Towards Visuospatial Cognition via Hierarchical Fusion of Visual Experts
作者: Qi Feng
分类: cs.CV, cs.AI, cs.CL, cs.LG, cs.RO
发布日期: 2025-05-18 (更新: 2025-09-09)
备注: 26 pages, 19 figures, 4 tables
💡 一句话要点
ViCA2:通过视觉专家分层融合增强多模态大语言模型中的视觉空间认知
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉空间认知 多模态大语言模型 视觉专家融合 空间推理 指令调优
📋 核心要点
- 现有多模态大语言模型在视觉空间认知方面存在不足,难以进行精细的空间理解和推理。
- ViCA2通过双视觉编码器架构,融合SigLIP的语义信息和Hiera的空间结构,提升空间推理能力。
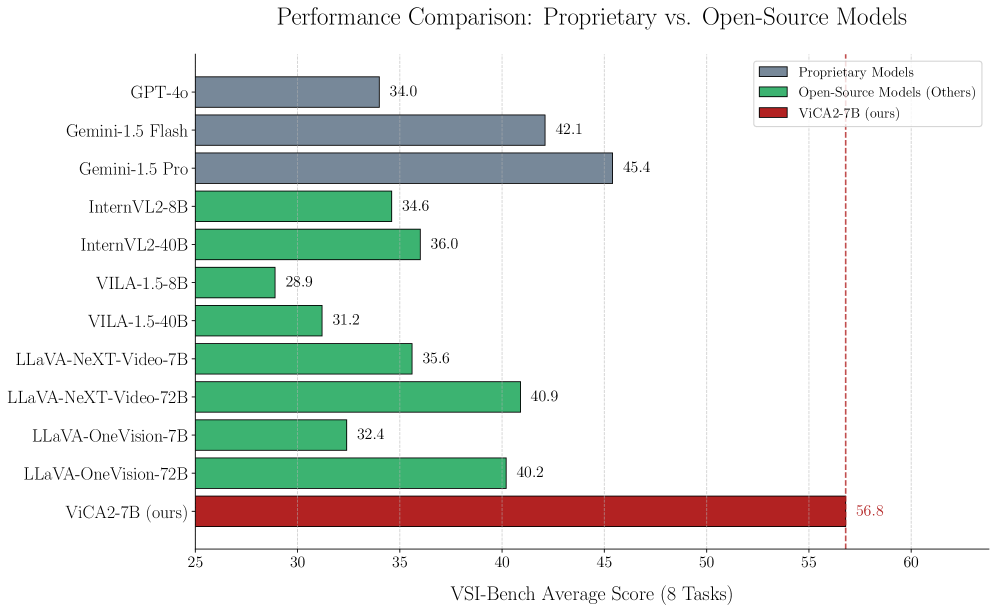
- ViCA2-7B在VSI-Bench上取得了显著的性能提升,超越了更大的开源和专有模型,证明了其有效性。
📝 摘要(中文)
多模态大语言模型(MLLM)在通用视觉-语言任务中表现出色,但视觉空间认知——对空间布局、关系和动态的推理——仍然是一个重大挑战。现有的模型通常缺乏必要的架构组件和专门的训练数据来进行精细的空间理解。我们引入了ViCA2(Visuospatial Cognitive Assistant 2),这是一种旨在增强空间推理的新型MLLM。ViCA2具有双视觉编码器架构,集成了用于语义的SigLIP和用于空间结构的Hiera,并结合了用于效率的token比例控制机制。我们还开发了ViCA-322K,这是一个新的大规模数据集,包含超过322,000个空间相关的问答对,用于有针对性的指令调优。在具有挑战性的VSI-Bench基准测试中,我们的ViCA2-7B模型实现了56.8的state-of-the-art平均分,显著超过了更大的开源模型(例如,LLaVA-NeXT-Video-72B,40.9)和领先的专有模型(Gemini-1.5 Pro,45.4)。这证明了我们的方法在以紧凑的模型实现强大的视觉空间智能方面的有效性。我们发布ViCA2、其代码库和ViCA-322K数据集,以促进进一步的研究。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型在视觉空间认知方面的不足,即模型难以准确理解和推理图像中的空间布局、关系和动态。现有方法通常缺乏专门的架构和训练数据,导致在精细空间理解方面表现不佳。
核心思路:论文的核心思路是通过融合来自不同视觉专家的信息来增强模型的空间推理能力。具体来说,利用SigLIP提取图像的语义信息,利用Hiera提取图像的空间结构信息,并将两者融合,从而使模型能够更全面地理解图像内容。
技术框架:ViCA2的整体架构包括一个双视觉编码器和一个语言模型。双视觉编码器由SigLIP和Hiera组成,分别提取图像的语义和空间特征。这些特征被融合后输入到语言模型中,用于生成答案。此外,还引入了token比例控制机制,以提高模型的效率。
关键创新:该论文的关键创新在于双视觉编码器架构,它能够有效地融合语义和空间信息,从而显著提升模型的视觉空间认知能力。此外,ViCA-322K数据集的构建也为模型的训练提供了高质量的空间相关数据。
关键设计:ViCA2使用了SigLIP和Hiera作为视觉编码器,这两种模型分别擅长提取语义和空间特征。Token比例控制机制用于平衡不同视觉编码器的贡献,以优化模型的性能。ViCA-322K数据集包含了多种空间相关的问答对,用于训练模型进行空间推理。
🖼️ 关键图片


📊 实验亮点
ViCA2-7B在VSI-Bench基准测试中取得了56.8的平均分,显著超越了LLaVA-NeXT-Video-72B (40.9) 和 Gemini-1.5 Pro (45.4)。这表明ViCA2在视觉空间认知方面具有显著的优势,并且能够以更小的模型尺寸实现更高的性能。
🎯 应用场景
ViCA2在机器人导航、自动驾驶、智能家居等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,ViCA2可以用于识别交通标志、行人和其他车辆,从而提高驾驶安全性。在智能家居领域,ViCA2可以用于理解用户的指令,并控制家电设备。
📄 摘要(原文)
While Multimodal Large Language Models (MLLMs) excel at general vision-language tasks, visuospatial cognition - reasoning about spatial layouts, relations, and dynamics - remains a significant challenge. Existing models often lack the necessary architectural components and specialized training data for fine-grained spatial understanding. We introduce ViCA2 (Visuospatial Cognitive Assistant 2), a novel MLLM designed to enhance spatial reasoning. ViCA2 features a dual vision encoder architecture integrating SigLIP for semantics and Hiera for spatial structure, coupled with a token ratio control mechanism for efficiency. We also developed ViCA-322K, a new large-scale dataset with over 322,000 spatially grounded question-answer pairs for targeted instruction tuning. On the challenging VSI-Bench benchmark, our ViCA2-7B model achieves a state-of-the-art average score of 56.8, significantly surpassing larger open-source models (e.g., LLaVA-NeXT-Video-72B, 40.9) and leading proprietary models (Gemini-1.5 Pro, 45.4). This demonstrates the effectiveness of our approach in achieving strong visuospatial intelligence with a compact model. We release ViCA2, its codebase, and the ViCA-322K dataset to facilitate further research.