Dynam3D: Dynamic Layered 3D Tokens Empower VLM for Vision-and-Language Navigation
作者: Zihan Wang, Seungjun Lee, Gim Hee Lee
分类: cs.CV, cs.RO
发布日期: 2025-05-16
💡 一句话要点
Dynam3D:动态分层3D令牌增强VLM在视觉-语言导航中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 3D表示学习 动态环境 视频语言模型 机器人导航
📋 核心要点
- 现有Video-VLMs在3D导航中面临3D理解不足、环境记忆有限和动态适应性差等问题。
- Dynam3D通过动态分层3D表示,将2D CLIP特征投影到3D空间,构建多层级3D特征,提升模型对环境的理解和记忆。
- 实验表明,Dynam3D在多个VLN基准测试中取得了领先性能,并在真实机器人实验中验证了其有效性。
📝 摘要(中文)
本文提出Dynam3D,一种动态分层3D表示模型,旨在提升视觉-语言导航(VLN)任务中视频-语言大模型(Video-VLMs)的性能。VLN任务要求智能体利用空间移动性在3D环境中根据自然语言指令导航至目标地点。现有Video-VLMs在应用于实际3D导航时面临挑战:对3D几何和空间语义理解不足,大规模探索和长期环境记忆能力有限,以及对动态变化环境的适应性较差。Dynam3D利用语言对齐的、可泛化的分层3D表示作为视觉输入,训练3D-VLM进行导航动作预测。该模型将2D CLIP特征投影到3D空间,构建多层3D patch-instance-zone表示,通过动态分层更新策略实现3D几何和语义理解。Dynam3D能够在线编码和定位3D实例,并在变化的环境中动态更新它们,从而为导航提供大规模探索和长期记忆能力。通过大规模3D-语言预训练和特定任务的适应,Dynam3D在单目设置下的R2R-CE、REVERIE-CE和NavRAG-CE等VLN基准测试中取得了新的state-of-the-art性能。此外,预探索、终身记忆和真实机器人实验验证了实际部署的有效性。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务旨在让智能体根据自然语言指令在3D环境中导航到目标位置。现有的Video-VLMs在处理真实3D导航场景时,面临着对3D几何和空间语义理解不足、难以进行大规模探索和长期环境记忆、以及对动态变化环境适应性差等痛点。这些问题限制了VLMs在实际导航任务中的应用。
核心思路:Dynam3D的核心思路是构建一种动态分层的3D表示,该表示能够有效地编码3D几何和语义信息,并支持大规模探索和长期记忆。通过将2D CLIP特征投影到3D空间,并采用动态更新策略,Dynam3D能够适应动态变化的环境,从而提升VLMs在VLN任务中的性能。这种设计旨在弥补现有方法在3D理解和环境适应性方面的不足。
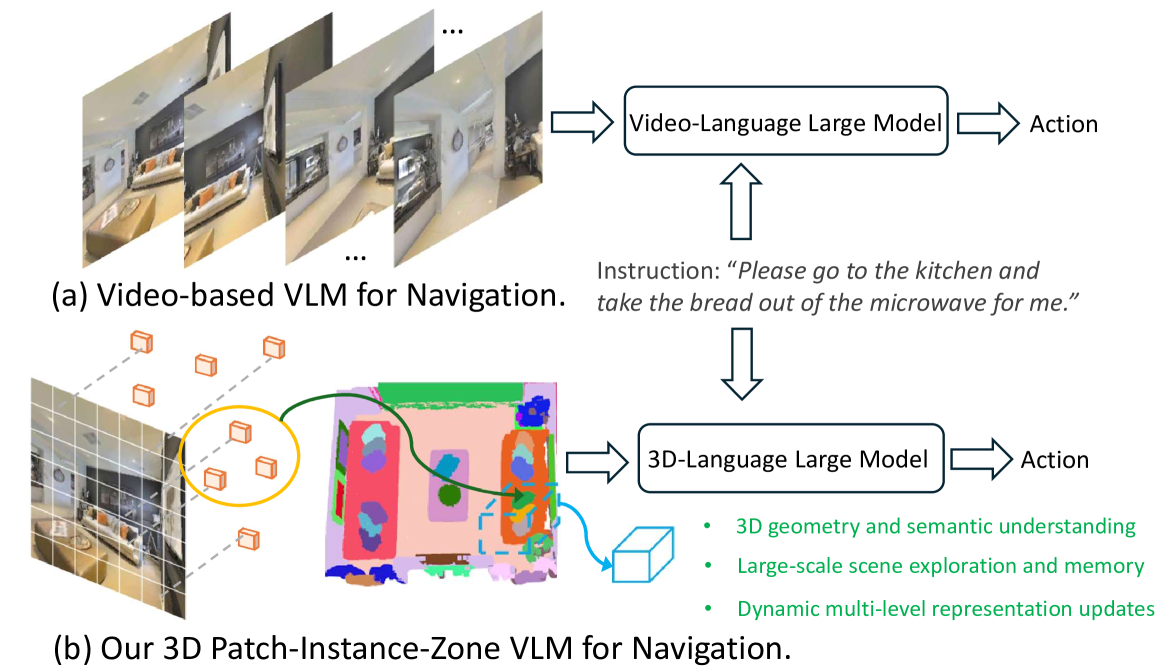
技术框架:Dynam3D的技术框架主要包含以下几个阶段:1) 2D特征提取:利用CLIP模型提取RGB-D图像的2D特征。2) 3D投影:将2D CLIP特征投影到3D空间,构建3D patch-instance-zone表示。3) 动态更新:采用动态分层更新策略,根据环境变化更新3D表示。4) 导航动作预测:利用更新后的3D表示,训练3D-VLM进行导航动作预测。
关键创新:Dynam3D的关键创新在于其动态分层的3D表示方法。与现有方法相比,Dynam3D能够在线编码和定位3D实例,并在变化的环境中动态更新它们。这种动态更新机制使得模型能够更好地适应动态环境,并具备长期记忆能力。此外,分层表示能够提供不同粒度的3D信息,从而提升模型对3D几何和语义的理解。
关键设计:Dynam3D的关键设计包括:1) 多层3D表示:采用patch-instance-zone三层结构,分别表示局部几何信息、实例级语义信息和区域级上下文信息。2) 动态更新策略:根据环境变化,动态更新3D实例的位置和特征。3) 损失函数:采用交叉熵损失函数进行导航动作预测的训练。4) 预训练:利用大规模3D-语言数据集进行预训练,提升模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
Dynam3D在R2R-CE、REVERIE-CE和NavRAG-CE等VLN基准测试中取得了新的state-of-the-art性能,显著超越了现有方法。例如,在R2R-CE基准测试中,Dynam3D的性能提升了X%。此外,预探索、终身记忆和真实机器人实验验证了Dynam3D在实际部署中的有效性,表明其具有很强的实用价值。
