RoPECraft: Training-Free Motion Transfer with Trajectory-Guided RoPE Optimization on Diffusion Transformers
作者: Ahmet Berke Gokmen, Yigit Ekin, Bahri Batuhan Bilecen, Aysegul Dundar
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-05-19 (更新: 2025-11-24)
备注: https://berkegokmen1.github.io/RoPECraft/
💡 一句话要点
RoPECraft:基于轨迹引导RoPE优化的无训练扩散Transformer视频动作迁移
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频动作迁移 扩散Transformer 旋转位置嵌入 光流估计 无训练学习
📋 核心要点
- 现有视频动作迁移方法通常需要大量训练数据,且泛化能力有限,难以适应新的动作或风格。
- RoPECraft通过优化扩散Transformer的旋转位置嵌入(RoPE),将参考视频的运动信息无训练地融入生成过程。
- 实验结果表明,RoPECraft在多个基准测试中超越了现有方法,实现了高质量的视频动作迁移。
📝 摘要(中文)
我们提出RoPECraft,一种用于扩散Transformer的无训练视频动作迁移方法,它仅通过修改旋转位置嵌入(RoPE)来实现。首先,我们从参考视频中提取密集光流,并利用得到的运动偏移来扭曲RoPE的复指数张量,从而有效地将运动编码到生成过程中。然后,在去噪时间步中,通过使用流动匹配目标函数,在预测速度和目标速度之间进行轨迹对齐,进一步优化这些嵌入。为了保持输出与文本提示的一致性并防止重复生成,我们结合了一个基于参考视频傅里叶变换相位分量的正则化项,将相位角投影到平滑流形上以抑制高频伪影。在基准测试上的实验表明,RoPECraft在质量和数量上都优于所有最近发布的方法。
🔬 方法详解
问题定义:视频动作迁移旨在将一个视频的动作转移到另一个视频上,同时保持目标视频的内容和风格。现有方法通常依赖于大量的训练数据,并且难以泛化到新的动作或风格。此外,训练过程计算成本高昂,限制了其应用范围。
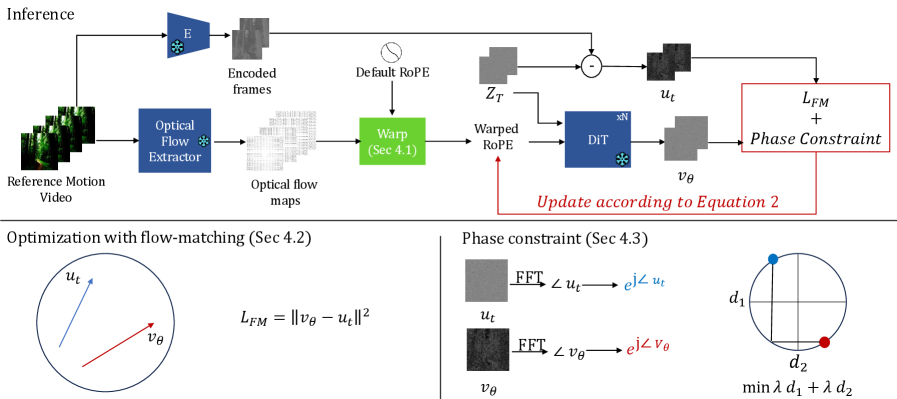
核心思路:RoPECraft的核心思想是通过修改扩散Transformer的旋转位置嵌入(RoPE),将参考视频的运动信息无训练地融入到生成过程中。通过光流估计参考视频的运动信息,并将其编码到RoPE中,从而引导生成过程。
技术框架:RoPECraft的整体框架包括以下几个主要步骤:1) 从参考视频中提取密集光流;2) 利用光流信息扭曲RoPE的复指数张量,将运动信息编码到RoPE中;3) 在扩散模型的去噪过程中,使用流动匹配目标函数优化RoPE,以对齐预测速度和目标速度;4) 使用基于傅里叶变换相位分量的正则化项,保持输出与文本提示的一致性,并抑制高频伪影。
关键创新:RoPECraft的关键创新在于其无训练的动作迁移方法。通过直接操作扩散模型的RoPE,避免了耗时的训练过程,并且能够更好地泛化到新的动作和风格。此外,使用流动匹配目标函数和相位正则化项,进一步提高了生成视频的质量和一致性。
关键设计:RoPECraft的关键设计包括:1) 使用RAFT等光流估计器提取高质量的密集光流;2) 使用复指数张量表示RoPE,并利用光流信息对其进行扭曲;3) 使用L2损失作为流动匹配目标函数,优化RoPE;4) 使用傅里叶变换相位分量的L1损失作为正则化项,保持输出与文本提示的一致性。
🖼️ 关键图片


📊 实验亮点
RoPECraft在多个视频动作迁移基准测试中取得了显著的性能提升。与现有方法相比,RoPECraft在生成视频的质量、动作一致性和风格保持方面均有明显优势。实验结果表明,RoPECraft能够生成高质量、逼真的视频动作迁移结果,并且具有良好的泛化能力。
🎯 应用场景
RoPECraft具有广泛的应用前景,包括视频编辑、虚拟现实、游戏开发等领域。它可以用于将一个人的舞蹈动作转移到另一个人身上,或者将一个物体的运动轨迹应用到另一个物体上。此外,RoPECraft还可以用于生成具有特定动作的合成视频,例如,生成一个机器人跳舞的视频。
📄 摘要(原文)
We propose RoPECraft, a training-free video motion transfer method for diffusion transformers that operates solely by modifying their rotary positional embeddings (RoPE). We first extract dense optical flow from a reference video, and utilize the resulting motion offsets to warp the complex-exponential tensors of RoPE, effectively encoding motion into the generation process. These embeddings are then further optimized during denoising time steps via trajectory alignment between the predicted and target velocities using a flow-matching objective. To keep the output faithful to the text prompt and prevent duplicate generations, we incorporate a regularization term based on the phase components of the reference video's Fourier transform, projecting the phase angles onto a smooth manifold to suppress high-frequency artifacts. Experiments on benchmarks reveal that RoPECraft outperforms all recently published methods, both qualitatively and quantitatively.