SpNeRF: Memory Efficient Sparse Volumetric Neural Rendering Accelerator for Edge Devices
作者: Yipu Zhang, Jiawei Liang, Jian Peng, Jiang Xu, Wei Zhang
分类: cs.AR, cs.CV
发布日期: 2025-05-13
备注: Accepted by DATE 2025
💡 一句话要点
SpNeRF:面向边缘设备的内存高效稀疏体神经渲染加速器
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经渲染 边缘计算 稀疏体素网格 哈希映射 软硬件协同设计
📋 核心要点
- 现有神经渲染方法在边缘设备上部署面临体素网格数据量大、访存不规则的挑战,导致实时性受限。
- SpNeRF通过软硬件协同设计,利用哈希映射进行预处理和在线解码,有效减小体素网格内存占用,并缓解哈希冲突。
- 实验表明,SpNeRF在保持PSNR的同时显著降低了内存占用,并在Jetson XNX等平台上实现了显著的加速和能效提升。
📝 摘要(中文)
神经渲染因其高质量的输出在AR/VR应用中日益重要。然而,其庞大的体素网格数据大小和不规则的访问模式对边缘设备的实时处理提出了挑战。虽然之前的工作侧重于提高数据局部性,但它们没有充分解决大型体素网格大小的问题,这需要频繁的片外内存访问和大量的片上内存。本文介绍了一种针对稀疏体神经渲染量身定制的软硬件协同设计解决方案SpNeRF。我们首先识别出内存受限的渲染效率低下问题,并分析了神经渲染体素网格数据中固有的稀疏性。为了提高效率,我们提出了新颖的预处理和在线解码步骤,减少了体素网格的内存大小。预处理步骤采用哈希映射来支持不规则数据访问,同时保持最小的内存大小。在线解码步骤能够实现高效的片上稀疏体素网格处理,并结合位图掩码来减轻哈希冲突造成的PSNR损失。为了进一步优化性能,我们设计了一种专用硬件架构,支持我们的稀疏体素网格处理技术。实验结果表明,SpNeRF在保持相当PSNR水平的同时,平均减少了21.07倍的内存大小。与Jetson XNX、Jetson ONX、RT-NeRF.Edge和NeuRex.Edge相比,我们的设计实现了95.1倍、63.5倍、1.5倍和10.3倍的加速,并将能效分别提高了625.6倍、529.1倍、4倍和4.4倍。
🔬 方法详解
问题定义:神经渲染在边缘设备上的应用受限于其庞大的体素网格数据,这导致了频繁的片外内存访问和大量的片上内存需求,严重影响了实时渲染性能。现有方法虽然尝试优化数据局部性,但未能有效解决体素网格尺寸过大的根本问题。
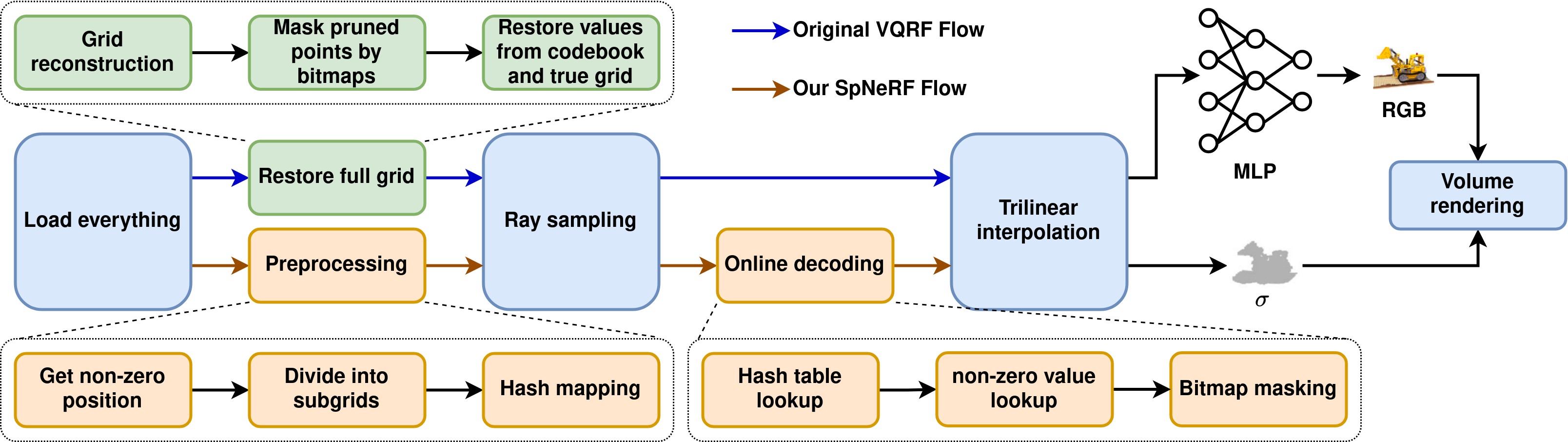
核心思路:SpNeRF的核心思路是利用神经渲染体素网格数据中固有的稀疏性,通过创新的预处理和在线解码步骤,在保证渲染质量的前提下,大幅度减少体素网格的内存占用。通过减少内存占用,可以降低片外访存的频率,从而提升渲染速度和能效。
技术框架:SpNeRF包含预处理和在线解码两个主要阶段。预处理阶段首先对体素网格进行稀疏化处理,然后使用哈希映射将稀疏数据存储到紧凑的内存空间中。在线解码阶段,根据光线追踪的需要,从哈希表中读取体素数据,并使用位图掩码来缓解哈希冲突带来的渲染质量损失。此外,论文还设计了专门的硬件架构来加速稀疏体素网格的处理。
关键创新:SpNeRF的关键创新在于其软硬件协同设计,特别是以下两点:一是利用哈希映射进行稀疏体素网格的存储,有效降低了内存占用;二是引入位图掩码来缓解哈希冲突,保证了渲染质量。与现有方法相比,SpNeRF在内存效率和渲染质量之间取得了更好的平衡。
关键设计:哈希函数的设计是关键,需要保证较低的冲突率。位图掩码的大小需要根据哈希冲突的概率进行调整,以在缓解冲突和增加内存开销之间取得平衡。硬件架构的设计需要充分考虑稀疏数据的访问模式,以实现高效的数据读取和处理。
🖼️ 关键图片


📊 实验亮点
SpNeRF在实验中表现出色,实现了平均21.07倍的内存占用降低,同时保持了与原始NeRF相当的PSNR。与Jetson XNX、Jetson ONX、RT-NeRF.Edge和NeuRex.Edge等平台相比,SpNeRF分别实现了95.1倍、63.5倍、1.5倍和10.3倍的加速,以及625.6倍、529.1倍、4倍和4.4倍的能效提升,证明了其在边缘设备上的优越性能。
