UniVG-R1: Reasoning Guided Universal Visual Grounding with Reinforcement Learning
作者: Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, Yansong Tang
分类: cs.CV
发布日期: 2025-05-20
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出UniVG-R1,通过强化学习增强推理能力,解决通用视觉定位任务。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 多模态学习 强化学习 思维链 大型语言模型 推理能力 零样本学习
📋 核心要点
- 现有视觉定位方法难以处理多图像、复杂指令的真实场景,缺乏跨模态推理能力。
- UniVG-R1通过构建CoT数据集进行监督微调,并利用强化学习激励模型学习正确的推理链。
- 实验表明,UniVG-R1在MIG-Bench上取得了SOTA性能,零样本泛化能力在多个基准上平均提升23.4%。
📝 摘要(中文)
传统视觉定位方法主要关注单图像场景和简单的文本描述。然而,将其扩展到涉及隐式和复杂指令,特别是结合多图像的真实场景时,面临着巨大的挑战,这主要是由于缺乏跨多模态上下文的高级推理能力。本文旨在解决更实用的通用定位任务,并提出了UniVG-R1,一个通过强化学习(RL)结合冷启动数据来增强推理能力的多模态大型语言模型(MLLM),用于通用视觉定位。具体来说,我们首先构建了一个高质量的思维链(CoT)定位数据集,该数据集用详细的推理链进行标注,以通过监督微调引导模型走向正确的推理路径。随后,我们执行基于规则的强化学习,以鼓励模型识别正确的推理链,从而激励其推理能力。此外,我们发现随着RL训练的进行,容易样本的普遍存在会导致难度偏差,因此我们提出了一种难度感知权重调整策略,以进一步加强性能。实验结果表明了UniVG-R1的有效性,它在MIG-Bench上实现了最先进的性能,比以前的方法提高了9.1%。此外,我们的模型表现出强大的泛化能力,在四个图像和视频推理定位基准测试中,零样本性能平均提高了23.4%。
🔬 方法详解
问题定义:传统视觉定位方法主要集中在单张图像和简单的文本描述上,难以应对真实世界中涉及多张图像和复杂、隐式指令的场景。现有方法缺乏在多模态上下文中进行高级推理的能力,导致定位精度下降。
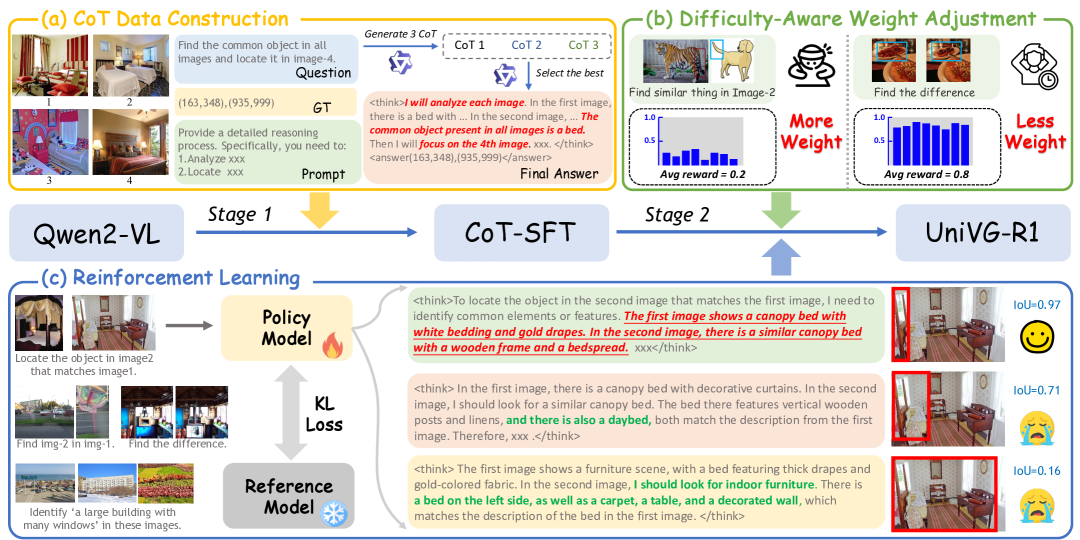
核心思路:UniVG-R1的核心思路是通过强化学习来提升多模态大型语言模型(MLLM)的推理能力,使其能够更好地理解复杂指令并进行视觉定位。通过构建高质量的思维链(CoT)数据集,并结合监督微调和强化学习,引导模型学习正确的推理路径。
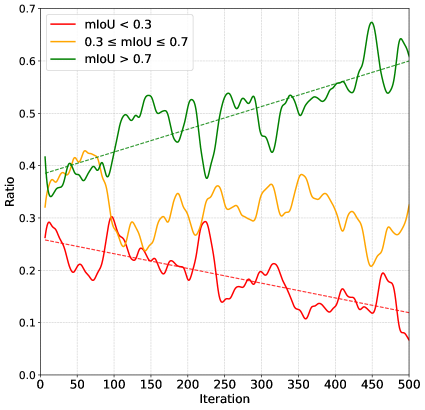
技术框架:UniVG-R1的整体框架包含以下几个主要阶段:1) 构建高质量的CoT定位数据集,其中包含详细的推理链标注;2) 使用CoT数据集对MLLM进行监督微调,使其初步具备推理能力;3) 使用基于规则的强化学习,进一步激励模型学习正确的推理链;4) 提出难度感知权重调整策略,解决RL训练过程中出现的难度偏差问题。
关键创新:UniVG-R1的关键创新在于将强化学习引入到视觉定位任务中,并结合CoT数据集和难度感知权重调整策略,有效地提升了模型的推理能力和泛化能力。与现有方法相比,UniVG-R1能够更好地处理复杂指令和多图像场景,实现更准确的视觉定位。
关键设计:在强化学习阶段,采用了基于规则的奖励函数,鼓励模型生成正确的推理链。难度感知权重调整策略根据样本的难度动态调整权重,避免模型过度拟合简单样本。具体的网络结构和参数设置在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
UniVG-R1在MIG-Bench上取得了最先进的性能,相比之前的方法提升了9.1%。更重要的是,该模型展现了强大的零样本泛化能力,在四个图像和视频推理定位基准测试中,平均提升了23.4%。这些结果表明,UniVG-R1在提升推理能力和泛化能力方面取得了显著进展。
🎯 应用场景
