Visuospatial Cognitive Assistant
作者: Qi Feng
分类: cs.CV, cs.AI, cs.CL, cs.LG, cs.RO
发布日期: 2025-05-18 (更新: 2025-09-09)
备注: 31 pages, 10 figures, 6 tables
💡 一句话要点
提出ViCA-322K数据集和ViCA-7B模型,提升具身AI在视频空间认知任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉空间认知 视频理解 具身AI 数据集构建 视觉-语言模型
📋 核心要点
- 现有视觉-语言模型在处理机器人和具身AI所需的视频空间认知任务时,面临着缺乏针对性和高质量训练数据的挑战。
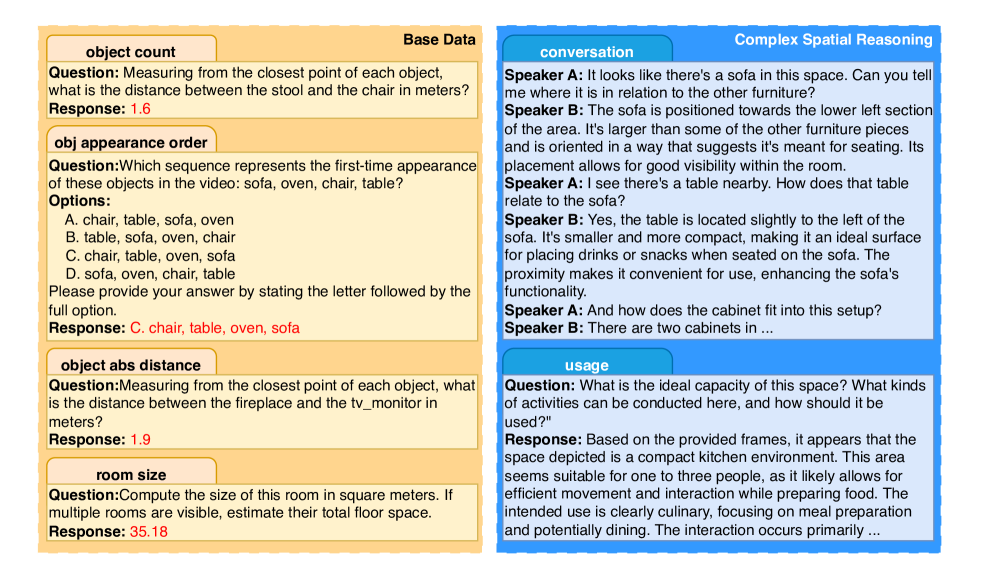
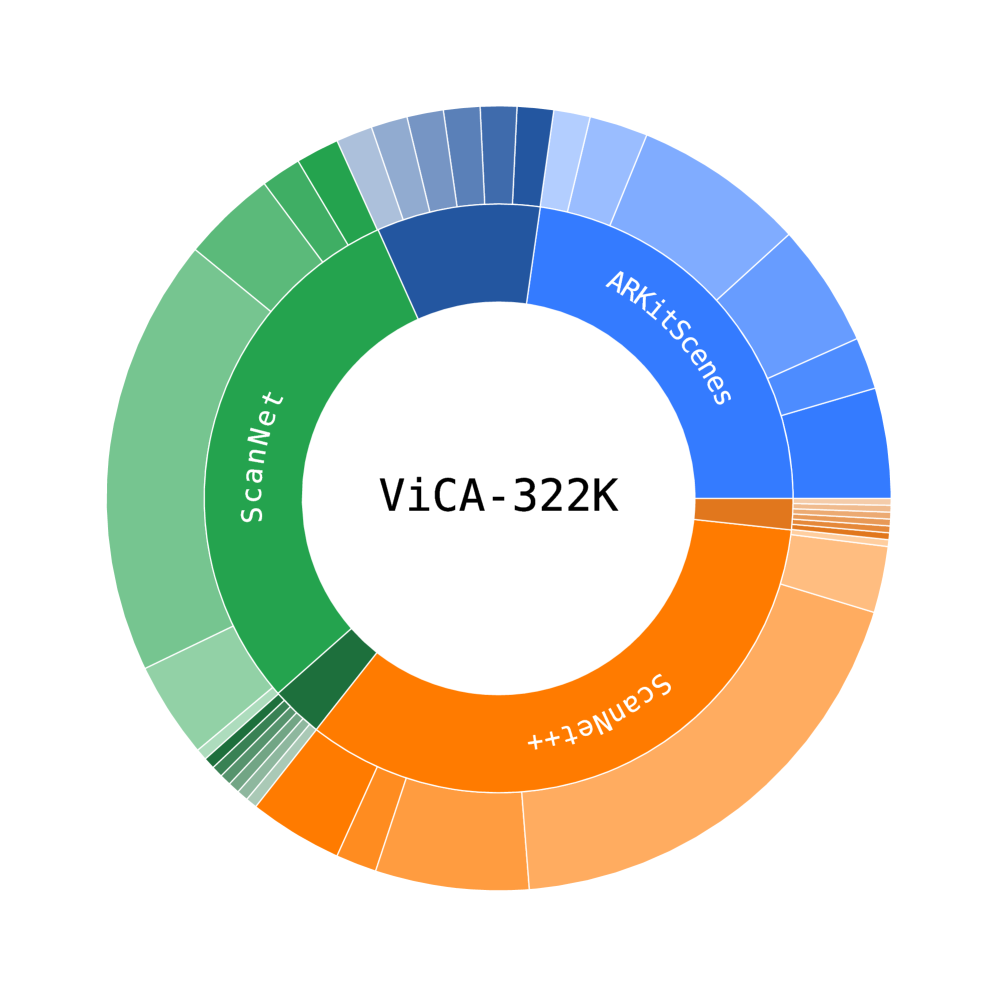
- 论文提出ViCA-322K数据集,包含大量真实室内场景视频的问答对,并设计ViCA-7B模型,通过微调提升模型在空间推理方面的能力。
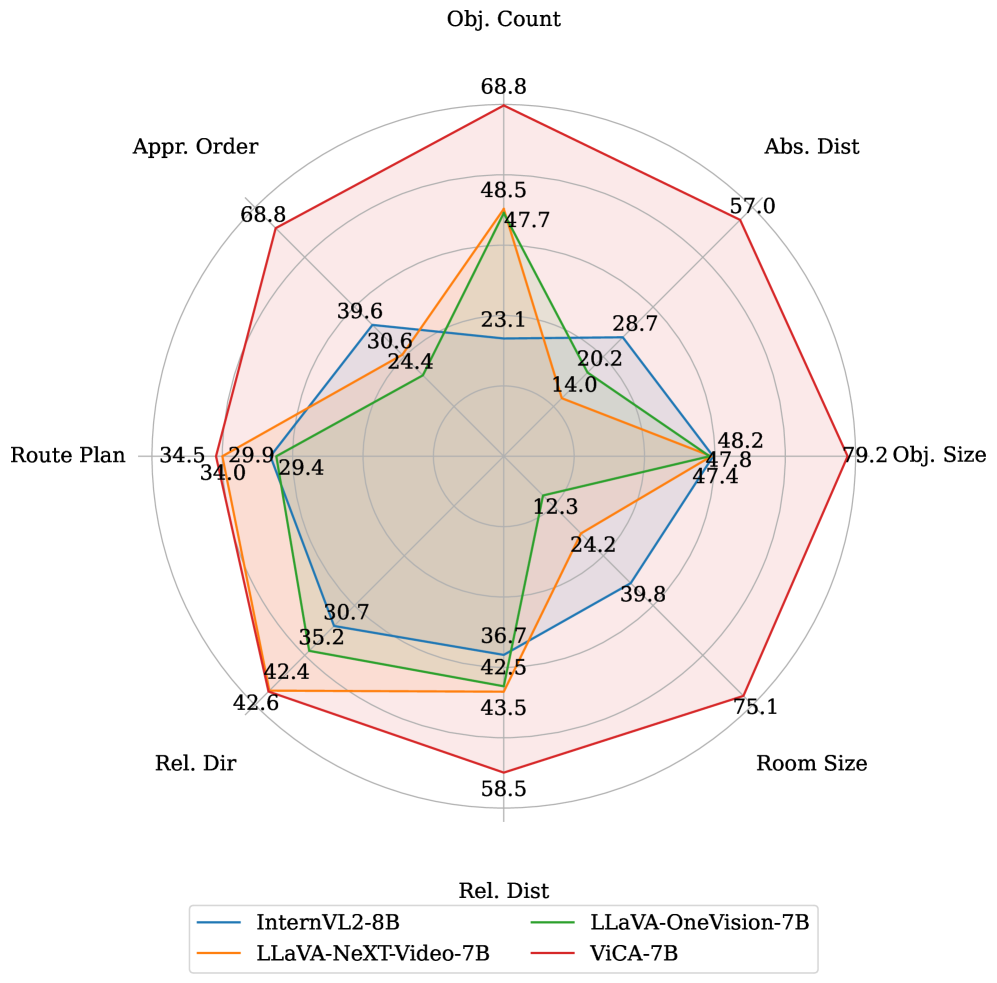
- 实验结果表明,ViCA-7B在VSI-Bench基准测试中显著优于现有模型,并在绝对距离等指标上取得了大幅提升,证明了方法的有效性。
📝 摘要(中文)
本文针对机器人和具身AI中基于视频的空间认知问题,现有视觉-语言模型(VLM)难以胜任这一挑战。本文做出了两项关键贡献。首先,我们引入了ViCA (Visuospatial Cognitive Assistant)-322K,一个包含322,003个QA对的多样化数据集,数据来自真实室内视频(ARKitScenes, ScanNet, ScanNet++),为3D元数据相关的查询和基于视频的复杂推理提供监督。其次,我们开发了ViCA-7B,该模型在ViCA-322K上进行了微调,在所有八个VSI-Bench任务上都达到了新的state-of-the-art,超越了包括更大模型在内的现有模型(例如,在绝对距离上+26.1)。为了提高可解释性,我们提出了ViCA-Thinking-2.68K,一个包含显式推理链的数据集,并微调ViCA-7B以创建ViCA-7B-Thinking,一个能够清晰表达其空间推理的模型。我们的工作强调了目标数据的重要性,并为改进时空建模提供了方向。我们发布所有资源,以促进对鲁棒的视觉空间智能的研究。
