Single Image Reflection Separation via Dual Prior Interaction Transformer
作者: Yue Huang, Zi'ang Li, Tianle Hu, Jie Wen, Guanbin Li, Jinglin Zhang, Guoxu Zhou, Xiaozhao Fang
分类: cs.CV, cs.AI
发布日期: 2025-05-19 (更新: 2026-01-08)
💡 一句话要点
提出双重先验交互Transformer,有效分离单幅图像中的反射和透射层
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 单图反射分离 透射先验 双重先验交互 Transformer 图像处理
📋 核心要点
- 现有单图反射分离方法未能有效建模和利用透射先验,导致复杂场景下性能受限。
- 提出双重先验交互框架,通过LLCN生成高质量透射先验,并用DPIT实现深度融合。
- 实验结果表明,该方法在多个基准数据集上取得了state-of-the-art的性能。
📝 摘要(中文)
单幅图像反射分离旨在从混合图像中分离出透射层和反射层。现有方法通常将预训练模型中的通用先验与任务特定的先验(如文本提示和反射检测)相结合。然而,透射先验作为目标透射层最直接的任务特定先验,尚未得到有效建模或充分利用,限制了在复杂场景中的性能。为了解决这个问题,我们提出了一种基于轻量级透射先验生成和有效先验融合的双重先验交互框架。首先,我们设计了一个局部线性校正网络(LLCN),该网络基于物理约束T=SI+B对预训练模型进行微调,其中S和B表示像素级和通道级的缩放和偏差变换。LLCN以最少的参数高效地生成高质量的透射先验。其次,我们构建了一个双重先验交互Transformer(DPIT),它采用双流通道重组注意力机制。通过重组来自通用先验和透射先验的特征以进行注意力计算,DPIT实现了两种先验的深度融合,充分利用了它们的互补信息。在多个基准数据集上的实验结果表明,该方法达到了最先进的性能。
🔬 方法详解
问题定义:单幅图像反射分离旨在将混合图像分解为透射层和反射层。现有方法主要依赖预训练模型的通用先验和一些任务特定的先验(如文本提示、反射检测等),但忽略了透射层本身所蕴含的直接先验信息,导致在复杂场景下分离效果不佳。现有方法未能充分利用透射先验,限制了性能的提升。
核心思路:论文的核心思路是充分挖掘并有效利用透射先验。通过设计轻量级的透射先验生成模块,并结合双重先验交互Transformer,实现通用先验和透射先验的深度融合,从而提升反射分离的性能。这样设计的目的是为了更直接地利用目标透射层的信息,弥补现有方法的不足。
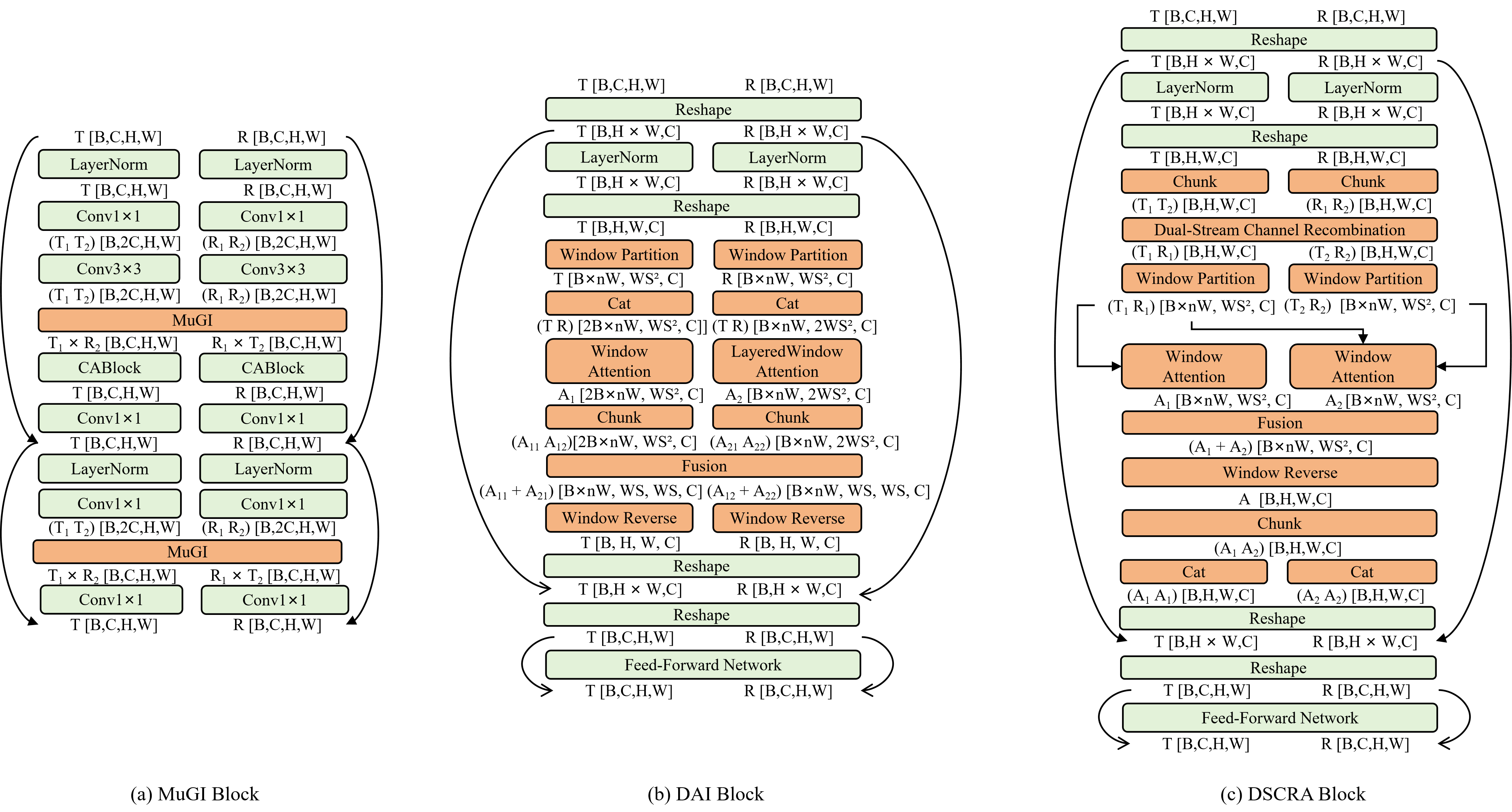
技术框架:整体框架包含两个主要模块:局部线性校正网络(LLCN)和双重先验交互Transformer(DPIT)。首先,LLCN基于物理约束T=SI+B,对预训练模型进行微调,生成高质量的透射先验。然后,DPIT采用双流结构,分别处理通用先验和透射先验,并通过通道重组注意力机制实现两种先验的深度融合。
关键创新:论文的关键创新在于提出了双重先验交互Transformer(DPIT),它通过双流通道重组注意力机制,实现了通用先验和透射先验的深度融合。与现有方法相比,DPIT能够更有效地利用透射先验,从而提升反射分离的性能。此外,LLCN的设计也保证了高效的透射先验生成。
关键设计:LLCN基于物理约束T=SI+B,通过学习像素级和通道级的缩放和偏差变换S和B,对预训练模型进行微调。DPIT采用双流结构,每个流处理一种先验,并通过通道重组注意力机制进行交互。注意力机制的设计允许网络自适应地学习不同通道的重要性,从而实现更有效的特征融合。损失函数方面,具体细节未知。
