Zero-Shot Multi-modal Large Language Model v.s. Supervised Deep Learning: A Comparative Study on CT-Based Intracranial Hemorrhage Subtyping
作者: Yinuo Wang, Yue Zeng, Kai Chen, Cai Meng, Chao Pan, Zhouping Tang
分类: cs.CV
发布日期: 2025-05-14 (更新: 2025-10-25)
💡 一句话要点
对比研究:零样本多模态大语言模型在CT图像颅内出血分型中表现不如监督深度学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 颅内出血分型 多模态大语言模型 深度学习 医学影像分析 零样本学习
📋 核心要点
- 颅内出血(ICH)亚型的及时识别对于预后预测和治疗决策至关重要,但由于低对比度和模糊边界而具有挑战性。
- 本研究对比零样本多模态大语言模型(MLLMs)与传统深度学习方法在ICH二分类和亚型分类任务中的性能。
- 实验结果表明,传统深度学习模型在ICH二分类和亚型分类任务中均优于MLLMs,但MLLMs在可解释性方面具有优势。
📝 摘要(中文)
本研究旨在评估零样本多模态大语言模型(MLLMs)与传统深度学习方法在基于非增强CT的颅内出血(ICH)二分类和分型任务中的性能。研究使用了RSNA提供的包含192个NCCT体数据的集。对比了GPT-4o、Gemini 2.0 Flash和Claude 3.5 Sonnet V2等多种MLLMs与ResNet50和Vision Transformer等传统深度学习模型。通过精心设计的提示词,引导MLLMs完成ICH存在判断、亚型分类、定位和体积估计等任务。结果表明,在ICH二分类任务中,传统深度学习模型全面优于MLLMs。在亚型分类任务中,MLLMs的性能也低于传统深度学习模型,其中Gemini 2.0 Flash的宏平均精确度为0.41,宏平均F1分数为0.31。结论是,虽然MLLMs在交互能力方面表现出色,但其在ICH亚型分类中的总体准确性不如深度网络。然而,MLLMs通过语言交互增强了可解释性,表明其在医学图像分析中具有潜力。未来的工作将侧重于模型改进和开发更精确的MLLMs,以提高三维医学图像处理的性能。
🔬 方法详解
问题定义:论文旨在解决基于CT图像的颅内出血(ICH)亚型分类问题。现有方法,即传统的深度学习方法,虽然在分类精度上表现良好,但在可解释性方面存在不足。同时,如何利用新兴的多模态大语言模型(MLLMs)进行医学图像分析,并评估其性能,也是一个待解决的问题。
核心思路:论文的核心思路是对比零样本MLLMs和监督深度学习模型在ICH亚型分类任务中的表现。通过精心设计的提示词,引导MLLMs理解CT图像并进行分类,同时与经过训练的深度学习模型进行性能比较,从而评估MLLMs在医学图像分析中的潜力。
技术框架:研究的技术框架主要包括数据准备、模型选择、提示词设计和性能评估四个阶段。首先,使用RSNA提供的CT图像数据集。然后,选择多种MLLMs(如GPT-4o、Gemini 2.0 Flash、Claude 3.5 Sonnet V2)和深度学习模型(如ResNet50、Vision Transformer)。接着,设计针对MLLMs的提示词,引导其完成ICH存在判断、亚型分类、定位和体积估计等任务。最后,使用标准指标(如精确度、F1分数)评估模型的性能。
关键创新:本研究的关键创新在于首次系统性地对比了零样本MLLMs和监督深度学习模型在颅内出血亚型分类任务中的性能。通过实验,揭示了MLLMs在医学图像分析中的优势和局限性,为未来MLLMs在医学领域的应用提供了参考。
关键设计:在MLLMs的使用上,关键在于提示词的设计,需要清晰地描述任务目标,并提供必要的上下文信息。在深度学习模型方面,采用了常用的ResNet50和Vision Transformer,并使用交叉熵损失函数进行训练。实验中,对所有模型使用了相同的数据集和评估指标,以保证公平性。
🖼️ 关键图片
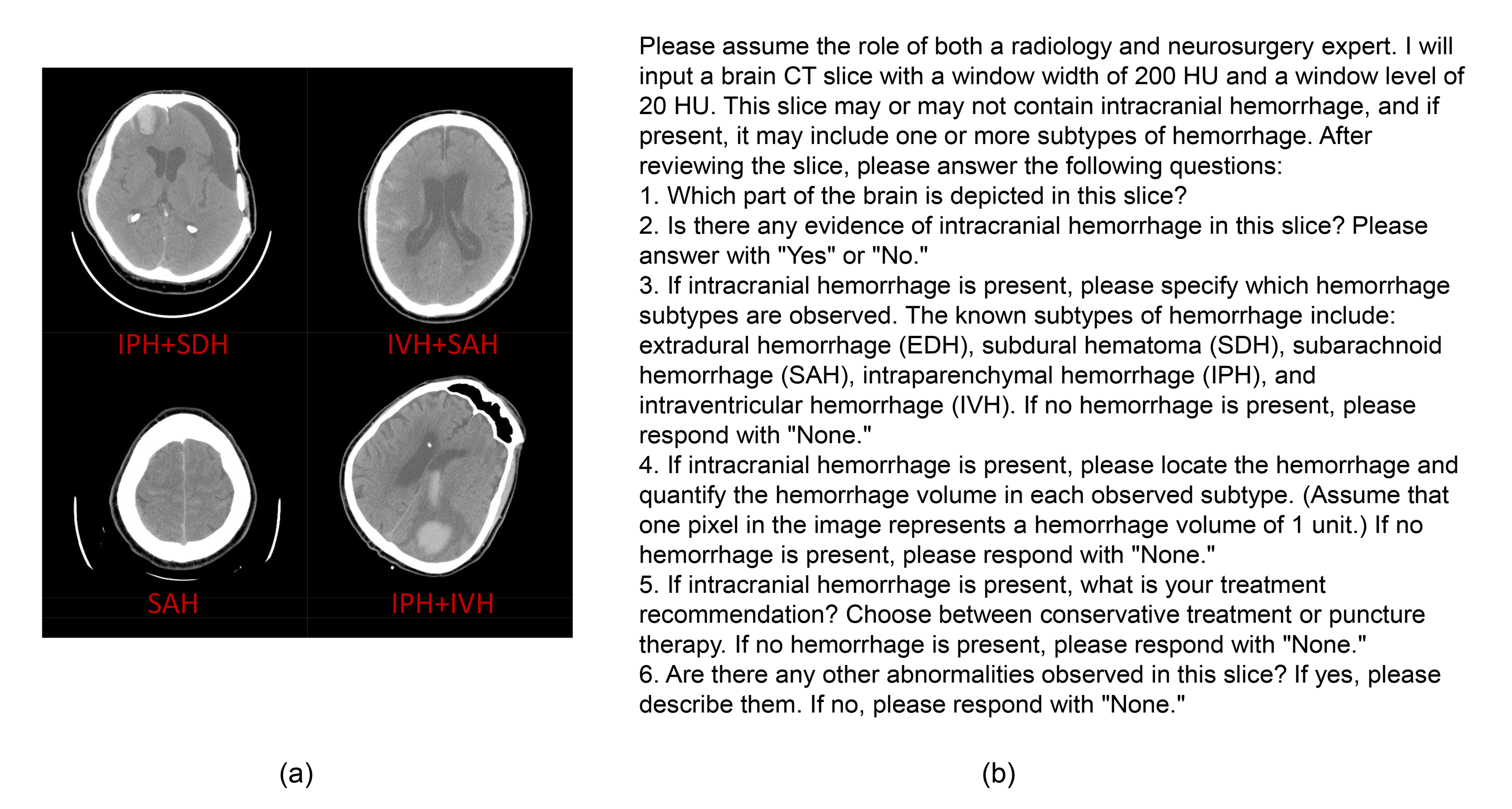


📊 实验亮点
