享专家但独立路由器、以及独立专家和路由器(DEDR)。
关键创新:关键创新在于SMoP模块的设计,它允许模型在推理时只激活部分专家,从而实现模型容量的扩展,而无需增加推理时的计算量。与传统的密集模型相比,SMoP提供了一种更高效的模型扩展方式。DEDR配置是另一个创新点,它允许模型为不同的模态(音频和视频)学习特定的专家和路由策略,从而更好地适应不同模态的特征。
关键设计:SMoP模块的关键设计包括:1) 稀疏门控机制,用于动态选择激活的专家;2) 专家投影器的数量和维度,需要根据具体的任务和资源进行调整;3) 路由器的设计,包括路由器的数量和结构,以及路由策略的选择。论文探索了三种不同的SMoP配置,并发现DEDR配置效果最佳。损失函数方面,除了标准的语音识别损失外,可能还包括用于鼓励专家多样性的辅助损失(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Llama-SMoP DEDR配置在ASR、VSR和AVSR任务上均取得了显著的性能提升。具体数据未知,但摘要强调了其在专家激活、可扩展性和噪声鲁棒性方面的有效性。该方法能够在保持性能的同时,降低计算成本,使其更适用于实际应用。
🎯 应用场景
该研究成果可应用于各种需要语音识别的场景,尤其是在资源受限或噪声严重的环境中,例如移动设备上的语音助手、车载语音控制系统、以及工业环境下的语音指令识别。通过降低LLM的计算成本,该方法有望加速LLM在AVSR领域的普及和应用。
📄 摘要(原文)
Audio-Visual Speech Recognition (AVSR) enhances robustness in noisy environments by integrating visual cues. While recent advances integrate Large Language Models (LLMs) into AVSR, their high computational cost hinders deployment in resource-constrained settings. To address this, we propose Llama-SMoP, an efficient Multimodal LLM that employs a Sparse Mixture of Projectors (SMoP) module to scale model capacity without increasing inference costs. By incorporating sparsely-gated mixture-of-experts (MoE) projectors, Llama-SMoP enables the use of smaller LLMs while maintaining strong performance. We explore three SMoP configurations and show that Llama-SMoP DEDR (Disjoint-Experts, Disjoint-Routers), which uses modality-specific routers and experts, achieves superior performance on ASR, VSR, and AVSR tasks. Ablation studies confirm its effectiveness in expert activation, scalability, and noise robustness.