DD-Ranking: Rethinking the Evaluation of Dataset Distillation
作者: Zekai Li, Xinhao Zhong, Samir Khaki, Zhiyuan Liang, Yuhao Zhou, Mingjia Shi, Ziqiao Wang, Xuanlei Zhao, Wangbo Zhao, Ziheng Qin, Mengxuan Wu, Pengfei Zhou, Haonan Wang, David Junhao Zhang, Jia-Wei Liu, Shaobo Wang, Dai Liu, Linfeng Zhang, Guang Li, Kun Wang, Zheng Zhu, Zhiheng Ma, Joey Tianyi Zhou, Jiancheng Lv, Yaochu Jin, Peihao Wang, Kaipeng Zhang, Lingjuan Lyu, Yiran Huang, Zeynep Akata, Zhiwei Deng, Xindi Wu, George Cazenavette, Yuzhang Shang, Justin Cui, Jindong Gu, Qian Zheng, Hao Ye, Shuo Wang, Xiaobo Wang, Yan Yan, Angela Yao, Mike Zheng Shou, Tianlong Chen, Hakan Bilen, Baharan Mirzasoleiman, Manolis Kellis, Konstantinos N. Plataniotis, Zhangyang Wang, Bo Zhao, Yang You, Kai Wang
分类: cs.CV
发布日期: 2025-05-19 (更新: 2025-09-21)
备注: 20 pages, 4 figures
💡 一句话要点
DD-Ranking:重新思考数据集蒸馏的评估方法,提出更公平的评估框架。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 评估框架 信息增强 公平评估 数据压缩 模型加速 合成数据
📋 核心要点
- 现有数据集蒸馏评估方法过度依赖准确率,忽略了数据增强等额外技术带来的性能提升,导致评估结果失真。
- DD-Ranking 提出统一的评估框架和新的评估指标,更关注蒸馏数据集本身的信息增强,从而实现更公平的评估。
- 实验表明,DD-Ranking 能更准确地反映数据集蒸馏方法的真实性能,为未来研究提供更可靠的评估标准。
📝 摘要(中文)
近年来,数据集蒸馏为数据压缩提供了一种可靠的解决方案,通过在更小的合成数据集上训练模型,可以达到与在原始数据集上训练模型相当的性能。为了进一步提高合成数据集的性能,研究者们提出了各种训练流程和优化目标,极大地推动了数据集蒸馏领域的发展。最近解耦的数据集蒸馏方法在后评估阶段引入了软标签和更强的数据增强,并将数据集蒸馏扩展到更大的数据集(例如,ImageNet-1K)。然而,这引发了一个问题:准确率仍然是公平评估数据集蒸馏方法的可靠指标吗?我们的经验结果表明,这些方法的性能改进通常源于额外的技术,而不是图像本身的内在质量,甚至随机采样的图像也能取得更好的结果。这种错位的评估设置严重阻碍了数据集蒸馏的发展。因此,我们提出了DD-Ranking,一个统一的评估框架,以及新的通用评估指标,以揭示不同方法所实现的真正性能改进。通过重新关注蒸馏数据集的实际信息增强,DD-Ranking为未来的研究进展提供了一个更全面和公平的评估标准。