实验结果表明,在ICH二分类任务中,传统深度学习模型全面优于MLLMs。在亚型分类任务中,MLLMs的性能也低于传统深度学习模型,其中Gemini 2.0 Flash的宏平均精确度为0.41,宏平均F1分数为0.31。虽然MLLMs在准确率上不如深度学习模型,但其通过语言交互增强了可解释性,具有潜在的应用价值。
🎯 应用场景
该研究成果可应用于辅助医生进行颅内出血亚型诊断,提高诊断效率和准确性。通过结合MLLMs的交互能力和深度学习模型的精确性,有望开发出更智能、更易用的医学影像分析工具,从而改善患者的治疗效果。未来,该方法还可以扩展到其他医学影像分析任务中。
📄 摘要(原文)
Introduction: Timely identification of intracranial hemorrhage (ICH) subtypes on non-contrast computed tomography is critical for prognosis prediction and therapeutic decision-making, yet remains challenging due to low contrast and blurring boundaries. This study evaluates the performance of zero-shot multi-modal large language models (MLLMs) compared to traditional deep learning methods in ICH binary classification and subtyping. Methods: We utilized a dataset provided by RSNA, comprising 192 NCCT volumes. The study compares various MLLMs, including GPT-4o, Gemini 2.0 Flash, and Claude 3.5 Sonnet V2, with conventional deep learning models, including ResNet50 and Vision Transformer. Carefully crafted prompts were used to guide MLLMs in tasks such as ICH presence, subtype classification, localization, and volume estimation. Results: The results indicate that in the ICH binary classification task, traditional deep learning models outperform MLLMs comprehensively. For subtype classification, MLLMs also exhibit inferior performance compared to traditional deep learning models, with Gemini 2.0 Flash achieving an macro-averaged precision of 0.41 and a macro-averaged F1 score of 0.31. Conclusion: While MLLMs excel in interactive capabilities, their overall accuracy in ICH subtyping is inferior to deep networks. However, MLLMs enhance interpretability through language interactions, indicating potential in medical imaging analysis. Future efforts will focus on model refinement and developing more precise MLLMs to improve performance in three-dimensional medical image processing.