EventDiff: A Unified and Efficient Diffusion Model Framework for Event-based Video Frame Interpolation
作者: Hanle Zheng, Xujie Han, Zegang Peng, Shangbin Zhang, Guangxun Du, Zhuo Zou, Xilin Wang, Jibin Wu, Hao Guo, Lei Deng
分类: cs.CV
发布日期: 2025-05-13
💡 一句话要点
EventDiff:一种统一高效的基于事件的视频帧插值扩散模型框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频帧插值 事件相机 扩散模型 自动编码器 时空注意力 视频生成 图像重建
📋 核心要点
- 现有基于事件的视频帧插值方法依赖手工设计的中间表示(如光流),在处理细微运动时图像重建效果不佳。
- EventDiff提出一种统一的基于事件的扩散模型框架,通过事件-帧混合自动编码器和时空交叉注意力模块,在潜在空间中进行去噪插值。
- 实验结果表明,EventDiff在多个数据集上超越了现有方法,在PSNR指标上提升显著,并实现了更快的推理速度。
📝 摘要(中文)
视频帧插值(VFI)是计算机视觉中一项基础但具有挑战性的任务,尤其是在涉及大运动、遮挡和光照变化的情况下。事件相机的最新进展为解决这些挑战开辟了新的机会。现有的基于事件的VFI方法通过利用光流等手工设计的中间表示成功地恢复了大型和复杂的运动,但由于它们依赖于显式的运动建模,因此这些设计通常会牺牲在细微运动场景下的高保真图像重建。同时,扩散模型通过去噪过程重建帧,为VFI提供了一种有希望的替代方案,消除了对显式运动估计或扭曲操作的需求。在这项工作中,我们提出了EventDiff,一个统一且高效的基于事件的VFI扩散模型框架。EventDiff采用了一种新颖的事件-帧混合自动编码器(HAE),该编码器配备了一个轻量级的时空交叉注意力(STCA)模块,可以有效地将动态事件流与静态帧融合。与以往基于事件的VFI方法不同,EventDiff通过去噪扩散过程直接在潜在空间中执行插值,使其在各种具有挑战性的VFI场景中更加鲁棒。通过一个两阶段的训练策略,首先预训练HAE,然后将其与扩散模型联合优化,我们的方法在多个合成和真实世界的事件VFI数据集上实现了最先进的性能。所提出的方法在Vimeo90K-Triplet上比现有的最先进的基于事件的VFI方法高出1.98dB PSNR,并在具有多个难度级别的SNU-FILM任务中表现出卓越的性能。与新兴的基于扩散的VFI方法相比,我们的方法在Vimeo90K-Triplet上实现了高达5.72dB的PSNR增益,并实现了4.24倍的更快推理。
🔬 方法详解
问题定义:论文旨在解决视频帧插值(VFI)问题,特别是在大运动、遮挡和光照变化等复杂场景下。现有基于事件的VFI方法依赖于显式的运动估计和光流等中间表示,这在细微运动场景下会损失图像重建的保真度。此外,这些方法通常计算复杂度较高,难以实现高效的推理。
核心思路:论文的核心思路是利用扩散模型强大的生成能力,通过去噪过程直接在潜在空间中进行帧插值,避免了显式的运动估计和光流计算。同时,引入事件信息作为辅助,指导扩散模型的去噪过程,从而更好地处理复杂场景下的运动和光照变化。这种方法旨在提高插值质量,并降低计算复杂度。
