EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
作者: Ryan Hoque, Peide Huang, David J. Yoon, Mouli Sivapurapu, Jian Zhang
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-05-16 (更新: 2025-08-20)
🔗 代码/项目: GITHUB
💡 一句话要点
EgoDex:基于大规模第一人称视频学习灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧操作 第一人称视角 模仿学习 手部姿态估计 数据集 机器人 计算机视觉
📋 核心要点
- 操作任务的模仿学习面临数据稀缺的挑战,缺乏像自然语言和2D视觉那样的大规模数据集。
- 论文利用Apple Vision Pro收集了EgoDex数据集,包含大量第一人称视角的灵巧操作视频,并配有精确的手部姿态标注。
- 论文在EgoDex上训练了模仿学习策略,并提出了新的评估指标和基准,为该领域的研究提供了有力支持。
📝 摘要(中文)
针对操作任务模仿学习中数据稀缺的问题,本文提出EgoDex,一个迄今为止最大、最具多样性的灵巧人手操作数据集。EgoDex包含829小时的第一人称视角视频,并配有同步记录的3D手部和手指跟踪数据,利用多个校准相机和设备端SLAM技术精确跟踪每根手指的姿态。数据集涵盖了194种不同的桌面任务,包括系鞋带、叠衣服等日常操作行为。此外,本文还在该数据集上训练并系统评估了用于手部轨迹预测的模仿学习策略,并引入了用于衡量该领域进展的指标和基准。通过发布这个大规模数据集,旨在推动机器人、计算机视觉和基础模型领域的发展。EgoDex已公开提供下载。
🔬 方法详解
问题定义:现有操作任务的模仿学习方法受限于数据规模,缺乏大规模、高质量的训练数据。现有的第一人称视角数据集,如Ego4D,缺乏手部姿态标注,且并非专注于物体操作,难以直接用于训练灵巧操作模型。
核心思路:论文的核心思路是构建一个大规模、多样化的第一人称视角灵巧操作数据集,并提供精确的手部姿态标注。通过模仿学习,利用该数据集训练能够预测手部轨迹的操作策略。
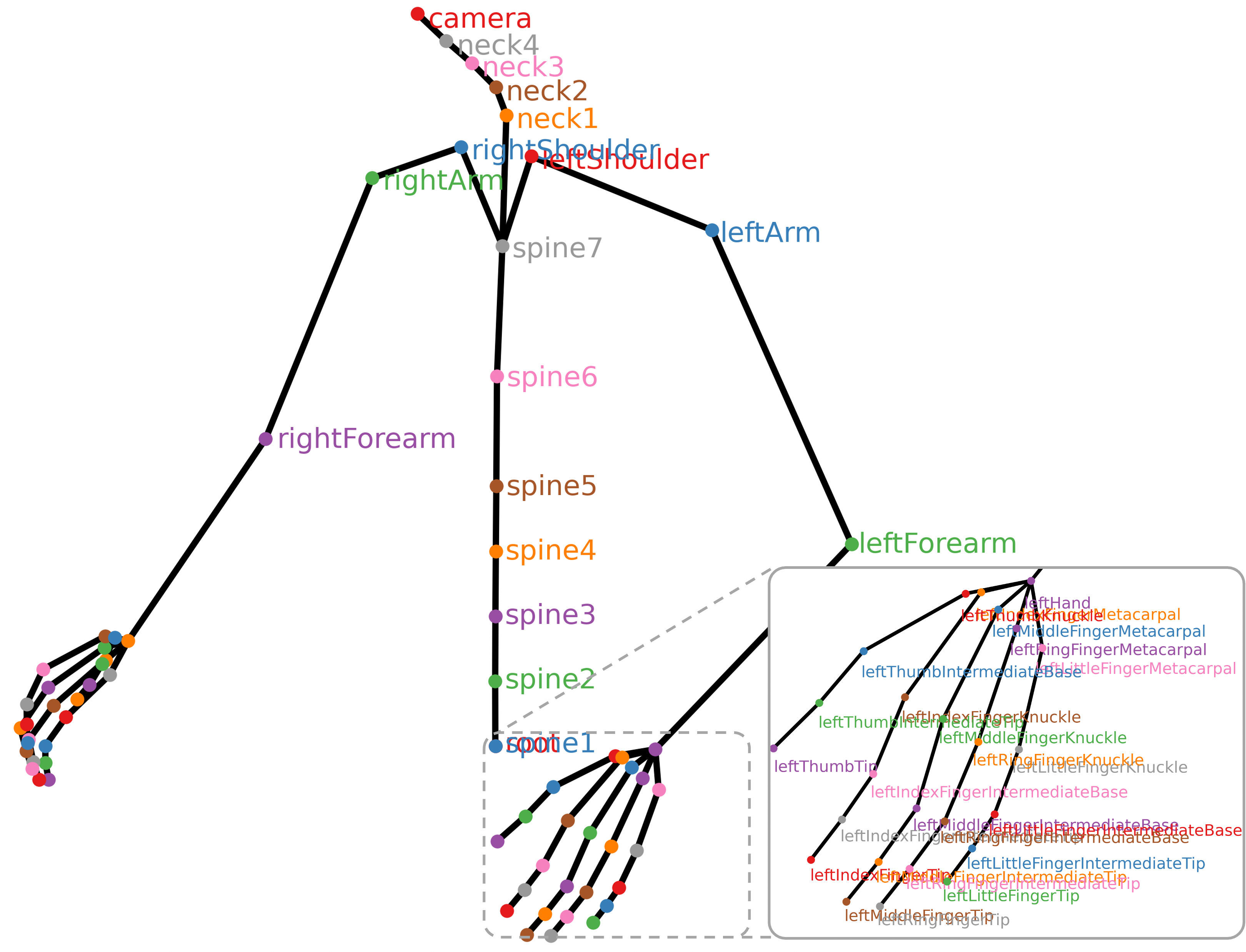
技术框架:EgoDex数据集的构建流程主要包括数据采集和标注两个阶段。数据采集使用Apple Vision Pro,利用其内置的多个校准相机和SLAM技术,同步记录第一人称视角视频和3D手部姿态数据。标注过程依赖于设备端SLAM的精确跟踪结果,无需额外的人工标注。论文还基于该数据集,训练并评估了模仿学习模型,用于手部轨迹预测。
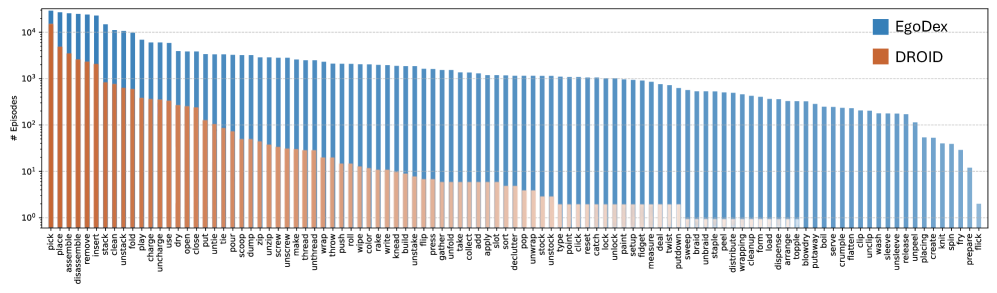
关键创新:EgoDex数据集是目前规模最大、多样性最高的灵巧操作数据集,其创新之处在于:1) 数据规模大,包含829小时的视频;2) 数据多样性高,涵盖194种不同的桌面任务;3) 提供精确的3D手部姿态标注,无需额外的人工标注。
关键设计:在数据采集方面,使用了Apple Vision Pro,保证了数据质量和标注精度。在模仿学习模型训练方面,论文采用了标准的手部轨迹预测模型,并设计了新的评估指标和基准,用于衡量模型在灵巧操作任务上的性能。
🖼️ 关键图片

📊 实验亮点
论文在EgoDex数据集上进行了手部轨迹预测的模仿学习实验,并提出了新的评估指标和基准。实验结果表明,基于EgoDex训练的模型能够有效地预测手部轨迹,并在多个任务上取得了良好的性能。该数据集和基准的发布,将有助于推动灵巧操作领域的研究进展。
