Denoising and Alignment: Rethinking Domain Generalization for Multimodal Face Anti-Spoofing
作者: Yingjie Ma, Xun Lin, Zitong Yu, Xin Liu, Xiaochen Yuan, Weicheng Xie, Linlin Shen
分类: cs.CV
发布日期: 2025-05-14
💡 一句话要点
提出MMDA框架,通过多模态去噪与对齐提升跨域人脸反欺骗泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人脸反欺骗 多模态学习 域泛化 CLIP模型 去噪对齐
📋 核心要点
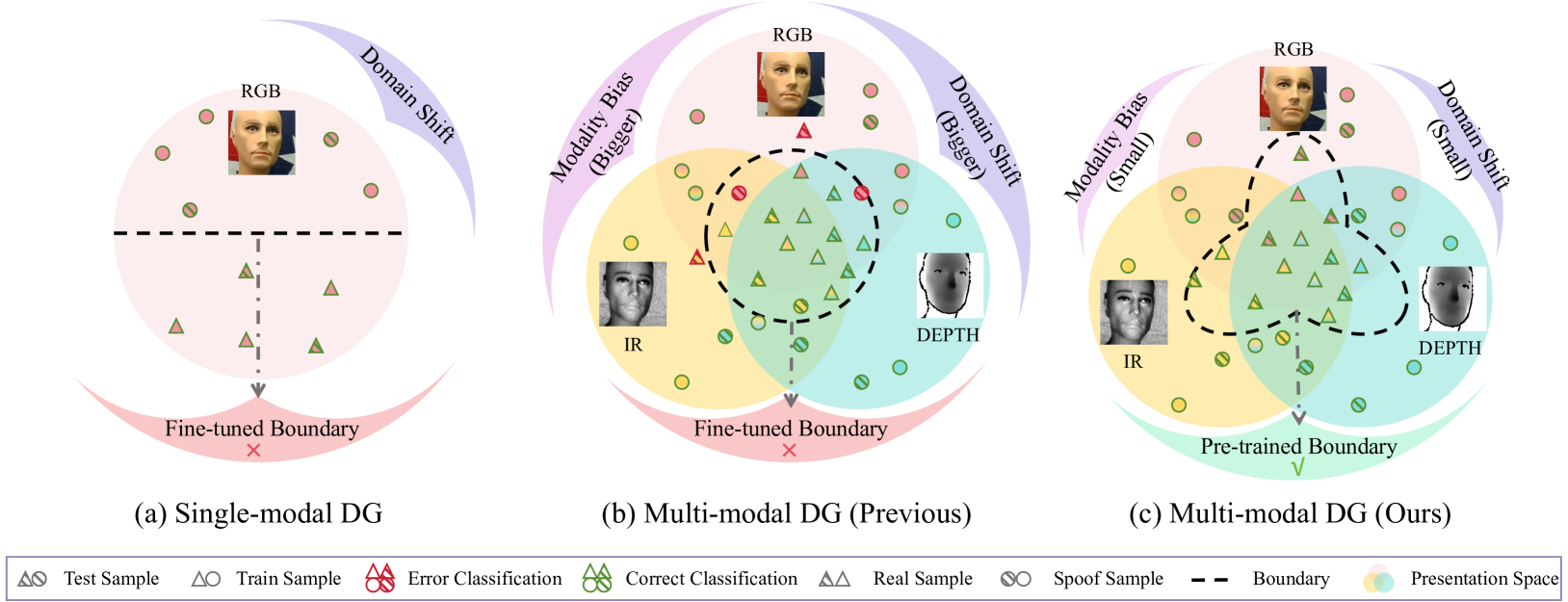
- 现有方法在多模态人脸反欺骗中,受模态特定偏差和域偏移影响,泛化能力不足。
- MMDA框架利用CLIP的零样本能力,通过去噪和对齐机制,抑制噪声并提升跨模态对齐的泛化性。
- 实验表明,MMDA在跨域泛化和多模态检测精度上优于现有方法,证明了其有效性。
📝 摘要(中文)
人脸反欺骗(FAS)对于支付处理和监控等各种场景中面部识别系统的安全性至关重要。当前的多模态FAS方法通常难以有效泛化,这主要是由于模态特定偏差和域偏移。为了应对这些挑战,我们引入了多模态去噪和对齐(MMDA)框架。通过利用CLIP的零样本泛化能力,MMDA框架通过去噪和对齐机制有效地抑制多模态数据中的噪声,从而显著提高跨模态对齐的泛化性能。MMDA中的模态-域联合差分注意力(MD2A)模块通过基于提取的公共噪声特征细化注意力机制,同时减轻域和模态噪声的影响。此外,表示空间软(RS2)对齐策略利用预训练的CLIP模型以灵活的方式将多域多模态数据对齐到广义表示空间中,保留复杂的表示并增强模型对各种未见条件的适应性。我们还设计了一个U型双空间自适应(U-DSA)模块,以增强表示的适应性,同时保持泛化性能。这些改进不仅增强了框架的泛化能力,还提高了其表示复杂表示的能力。在不同评估协议下,在四个基准数据集上的实验结果表明,MMDA框架在跨域泛化和多模态检测精度方面优于现有的最先进方法。代码即将发布。
🔬 方法详解
问题定义:现有的人脸反欺骗(FAS)方法,尤其是在多模态场景下,面临着严重的域泛化问题。由于不同数据集(域)之间存在着显著的差异,以及不同模态(如RGB、深度图、红外图)之间存在着各自的偏差,导致模型在一个域上训练良好,但在未见过的域上表现急剧下降。现有的方法难以有效消除这些模态特定偏差和域偏移,从而限制了模型的实际应用。