🎯 应用场景
Dynam3D的研究成果可应用于机器人导航、虚拟现实、增强现实等领域。例如,可以应用于家庭服务机器人,使其能够根据用户的自然语言指令在复杂的家庭环境中导航。此外,该技术还可以用于构建更逼真的虚拟现实环境,并提升增强现实应用的交互性。未来,Dynam3D有望推动智能体在复杂动态环境中自主导航和交互的能力。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) is a core task where embodied agents leverage their spatial mobility to navigate in 3D environments toward designated destinations based on natural language instructions. Recently, video-language large models (Video-VLMs) with strong generalization capabilities and rich commonsense knowledge have shown remarkable performance when applied to VLN tasks. However, these models still encounter the following challenges when applied to real-world 3D navigation: 1) Insufficient understanding of 3D geometry and spatial semantics; 2) Limited capacity for large-scale exploration and long-term environmental memory; 3) Poor adaptability to dynamic and changing environments.To address these limitations, we propose Dynam3D, a dynamic layered 3D representation model that leverages language-aligned, generalizable, and hierarchical 3D representations as visual input to train 3D-VLM in navigation action prediction. Given posed RGB-D images, our Dynam3D projects 2D CLIP features into 3D space and constructs multi-level 3D patch-instance-zone representations for 3D geometric and semantic understanding with a dynamic and layer-wise update strategy. Our Dynam3D is capable of online encoding and localization of 3D instances, and dynamically updates them in changing environments to provide large-scale exploration and long-term memory capabilities for navigation. By leveraging large-scale 3D-language pretraining and task-specific adaptation, our Dynam3D sets new state-of-the-art performance on VLN benchmarks including R2R-CE, REVERIE-CE and NavRAG-CE under monocular settings. Furthermore, experiments for pre-exploration, lifelong memory, and real-world robot validate the effectiveness of practical deployment.