🎯 应用场景
SpNeRF适用于对实时性和能效有较高要求的AR/VR应用,例如移动AR游戏、可穿戴设备的虚拟现实体验等。通过降低内存占用和提高渲染速度,SpNeRF能够使高质量的神经渲染在资源受限的边缘设备上成为可能,从而扩展了神经渲染的应用范围。
📄 摘要(原文)
Neural rendering has gained prominence for its high-quality output, which is crucial for AR/VR applications. However, its large voxel grid data size and irregular access patterns challenge real-time processing on edge devices. While previous works have focused on improving data locality, they have not adequately addressed the issue of large voxel grid sizes, which necessitate frequent off-chip memory access and substantial on-chip memory. This paper introduces SpNeRF, a software-hardware co-design solution tailored for sparse volumetric neural rendering. We first identify memory-bound rendering inefficiencies and analyze the inherent sparsity in the voxel grid data of neural rendering. To enhance efficiency, we propose novel preprocessing and online decoding steps, reducing the memory size for voxel grid. The preprocessing step employs hash mapping to support irregular data access while maintaining a minimal memory size. The online decoding step enables efficient on-chip sparse voxel grid processing, incorporating bitmap masking to mitigate PSNR loss caused by hash collisions. To further optimize performance, we design a dedicated hardware architecture supporting our sparse voxel grid processing technique. Experimental results demonstrate that SpNeRF achieves an average 21.07$\times$ reduction in memory size while maintaining comparable PSNR levels. When benchmarked against Jetson XNX, Jetson ONX, RT-NeRF.Edge and NeuRex.Edge, our design achieves speedups of 95.1$\times$, 63.5$\times$, 1.5$\times$ and 10.3$\times$, and improves energy efficiency by 625.6$\times$, 529.1$\times$, 4$\times$, and 4.4$\times$, respectively.