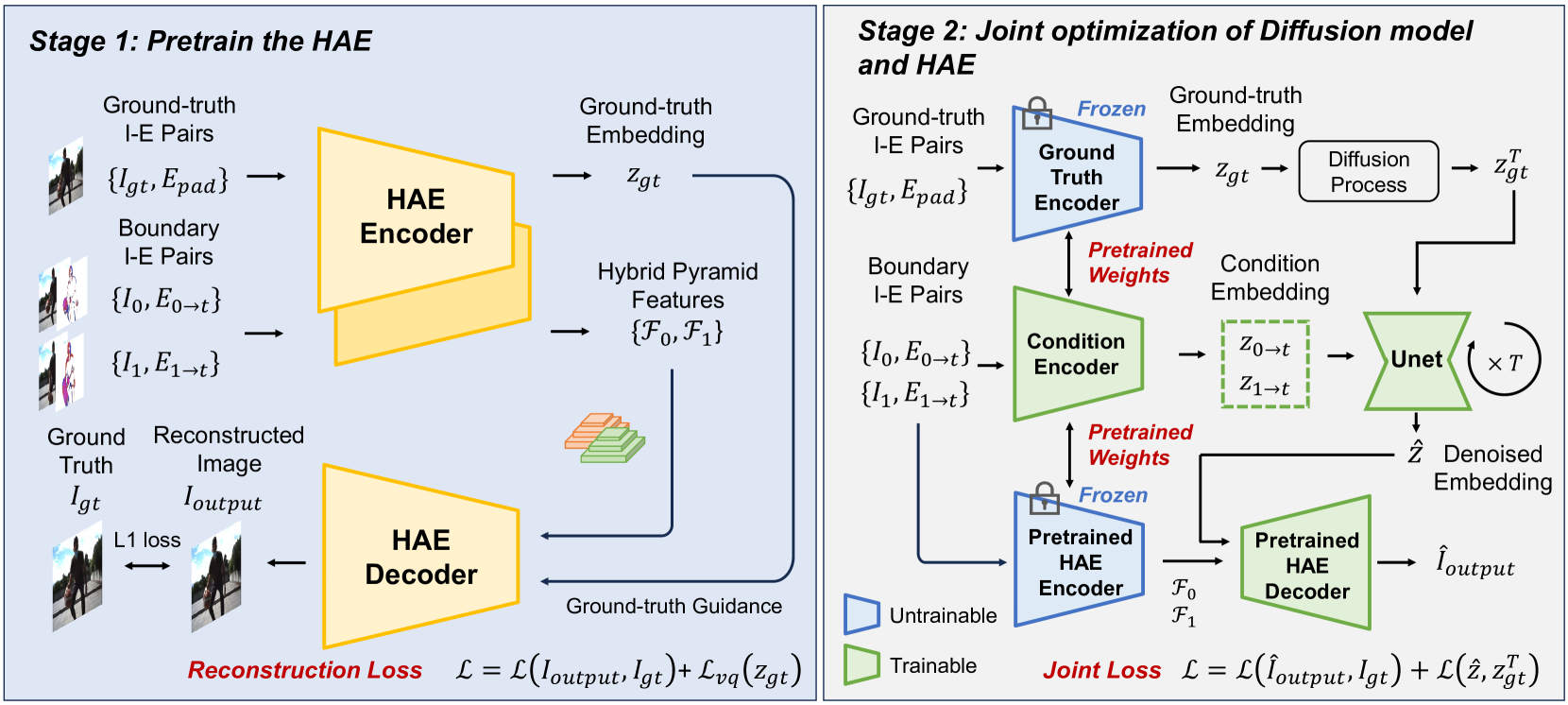
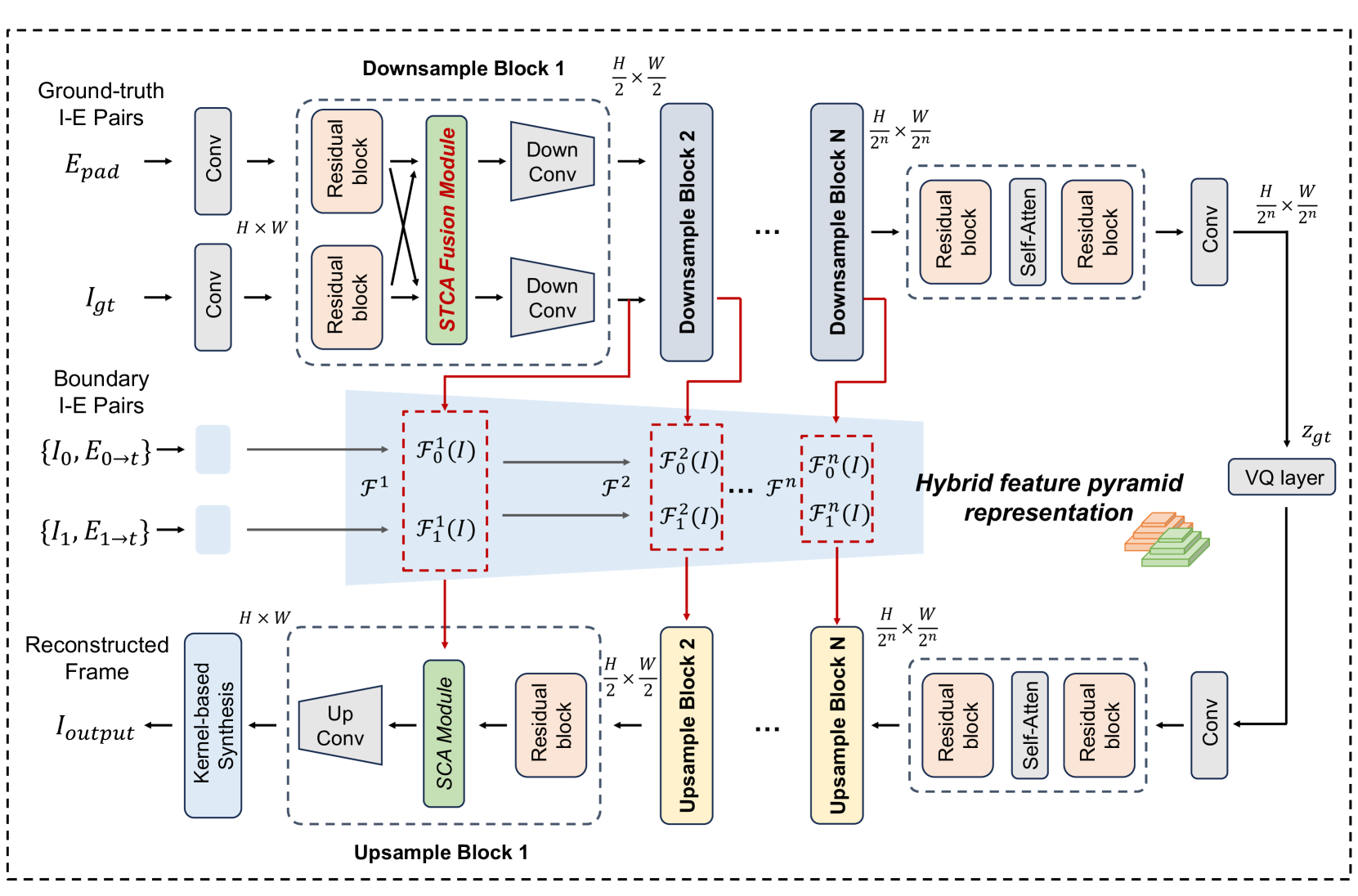
技术框架:EventDiff框架主要包含两个阶段:1) 事件-帧混合自动编码器(HAE)的预训练阶段;2) HAE与扩散模型的联合优化阶段。HAE负责将输入帧和事件信息编码到潜在空间,并从潜在空间解码出插值帧。扩散模型则负责在潜在空间中进行去噪,逐步恢复插值帧的细节。框架的关键模块包括:事件-帧混合自动编码器(HAE)、时空交叉注意力(STCA)模块和扩散模型。
关键创新:EventDiff的关键创新在于:1) 提出了一种统一的基于事件的扩散模型框架,将事件信息和扩散模型相结合,用于视频帧插值;2) 设计了一种新颖的事件-帧混合自动编码器(HAE),能够有效地融合动态事件流和静态帧;3) 采用时空交叉注意力(STCA)模块,增强了事件信息和帧信息之间的交互,提高了插值质量。与现有方法相比,EventDiff避免了显式的运动估计,直接在潜在空间中进行插值,从而提高了鲁棒性和效率。
关键设计:HAE采用编码器-解码器结构,编码器将输入帧和事件信息编码到潜在空间,解码器从潜在空间重建插值帧。STCA模块位于编码器的中间层,用于融合事件信息和帧信息。扩散模型采用U-Net结构,通过迭代去噪过程恢复插值帧的细节。损失函数包括重建损失(L1或L2损失)和扩散损失。训练过程分为两个阶段:首先预训练HAE,然后将其与扩散模型联合优化。
🖼️ 关键图片

📊 实验亮点
EventDiff在Vimeo90K-Triplet数据集上,相比现有最佳的基于事件的VFI方法,PSNR提升高达1.98dB。在SNU-FILM数据集上,EventDiff在不同难度级别上均表现出卓越的性能。与新兴的基于扩散的VFI方法相比,EventDiff在Vimeo90K-Triplet数据集上实现了高达5.72dB的PSNR增益,并实现了4.24倍的更快推理速度。这些实验结果表明,EventDiff在性能和效率方面均具有显著优势。
🎯 应用场景
EventDiff在视频编辑、慢动作视频生成、视频修复、自动驾驶等领域具有广泛的应用前景。例如,在视频编辑中,可以利用EventDiff生成高质量的中间帧,实现流畅的过渡效果。在自动驾驶中,可以利用EventDiff提高视频帧率,从而提高感知系统的性能和安全性。该研究的实际价值在于提供了一种更高效、更鲁棒的视频帧插值方法,未来可能推动相关领域的技术进步。
📄 摘要(原文)
Video Frame Interpolation (VFI) is a fundamental yet challenging task in computer vision, particularly under conditions involving large motion, occlusion, and lighting variation. Recent advancements in event cameras have opened up new opportunities for addressing these challenges. While existing event-based VFI methods have succeeded in recovering large and complex motions by leveraging handcrafted intermediate