DanceGRPO: Unleashing GRPO on Visual Generation
作者: Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, Ping Luo
分类: cs.CV
发布日期: 2025-05-12 (更新: 2025-08-28)
备注: Project Page: https://dancegrpo.github.io/
💡 一句话要点
DanceGRPO:利用GRPO解决视觉生成中与人类偏好对齐的难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉生成 强化学习 人类反馈 GRPO 扩散模型
📋 核心要点
- 现有基于强化学习的视觉生成方法,如DDPO和DPOK,在大规模和多样化提示集上难以维持优化稳定性,限制了其应用。
- DanceGRPO通过创新性地将Group Relative Policy Optimization (GRPO)应用于视觉生成任务,利用GRPO的稳定性机制克服优化挑战。
- 实验表明,DanceGRPO在多个基准测试上显著优于现有方法,最高提升达181%,证明了其在视觉生成RLHF任务中的有效性。
📝 摘要(中文)
生成式AI的最新进展彻底改变了视觉内容创作,但如何使模型输出与人类偏好对齐仍然是一个关键挑战。强化学习(RL)已成为微调生成模型的有前途的方法,但现有的方法如DDPO和DPOK面临根本性的局限性——特别是当扩展到大型和多样化的提示集时,它们无法维持稳定的优化,严重限制了它们的实际效用。本文提出了DanceGRPO,该框架通过对视觉生成任务的Group Relative Policy Optimization (GRPO)的创新性改编来解决这些局限性。我们的关键见解是,GRPO固有的稳定性机制使其能够独特地克服困扰先前基于RL的视觉生成方法的优化挑战。DanceGRPO取得了多项重大进展:首先,它展示了跨多种现代生成范式(包括扩散模型和校正流)的一致且稳定的策略优化。其次,它在扩展到包含三个关键任务和四个基础模型的复杂、真实世界的场景时,保持了强大的性能。第三,它在优化由五个不同的奖励模型捕获的各种人类偏好方面表现出了卓越的通用性,这些奖励模型评估图像/视频美学、文本-图像对齐、视频运动质量和二元反馈。我们的综合实验表明,DanceGRPO在多个已建立的基准测试(包括HPS-v2.1、CLIP Score、VideoAlign和GenEval)上,性能优于基线方法高达181%。我们的结果表明,DanceGRPO是扩展视觉生成中基于人类反馈的强化学习(RLHF)任务的强大而通用的解决方案,为协调强化学习和视觉合成提供了新的见解。
🔬 方法详解
问题定义:现有基于强化学习的视觉生成方法,如DDPO和DPOK,在面对大规模和多样化的提示集时,优化过程不稳定,难以有效对齐人类偏好。这限制了这些方法在实际应用中的价值。
核心思路:论文的核心思路是将Group Relative Policy Optimization (GRPO)应用于视觉生成任务。GRPO本身具有更强的优化稳定性,能够更好地处理复杂和多样化的提示,从而实现更有效的人类偏好对齐。这种设计旨在克服传统RL方法在视觉生成任务中遇到的优化难题。
技术框架:DanceGRPO框架的核心是利用GRPO算法来优化生成模型的策略。整体流程包括:1) 使用生成模型(如扩散模型或校正流)生成视觉内容;2) 使用奖励模型评估生成内容的质量和与人类偏好的对齐程度;3) 使用GRPO算法根据奖励信号更新生成模型的策略,使其生成更符合人类偏好的内容。该框架可以应用于多种生成模型和奖励模型。
关键创新:最重要的技术创新点是将GRPO成功应用于视觉生成任务。与传统的RL方法相比,GRPO具有更强的优化稳定性,能够更好地处理复杂和多样化的提示,从而实现更有效的人类偏好对齐。这是因为GRPO通过对策略进行分组和相对比较,减少了优化过程中的方差,从而提高了稳定性。
关键设计:论文中没有详细描述关键的参数设置、损失函数、网络结构等技术细节。但是,GRPO算法本身涉及到策略分组和相对策略优化等关键设计。具体实现可能需要根据不同的生成模型和奖励模型进行调整。例如,损失函数可能需要结合奖励信号和生成模型的损失函数,以实现更好的优化效果。
🖼️ 关键图片
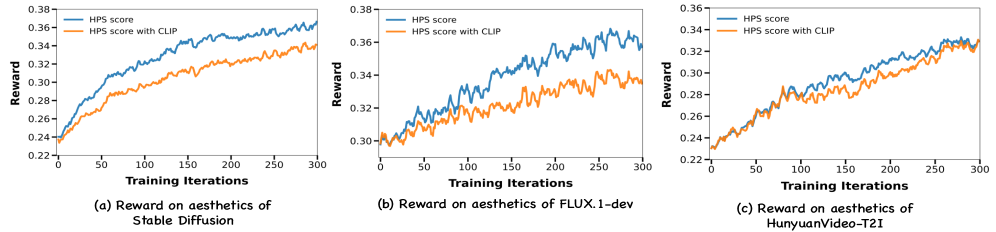
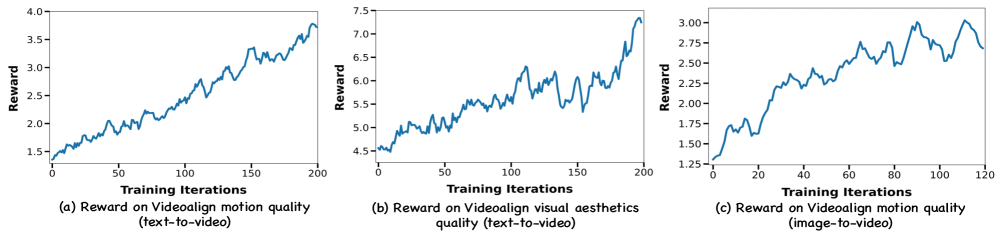
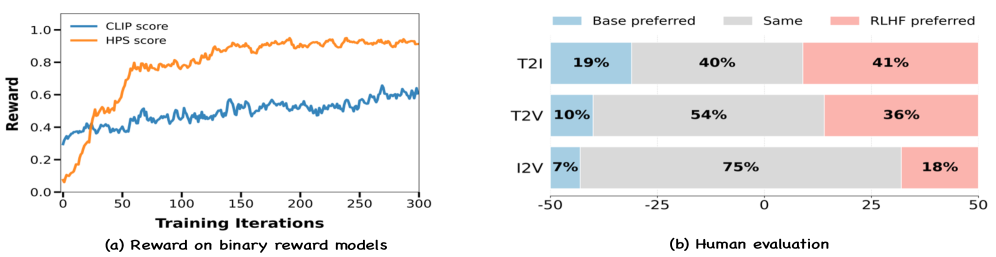
📊 实验亮点
实验结果表明,DanceGRPO在多个基准测试(包括HPS-v2.1、CLIP Score、VideoAlign和GenEval)上显著优于基线方法,最高提升达181%。这证明了DanceGRPO在视觉生成任务中具有强大的性能和优化能力,能够有效对齐人类偏好。
