SAMChat: Introducing Chain of Thought Reasoning and GRPO to a Multimodal Small Language Model for Small Scale Remote Sensing
作者: Aybora Koksal, A. Aydin Alatan
分类: cs.CV
发布日期: 2025-05-12 (更新: 2025-11-27)
备注: Accepted to Journal of Selected Topics in Applied Earth Observations and Remote Sensing (JSTARS) Special Issue on Foundation and Large Vision Models for Remote Sensing. Code and dataset are available at https://github.com/aybora/SAMChat
DOI: 10.1109/JSTARS.2025.3637115
💡 一句话要点
提出SAMChat,结合CoT推理与GRPO,提升小规模遥感图像分析能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 遥感图像分析 小规模语言模型 思维链推理 强化学习 领域自适应 军事目标识别
📋 核心要点
- 现有通用多模态大模型在资源受限和领域特定的遥感图像分析中表现不足。
- SAMChat通过CoT推理提升模型解释能力,GRPO优化模型对军事目标的识别,降低误报。
- 实验表明,SAMChat在SAMData数据集上显著优于其他模型,召回率超80%,精确率达98%。
📝 摘要(中文)
本文提出了一种轻量级多模态语言模型SAMChat,专门用于分析偏远地区的遥感图像,特别是具有挑战性的导弹发射场。通过专家评审验证了数百张航拍图像,并编制了一个新的数据集SAMData,其中通过详细的描述突出了细微的军事设施。使用思维链(CoT)推理注释对一个20亿参数的开源多模态语言模型进行了监督微调,从而实现了更准确和可解释的解释。此外,利用群体相对策略优化(GRPO)来增强模型检测关键领域特定线索(如防御布局和关键军事结构)的能力,同时最大限度地减少民用场景中的误报。经验评估表明,SAMChat在开放式字幕和分类指标上显著优于更大规模的通用多模态模型和现有的遥感自适应方法。在新提出的SAMData基准测试中,实现了超过80%的召回率和98%的精确率,突出了有针对性的微调和强化学习在专业现实应用中的效力。
🔬 方法详解
问题定义:论文旨在解决现有通用多模态大模型在遥感图像分析,特别是军事目标识别方面的不足。现有方法在资源受限的场景下难以部署,且对领域特定线索的识别能力较弱,容易产生误报。
核心思路:论文的核心思路是针对遥感图像分析任务,对一个小规模多模态语言模型进行有针对性的微调和优化。通过引入CoT推理增强模型的可解释性,并利用GRPO强化模型对关键军事目标的识别能力,同时抑制对民用场景的误判。
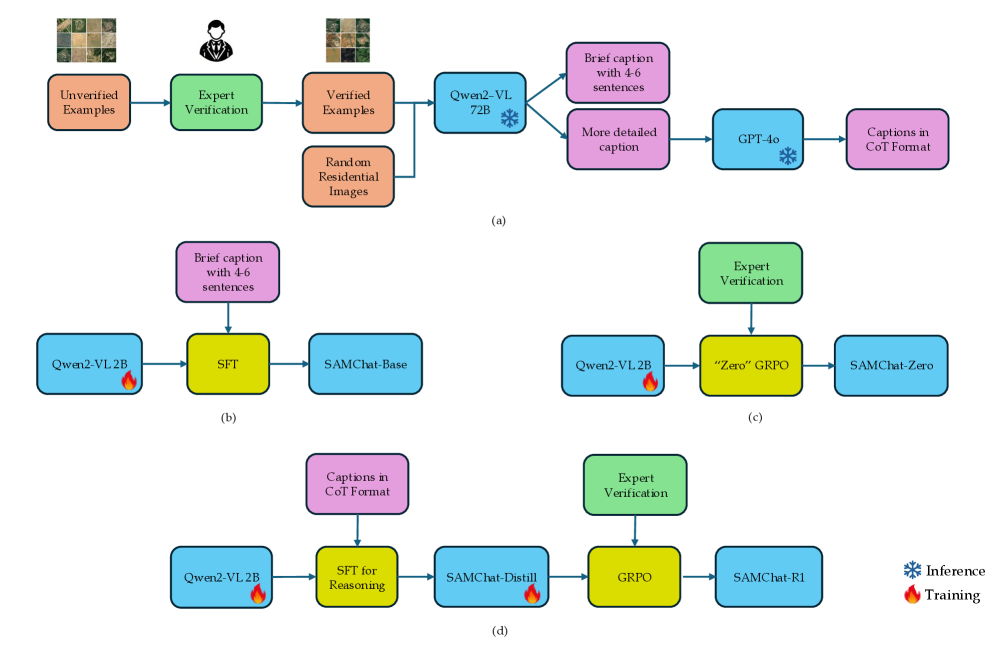
技术框架:SAMChat的技术框架主要包含以下几个阶段:1) 构建领域特定的数据集SAMData,包含带有详细描述的遥感图像,特别是军事设施的图像。2) 基于一个2B参数的开源多模态语言模型,使用SAMData进行监督微调,并加入CoT推理的标注。3) 利用GRPO对模型进行强化学习,优化模型对领域特定线索的识别能力。
关键创新:论文的关键创新在于将CoT推理和GRPO引入到小规模多模态语言模型的遥感图像分析中。CoT推理增强了模型的可解释性,使得模型能够给出更清晰的推理过程。GRPO则通过强化学习的方式,优化了模型对关键军事目标的识别能力,降低了误报率。
关键设计:论文的关键设计包括:1) SAMData数据集的构建,保证了数据的质量和领域相关性。2) CoT推理标注的设计,使得模型能够学习到更清晰的推理过程。3) GRPO的奖励函数设计,鼓励模型识别关键军事目标,同时惩罚对民用场景的误判。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
SAMChat在SAMData数据集上取得了显著的性能提升,召回率超过80%,精确率达到98%。相比于通用多模态大模型和现有的遥感图像分析方法,SAMChat在开放式字幕和分类指标上均表现出更优的性能,证明了有针对性的微调和强化学习在专业领域应用中的有效性。
🎯 应用场景
SAMChat可应用于军事侦察、国土安全、灾害监测等领域。该研究成果有助于在资源受限的环境下,快速准确地分析遥感图像,识别潜在威胁,为决策提供支持。未来,该方法可以推广到其他专业领域,例如农业监测、环境评估等。
📄 摘要(原文)
Remarkable capabilities in understanding and generating text-image content have been demonstrated by recent advancements in multimodal large language models (MLLMs). However, their effectiveness in specialized domains-particularly those requiring resource-efficient and domain-specific adaptations-has remained limited. In this work, a lightweight multimodal language model termed SAMChat is introduced, specifically adapted to analyze remote sensing imagery in secluded areas, including challenging missile launch sites. A new dataset, SAMData, was compiled by verifying hundreds of aerial images through expert review, and subtle military installations were highlighted via detailed captions. Supervised fine-tuning on a 2B parameter open-source MLLM with chain-of-thought (CoT) reasoning annotations was performed, enabling more accurate and interpretable explanations. Additionally, Group Relative Policy Optimization (GRPO) was leveraged to enhance the model's ability to detect critical domain-specific cues-such as defensive layouts and key military structures-while minimizing false positives on civilian scenes. Through empirical evaluations, it has been shown that SAMChat significantly outperforms both larger, general-purpose multimodal models and existing remote sensing adapted approaches on open-ended captioning and classification metrics. Over 80% recall and 98% precision were achieved on the newly proposed SAMData benchmark, underscoring the potency of targeted fine-tuning and reinforcement learning in specialized real-world applications.