LogicOCR: Do Your Large Multimodal Models Excel at Logical Reasoning on Text-Rich Images?
作者: Maoyuan Ye, Haibin He, Qihuang Zhong, Jing Zhang, Juhua Liu, Bo Du
分类: cs.CV, cs.CL
发布日期: 2025-05-18 (更新: 2025-11-26)
备注: GitHub: https://github.com/MiliLab/LogicOCR
🔗 代码/项目: GITHUB
💡 一句话要点
提出LogicOCR基准测试,评估大型多模态模型在文本图像上的逻辑推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 逻辑推理 文本图像 基准测试 大型语言模型
📋 核心要点
- 现有大型多模态模型在文本图像上的复杂逻辑推理能力仍有待深入探索,缺乏专门的评估基准。
- 提出LogicOCR基准测试,包含生成图像和真实图像,并设计了多项选择题和自由形式问题,全面评估模型。
- 实验表明,LMMs在多模态推理方面仍有提升空间,并提出TextCue方法,通过增强文本区域感知来提高模型性能。
📝 摘要(中文)
本文提出了LogicOCR,一个包含2780个问题的基准测试,用于评估大型多模态模型(LMMs)在富含文本的图像上的复杂逻辑推理能力。LogicOCR包含两个子集:LogicOCR-Gen,包含1100个基于生成图像的多项选择题;LogicOCR-Real,包含1680个基于真实世界图像精心设计的自由形式问题。LogicOCR-Gen的构建首先从中国国家公务员考试中整理文本语料库,然后定制自动流程引导GPT-Image-1生成具有不同布局和字体的图像,确保上下文相关性和视觉真实感,并进行人工验证。通过在Chain-of-Thought (CoT)和直接回答设置下评估一系列代表性LMMs,揭示了测试时缩放、输入模态差异和视觉文本方向敏感性等关键见解。研究表明,LMMs在多模态推理方面仍然落后于纯文本输入,表明它们尚未完全弥合视觉阅读与推理之间的差距。此外,提出了一种名为TextCue的无训练方法,通过放大包含重要文本线索的图像区域来增强LMMs的感知能力。实验表明,该方法有效,例如,在CoT设置下,LLaVA-OV-1.5-8B的准确率提高了1.8%。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在处理富含文本的图像时,进行复杂逻辑推理能力评估的问题。现有方法缺乏专门的基准测试,难以全面评估LMMs在视觉阅读和逻辑推理相结合任务中的表现。现有方法无法有效衡量模型对图像中关键文本信息的利用程度,以及视觉信息与文本信息融合推理的能力。
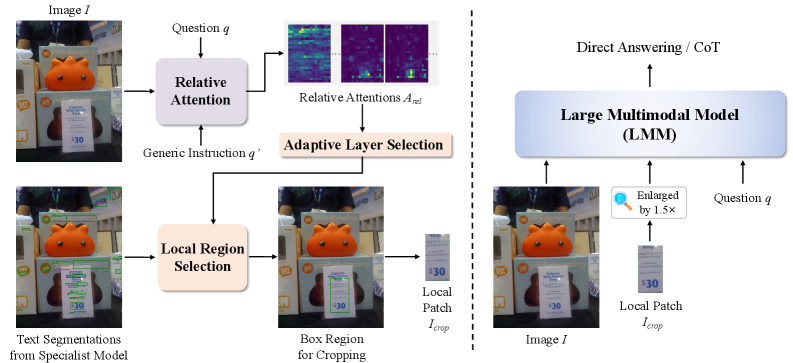
核心思路:论文的核心思路是构建一个高质量、多样化的基准测试数据集LogicOCR,包含生成图像和真实图像,并设计不同类型的题目,以全面评估LMMs在文本图像上的逻辑推理能力。此外,论文还提出了一种名为TextCue的无训练方法,通过突出图像中包含关键文本信息的区域,来增强LMMs的感知能力,从而提高推理性能。
技术框架:LogicOCR基准测试的构建流程包括:1) 文本语料库的整理(来自中国国家公务员考试);2) 使用GPT-Image-1生成图像,并控制图像的布局和字体,确保上下文相关性和视觉真实感;3) 人工验证生成的图像;4) 设计多项选择题和自由形式问题。TextCue方法的流程包括:1) 利用LMMs的注意力图和文本分割模型确定包含重要文本线索的图像区域;2) 裁剪并放大该区域;3) 将放大后的区域与原始图像一起输入LMMs进行推理。
关键创新:论文的关键创新点在于:1) 提出了LogicOCR基准测试,填补了LMMs在文本图像逻辑推理能力评估方面的空白;2) 设计了包含生成图像和真实图像,以及多项选择题和自由形式问题的多样化数据集,更全面地评估LMMs的推理能力;3) 提出了TextCue方法,通过无训练的方式增强LMMs对关键文本区域的感知,提高了推理性能。
关键设计:LogicOCR-Gen的图像生成过程中,使用了GPT-Image-1,并控制了图像的布局和字体,以确保图像的多样性和真实感。TextCue方法中,使用了LMMs的注意力图和现成的文本分割模型来确定包含重要文本线索的图像区域。裁剪和放大区域的比例是关键参数,需要根据具体任务进行调整。没有提及损失函数和网络结构等细节,TextCue是一种训练无关的方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LMMs在多模态推理方面仍然落后于纯文本输入,表明它们尚未完全弥合视觉阅读与推理之间的差距。TextCue方法能够有效提高LMMs的推理性能,例如,在CoT设置下,LLaVA-OV-1.5-8B的准确率提高了1.8%。LogicOCR基准测试为评估和改进LMMs在文本图像上的逻辑推理能力提供了一个有价值的平台。
🎯 应用场景
该研究成果可应用于提升大型多模态模型在处理包含复杂文本信息的图像时的理解和推理能力,例如文档理解、信息抽取、视觉问答等领域。LogicOCR基准测试可以促进相关算法的开发和评估,TextCue方法可以作为一种有效的图像预处理技术,提高现有LMMs的性能。未来可应用于智能文档处理、自动化报告生成、智能客服等场景。
📄 摘要(原文)
Recent advances in Large Multimodal Models (LMMs) have revolutionized their reasoning and Optical Character Recognition (OCR) capabilities. However, their complex logical reasoning performance on text-rich images remains underexplored. To bridge this gap, we introduce LogicOCR, a benchmark comprising 2780 questions with two subsets, i.e., LogicOCR-Gen with 1100 multi-choice questions on generated images, and LogicOCR-Real with 1680 meticulously designed free-form questions on real-world images. For constructing LogicOCR-Gen, we first curate a text corpus from the Chinese National Civil Servant Examination, and customize an automatic pipeline to steer GPT-Image-1 to generate images with varied layouts and fonts, ensuring contextual relevance and visual realism. Then, the generated images are manually verified. We evaluate a range of representative LMMs under Chain-of-Thought (CoT) and direct-answer settings. Our multi-dimensional analysis reveals key insights, such as the impact of test-time scaling, input modality differences, and sensitivity to visual-text orientation. Notably, LMMs still lag in multimodal reasoning compared to text-only inputs, indicating that they have not fully bridged visual reading with reasoning. Moreover, we propose TextCue, a training-free method that enhances LMMs' perception of image regions containing important text cues for solving questions. We leverage LMMs' attention maps and an off-the-shelf text segmentation specialist to determine the region, which is then cropped and enlarged to augment the original image. Experiments show its effectiveness, e.g., a 1.8% accuracy gain over LLaVA-OV-1.5-8B under the CoT setting. Our benchmark is available at https://github.com/MiliLab/LogicOCR.