🎯 应用场景
DanceGRPO在视觉内容生成领域具有广泛的应用前景,例如图像和视频的风格迁移、内容编辑、个性化推荐等。它可以用于创建更符合用户偏好和审美标准的视觉内容,提升用户体验。未来,该技术有望应用于游戏、广告、教育等多个领域,推动视觉内容创作的智能化和个性化。
📄 摘要(原文)
Recent advances in generative AI have revolutionized visual content creation, yet aligning model outputs with human preferences remains a critical challenge. While Reinforcement Learning (RL) has emerged as a promising approach for fine-tuning generative models, existing methods like DDPO and DPOK face fundamental limitations - particularly their inability to maintain stable optimization when scaling to large and diverse prompt sets, severely restricting their practical utility. This paper presents DanceGRPO, a framework that addresses these limitations through an innovative adaptation of Group Relative Policy Optimization (GRPO) for visual generation tasks. Our key insight is that GRPO's inherent stability mechanisms uniquely position it to overcome the optimization challenges that plague prior RL-based approaches on visual generation. DanceGRPO establishes several significant advances: First, it demonstrates consistent and stable policy optimization across multiple modern generative paradigms, including both diffusion models and rectified flows. Second, it maintains robust performance when scaling to complex, real-world scenarios encompassing three key tasks and four foundation models. Third, it shows remarkable versatility in optimizing for diverse human preferences as captured by five distinct reward models assessing image/video aesthetics, text-image alignment, video motion quality, and binary feedback. Our comprehensive experiments reveal that DanceGRPO outperforms baseline methods by up to 181\% across multiple established benchmarks, including HPS-v2.1, CLIP Score, VideoAlign, and GenEval. Our results establish DanceGRPO as a robust and versatile solution for scaling Reinforcement Learning from Human Feedback (RLHF) tasks in visual generation, offering new insights into harmonizing reinforcement learning and visual synthesis.