🖼️ 关键图片


📊 实验亮点
论文提出的方法在多个基准数据集上取得了state-of-the-art的性能,表明了该方法的有效性。具体的性能数据和对比基线未知,但摘要明确指出优于现有方法。LLCN以最少的参数高效地生成高质量的透射先验,DPIT实现了两种先验的深度融合,充分利用了它们的互补信息。
🎯 应用场景
该研究成果可应用于图像编辑、视频处理、计算机视觉等领域。例如,可以用于去除照片或视频中的反射,提高图像质量;也可以应用于增强现实和虚拟现实等领域,提高用户体验。此外,该技术还可以应用于智能监控、自动驾驶等领域,提高系统的感知能力。
📄 摘要(原文)
Single image reflection separation aims to separate the transmission and reflection layers from a mixed image. Existing methods typically combine general priors from pre-trained models with task-specific priors such as text prompts and reflection detection. However, the transmission prior, as the most direct task-specific prior for the target transmission layer, has not been effectively modeled or fully utilized, limiting performance in complex scenarios. To address this issue, we propose a dual-prior interaction framework based on lightweight transmission prior generation and effective prior fusion. First, we design a Local Linear Correction Network (LLCN) that finetunes pre-trained models based on the physical constraint T=SI+B, where S and B represent pixel-wise and channel-wise scaling and bias transformations. LLCN efficiently generates high-quality transmission priors with minimal parameters. Second, we construct a Dual-Prior Interaction Transformer (DPIT) that employs a dual-stream channel reorganization attention mechanism. By reorganizing features from general and transmission priors for attention computation, DPIT achieves deep fusion of both priors, fully exploiting their complementary information. Experimental results on multiple benchmark datasets demonstrate that the proposed method achieves state-of-the-art performance.