🔬 方法详解
问题定义:论文旨在解决视觉空间认知问题,即让AI模型能够理解和推理视频中的空间关系,例如物体之间的距离、方位等。现有方法,特别是通用的视觉-语言模型,在处理这种需要精确3D理解和时序推理的任务时表现不佳,主要原因是缺乏针对性的训练数据和模型结构上的不足。
核心思路:论文的核心思路是构建一个专门用于视觉空间认知任务的大规模数据集,并在此基础上微调一个视觉-语言模型。通过这种方式,模型可以学习到更丰富的空间知识和推理能力,从而在相关任务上取得更好的性能。论文还探索了通过引入显式推理链来提高模型的可解释性。
技术框架:整体框架包含两个主要部分:数据集构建和模型训练。ViCA-322K数据集的构建涉及从真实室内视频中提取图像帧,并生成与3D元数据相关的问答对。ViCA-7B模型基于一个预训练的视觉-语言模型,并在ViCA-322K数据集上进行微调。为了提高可解释性,论文还构建了ViCA-Thinking-2.68K数据集,并微调ViCA-7B得到ViCA-7B-Thinking模型。
关键创新:论文的关键创新在于构建了一个大规模、多样化的视觉空间认知数据集ViCA-322K,该数据集包含了丰富的3D元数据和复杂的推理场景。此外,论文还提出了ViCA-7B-Thinking模型,该模型能够通过显式推理链来解释其空间推理过程,从而提高了模型的可解释性。
关键设计:ViCA-322K数据集的设计考虑了室内场景的多样性和复杂性,包含了ARKitScenes、ScanNet和ScanNet++等多个数据集。问答对的生成方式包括基于3D元数据的查询和基于视频的复杂推理。ViCA-7B模型基于一个7B参数的视觉-语言模型,并采用标准的微调方法进行训练。ViCA-7B-Thinking模型的训练则采用了额外的损失函数,鼓励模型生成显式的推理链。
🖼️ 关键图片
📊 实验亮点
ViCA-7B在VSI-Bench基准测试中取得了显著的性能提升,在所有八个任务上都达到了新的state-of-the-art。例如,在绝对距离任务上,ViCA-7B的性能比现有模型提高了26.1%。ViCA-7B-Thinking模型能够生成显式的推理链,提高了模型的可解释性。这些结果表明,针对性的数据和模型设计可以显著提升视觉空间认知能力。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、增强现实等领域。例如,机器人可以利用视觉空间认知能力在复杂环境中自主导航,智能家居系统可以理解用户的空间意图并提供更智能的服务,增强现实应用可以更准确地将虚拟物体与真实场景进行融合。该研究为开发更智能、更具交互性的AI系统奠定了基础。
📄 摘要(原文)
Video-based spatial cognition is vital for robotics and embodied AI but challenges current Vision-Language Models (VLMs). This paper makes two key contributions. First, we introduce ViCA (Visuospatial Cognitive Assistant)-322K, a diverse dataset of 322,003 QA pairs from real-world indoor videos (ARKitScenes, ScanNet, ScanNet++), offering supervision for 3D metadata-grounded queries and video-based complex reasoning. Second, we develop ViCA-7B, fine-tuned on ViCA-322K, which achieves new state-of-the-art on all eight VSI-Bench tasks, outperforming existing models, including larger ones (e.g., +26.1 on Absolute Distance). For interpretability, we present ViCA-Thinking-2.68K, a dataset with explicit reasoning chains, and fine-tune ViCA-7B to create ViCA-7B-Thinking, a model that articulates its spatial reasoning. Our work highlights the importance of targeted data and suggests paths for improved temporal-spatial modeling. We release all resources to foster research in robust visuospatial intelligence.