UniVG-R1具有广泛的应用前景,例如智能导航、机器人交互、智能监控、图像/视频检索等。它可以帮助机器更好地理解人类指令,并在复杂环境中进行视觉定位,从而实现更智能、更高效的人机交互和自动化任务。该研究的突破将推动视觉定位技术在实际场景中的应用。
📄 摘要(原文)
Traditional visual grounding methods primarily focus on single-image scenarios with simple textual references. However, extending these methods to real-world scenarios that involve implicit and complex instructions, particularly in conjunction with multiple images, poses significant challenges, which is mainly due to the lack of advanced reasoning ability across diverse multi-modal contexts. In this work, we aim to address the more practical universal grounding task, and propose UniVG-R1, a reasoning guided multimodal large language model (MLLM) for universal visual grounding, which enhances reasoning capabilities through reinforcement learning (RL) combined with cold-start data. Specifically, we first construct a high-quality Chain-of-Thought (CoT) grounding dataset, annotated with detailed reasoning chains, to guide the model towards correct reasoning paths via supervised fine-tuning. Subsequently, we perform rule-based reinforcement learning to encourage the model to identify correct reasoning chains, thereby incentivizing its reasoning capabilities. In addition, we identify a difficulty bias arising from the prevalence of easy samples as RL training progresses, and we propose a difficulty-aware weight adjustment strategy to further strengthen the performance. Experimental results demonstrate the effectiveness of UniVG-R1, which achieves state-of-the-art performance on MIG-Bench with a 9.1% improvement over the previous method. Furthermore, our model exhibits strong generalizability, achieving an average improvement of 23.4% in zero-shot performance across four image and video reasoning grounding benchmarks. The project page can be accessed at https://amap-ml.github.io/UniVG-R1-page/.