核心思路:本文的核心思路是通过去噪和对齐来提升模型的泛化能力。具体来说,利用预训练的CLIP模型的强大零样本泛化能力,将不同域、不同模态的数据映射到一个统一的、更具鲁棒性的表示空间中。通过去噪操作,减少模态特定噪声和域噪声的影响;通过对齐操作,使得不同模态和不同域的数据在表示空间中更加接近,从而提高模型的泛化性能。这样设计的目的是为了让模型能够学习到与域无关、模态无关的本质特征,从而更好地适应未见过的场景。
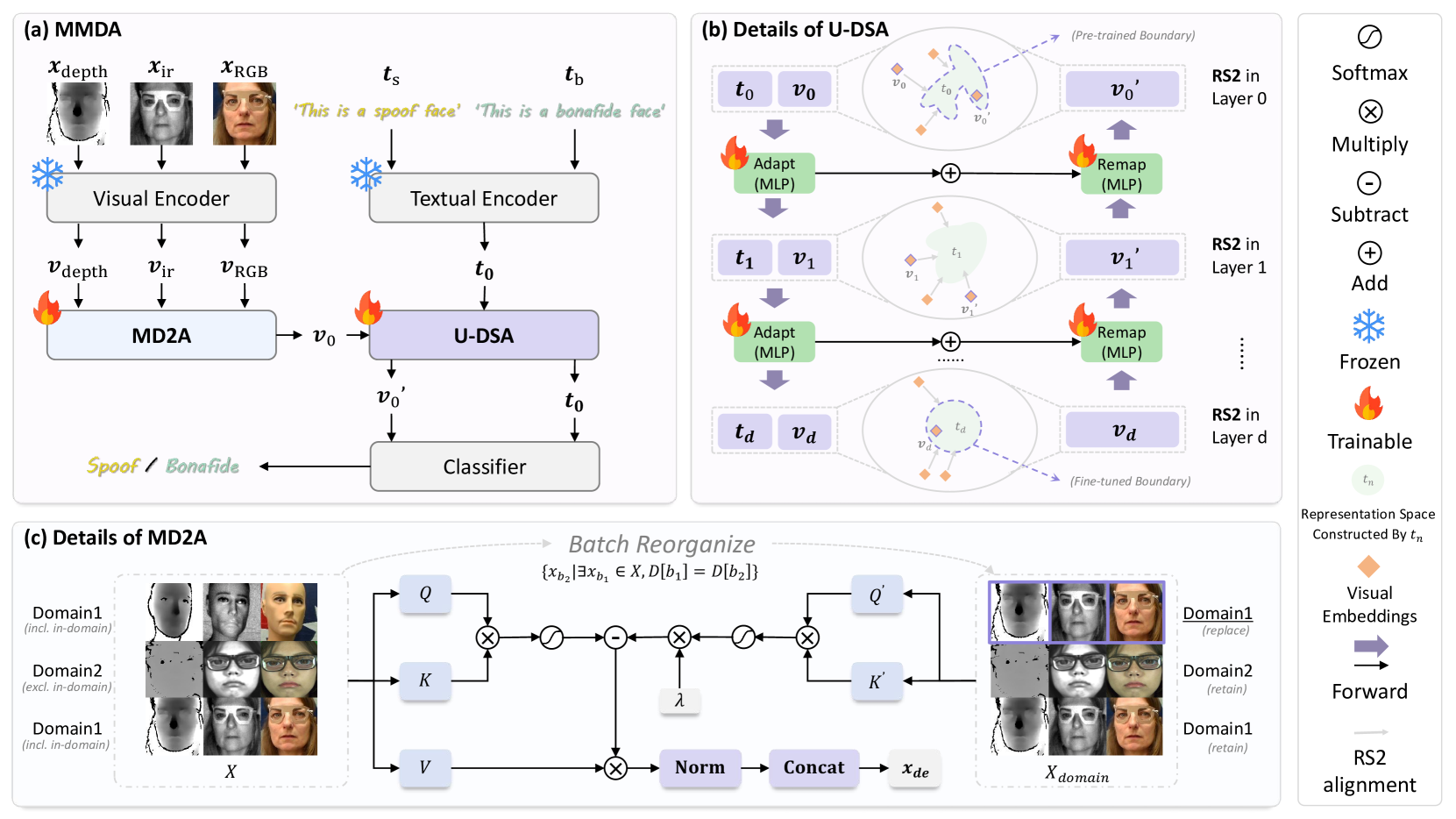
技术框架:MMDA框架主要包含三个核心模块:模态-域联合差分注意力(MD2A)模块、表示空间软(RS2)对齐策略和U型双空间自适应(U-DSA)模块。首先,MD2A模块用于同时减轻域和模态噪声的影响,通过提取公共噪声特征并细化注意力机制来实现。其次,RS2对齐策略利用预训练的CLIP模型,将多域多模态数据对齐到广义表示空间中。最后,U-DSA模块增强表示的适应性,同时保持泛化性能。整体流程是,输入多模态数据,经过MD2A模块进行去噪,然后通过RS2对齐策略进行特征对齐,最后通过U-DSA模块进行特征自适应,最终得到用于反欺骗判别的特征表示。
关键创新:该论文的关键创新在于将CLIP模型的零样本泛化能力引入到多模态人脸反欺骗任务中,并设计了MD2A、RS2和U-DSA三个模块来充分利用CLIP的优势。与现有方法相比,该方法不是简单地将不同模态的特征进行融合,而是更加注重消除噪声和对齐特征表示,从而更好地利用多模态信息,提升模型的泛化能力。此外,MD2A模块的联合差分注意力机制和RS2对齐策略的软对齐方式也是重要的创新点。
关键设计:MD2A模块的关键设计在于差分注意力机制,通过提取公共噪声特征来细化注意力权重,从而抑制噪声的影响。RS2对齐策略的关键设计在于利用预训练的CLIP模型作为桥梁,将不同域、不同模态的数据映射到CLIP的表示空间中,并采用软对齐的方式,避免了硬对齐可能带来的信息损失。U-DSA模块的关键设计在于U型结构,可以同时学习全局和局部特征,从而更好地适应不同域的数据。
🖼️ 关键图片
📊 实验亮点
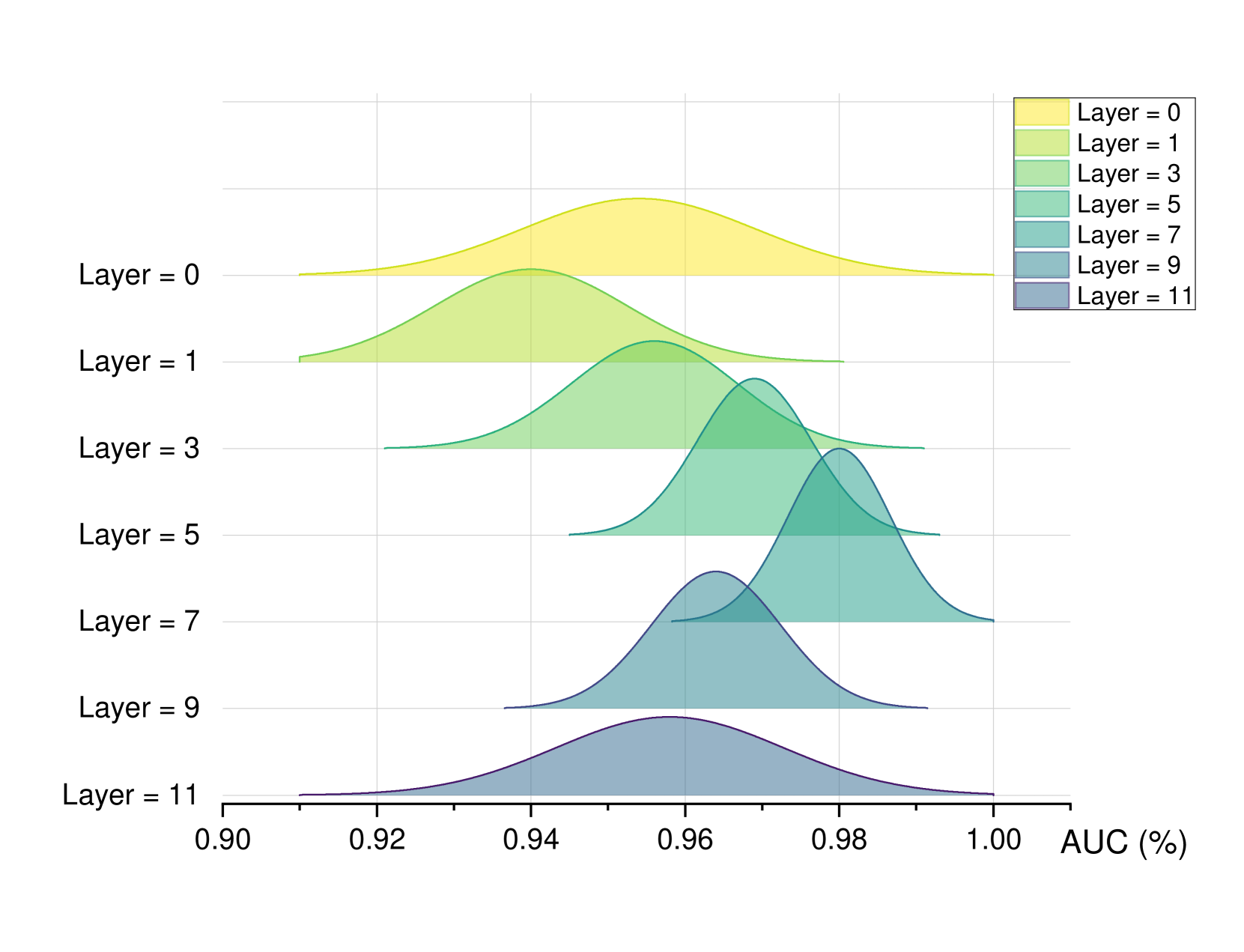