representations such as optical flow, these designs often compromise high-fidelity image reconstruction under subtle motion scenarios due to their reliance on explicit motion modeling. Meanwhile, diffusion models provide a promising alternative for VFI by reconstructing frames through a denoising process, eliminating the need for explicit motion estimation or warping operations. In this work, we propose EventDiff, a unified and efficient event-based diffusion model framework for VFI. EventDiff features a novel Event-Frame Hybrid AutoEncoder (HAE) equipped with a lightweight Spatial-Temporal Cross Attention (STCA) module that effectively fuses dynamic event streams with static frames. Unlike previous event-based VFI methods, EventDiff performs interpolation directly in the latent space via a denoising diffusion process, making it more robust across diverse and challenging VFI scenarios. Through a two-stage training strategy that first pretrains the HAE and then jointly optimizes it with the diffusion model, our method achieves state-of-the-art performance across multiple synthetic and real-world event VFI datasets. The proposed method outperforms existing state-of-the-art event-based VFI methods by up to 1.98dB in PSNR on Vimeo90K-Triplet and shows superior performance in SNU-FILM tasks with multiple difficulty levels. Compared to the emerging diffusion-based VFI approach, our method achieves up to 5.72dB PSNR gain on Vimeo90K-Triplet and 4.24X faster inference.