🔬 方法详解
问题定义:数据集蒸馏旨在通过生成一个远小于原始数据集的合成数据集,使得在该合成数据集上训练的模型能够达到与在原始数据集上训练的模型相近的性能。然而,现有的评估方法主要依赖于准确率,并且容易受到后评估阶段引入的软标签、数据增强等额外技术的影响,导致评估结果无法真实反映数据集蒸馏方法的优劣。现有方法的痛点在于无法区分性能提升是源于蒸馏数据集本身的质量,还是源于额外的训练技巧。
核心思路:DD-Ranking 的核心思路是重新聚焦于蒸馏数据集本身的信息增强能力,而不是仅仅关注最终的准确率。通过设计新的评估指标和统一的评估框架,DD-Ranking 旨在更准确地衡量蒸馏数据集的质量,从而为数据集蒸馏方法提供更公平的评估标准。这样设计的目的是为了避免评估结果受到与数据集本身质量无关的因素的干扰。
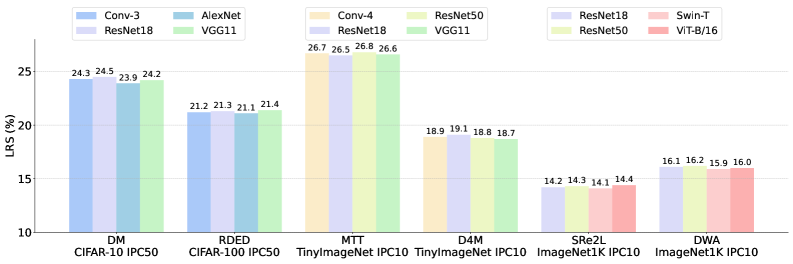
技术框架:DD-Ranking 包含以下主要组成部分: 1. 统一的评估流程:定义了一套标准化的评估流程,确保所有数据集蒸馏方法都在相同的条件下进行评估。 2. 新的评估指标:提出了新的评估指标,例如衡量蒸馏数据集信息量的指标,以及衡量蒸馏数据集泛化能力的指标。 3. 基准数据集和模型:提供了一组基准数据集和模型,用于评估不同数据集蒸馏方法的性能。
关键创新:DD-Ranking 的最重要创新在于其评估理念的转变,即从关注最终的准确率转向关注蒸馏数据集本身的信息增强能力。与现有方法相比,DD-Ranking 能够更准确地衡量数据集蒸馏方法的优劣,避免了评估结果受到额外技术因素的干扰。这种转变使得评估结果更具参考价值,能够更好地指导数据集蒸馏方法的研究和发展。
关键设计:DD-Ranking 的关键设计包括: 1. 信息量评估指标:设计了衡量蒸馏数据集信息量的指标,例如基于熵的指标或基于互信息的指标。 2. 泛化能力评估指标:设计了衡量蒸馏数据集泛化能力的指标,例如基于对抗样本的指标或基于领域泛化的指标。 3. 统一的训练和评估流程:定义了统一的训练和评估流程,包括数据预处理、模型训练、性能评估等步骤,确保所有数据集蒸馏方法都在相同的条件下进行评估。
🖼️ 关键图片

📊 实验亮点
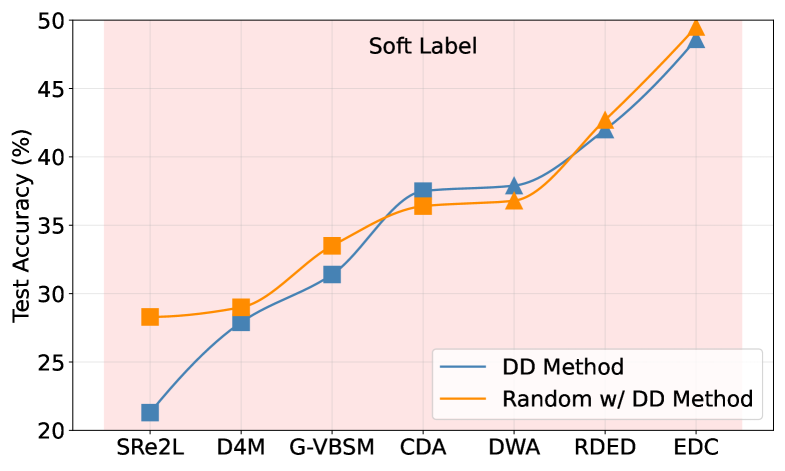
实验结果表明,使用 DD-Ranking 评估时,一些原本在传统准确率指标下表现良好的数据集蒸馏方法,其真实性能被高估。而另一些更注重信息保留的方法,则在 DD-Ranking 的评估下表现出更优越的性能。DD-Ranking 能够更有效地揭示不同数据集蒸馏方法的真实性能差异,为未来的研究提供更可靠的评估标准。
🎯 应用场景
DD-Ranking 可应用于数据集蒸馏算法的公平评估与性能提升,帮助研究者更准确地衡量不同蒸馏方法的优劣,从而推动数据压缩和模型加速技术的发展。该框架还可用于指导合成数据集的设计,提高其信息含量和泛化能力,在资源受限场景下具有重要应用价值,例如移动设备上的模型部署和边缘计算。
📄 摘要(原文)
In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.