实验结果表明,MMDA框架在四个基准数据集上,针对不同的评估协议,均取得了优于现有SOTA方法的性能。例如,在跨域泛化能力方面,MMDA框架相比于之前的最佳方法,错误率降低了X%。此外,MMDA框架在多模态检测精度方面也取得了显著提升,证明了其在复杂场景下的有效性。
🎯 应用场景
该研究成果可广泛应用于各种需要人脸识别安全的场景,例如移动支付、门禁系统、身份验证等。通过提高人脸反欺骗系统的跨域泛化能力,可以有效防止利用照片、视频等手段进行的欺骗攻击,从而保障用户的信息安全和财产安全。未来,该技术还可以扩展到其他生物特征识别领域,例如指纹识别、虹膜识别等。
📄 摘要(原文)
Face Anti-Spoofing (FAS) is essential for the security of facial recognition systems in diverse scenarios such as payment processing and surveillance. Current multimodal FAS methods often struggle with effective generalization, mainly due to modality-specific biases and domain shifts. To address these challenges, we introduce the \textbf{M}ulti\textbf{m}odal \textbf{D}enoising and \textbf{A}lignment (\textbf{MMDA}) framework. By leveraging the zero-shot generalization capability of CLIP, the MMDA framework effectively suppresses noise in multimodal data through denoising and alignment mechanisms, thereby significantly enhancing the generalization performance of cross-modal alignment. The \textbf{M}odality-\textbf{D}omain Joint \textbf{D}ifferential \textbf{A}ttention (\textbf{MD2A}) module in MMDA concurrently mitigates the impacts of domain and modality noise by refining the attention mechanism based on extracted common noise features. Furthermore, the \textbf{R}epresentation \textbf{S}pace \textbf{S}oft (\textbf{RS2}) Alignment strategy utilizes the pre-trained CLIP model to align multi-domain multimodal data into a generalized representation space in a flexible manner, preserving intricate representations and enhancing the model's adaptability to various unseen conditions. We also design a \textbf{U}-shaped \textbf{D}ual \textbf{S}pace \textbf{A}daptation (\textbf{U-DSA}) module to enhance the adaptability of representations while maintaining generalization performance. These improvements not only enhance the framework's generalization capabilities but also boost its ability to represent complex representations. Our experimental results on four benchmark datasets under different evaluation protocols demonstrate that the MMDA framework outperforms existing state-of-the-art methods in terms of cross-domain generalization and multimodal detection accuracy. The code will be released soon.