🎯 应用场景
EgoDex数据集可广泛应用于机器人灵巧操作、虚拟现实/增强现实人机交互、手势识别等领域。通过学习人类的灵巧操作技能,机器人可以更好地完成各种复杂任务,例如装配、维修、医疗等。该数据集也有助于提升VR/AR环境中人机交互的自然性和流畅性,并为手势识别算法提供更丰富的训练数据。
📄 摘要(原文)
Imitation learning for manipulation has a well-known data scarcity problem. Unlike natural language and 2D computer vision, there is no Internet-scale corpus of data for dexterous manipulation. One appealing option is egocentric human video, a passively scalable data source. However, existing large-scale datasets such as Ego4D do not have native hand pose annotations and do not focus on object manipulation. To this end, we use Apple Vision Pro to collect EgoDex: the largest and most diverse dataset of dexterous human manipulation to date. EgoDex has 829 hours of egocentric video with paired 3D hand and finger tracking data collected at the time of recording, where multiple calibrated cameras and on-device SLAM can be used to precisely track the pose of every joint of each hand. The dataset covers a wide range of diverse manipulation behaviors with everyday household objects in 194 different tabletop tasks ranging from tying shoelaces to folding laundry. Furthermore, we train and systematically evaluate imitation learning policies for hand trajectory prediction on the dataset, introducing metrics and benchmarks for measuring progress in this increasingly important area. By releasing this large-scale dataset, we hope to push the frontier of robotics, computer vision, and foundation models. EgoDex is publicly available for download at https://github.com/apple/ml-egodex.