MELLM: A Flow-Guided Large Language Model for Micro-Expression Understanding
作者: Sirui Zhao, Zhengye Zhang, Shifeng Liu, Xinglong Mao, Shukang Yin, Chaoyou Fu, Tong Xu, Enhong Chen
分类: cs.CV
发布日期: 2025-05-11 (更新: 2025-12-09)
💡 一句话要点
提出MELLM,利用光流引导的大语言模型进行微表情理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 微表情理解 光流估计 大语言模型 情感计算 多模态学习
📋 核心要点
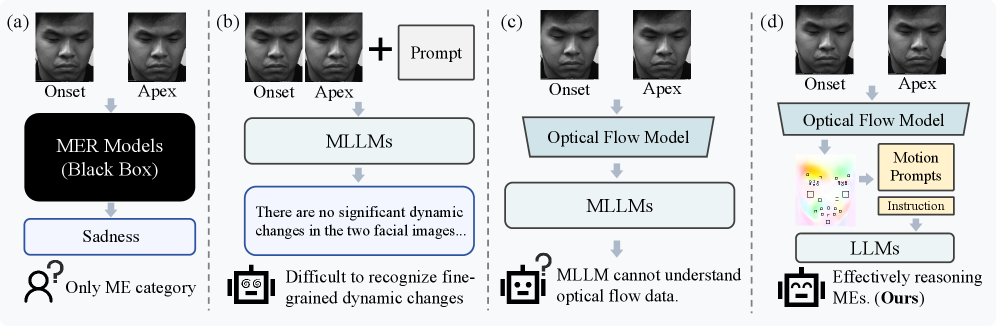
- 现有微表情识别方法局限于离散情绪分类,缺乏对微妙面部动态和潜在情感线索的理解。
- MELLM集成了光流敏感性和大语言模型的推理能力,通过光流引导实现更全面的微表情理解。
- 实验表明,MEFlowNet在光流估计上优于现有方法,MELLM在多个基准测试中达到SOTA。
📝 摘要(中文)
微表情(MEs)是揭示隐藏情绪的短暂且低强度的面部运动,对于情感计算至关重要。尽管微表情识别取得了显著进展,但现有方法主要局限于离散的情绪分类,缺乏全面的微表情理解(MEU)能力,尤其是在解释微妙的面部动态和潜在的情感线索方面。多模态大语言模型(MLLMs)凭借其先进的推理能力,为MEU提供了潜力,但它们仍然难以感知这种微妙的面部情感行为。为了弥合这一差距,我们提出了一个微表情大语言模型(MELLM),它集成了基于光流的对微妙面部运动的敏感性与LLM强大的推理能力。具体来说,我们引入了一种迭代的、基于扭曲的光流估计器,名为MEFlowNet,以精确捕捉面部微小运动。为了训练和评估它,我们构建了MEFlowDataset,这是一个大规模的光流数据集,包含54,611个起始-顶点图像对,涵盖不同的身份和微妙的面部运动。随后,我们设计了一个光流引导的微表情理解范式。在该框架下,利用MEFlowNet提取的光流信号来构建MEU-Instruct,这是一个用于MEU的指令调优数据集。然后,在MEU-Instruct上对MELLM进行微调,使其能够将微妙的运动模式转化为人类可读的描述,并生成相应的情感推断。实验表明,MEFlowNet在面部和ME光流估计方面显著优于现有的光流方法,而MELLM在多个ME基准测试中实现了最先进的准确性和泛化能力。据我们所知,这项工作提出了两个关键贡献:MEFlowNet作为第一个专门的ME光流估计器,以及MELLM作为第一个为MEU量身定制的LLM。
🔬 方法详解
问题定义:现有微表情识别方法主要集中于将微表情分类为预定义的离散情绪类别,缺乏对微表情所蕴含的细微情感变化的理解和解释能力。现有方法难以捕捉和理解面部肌肉的细微运动,导致无法进行深入的情感分析。
核心思路:本论文的核心思路是将光流信息与大语言模型相结合,利用光流技术捕捉面部细微运动,然后利用大语言模型的推理能力将这些运动模式转化为人类可理解的描述和情感推断。这种结合使得模型既能感知细微的面部变化,又能理解这些变化所代表的情感含义。
技术框架:MELLM的整体框架包含两个主要模块:MEFlowNet和微调后的LLM。首先,MEFlowNet负责从面部图像中提取光流信息,捕捉细微的面部运动。然后,利用提取的光流信息构建MEU-Instruct指令调优数据集。最后,在大规模指令数据集上对LLM进行微调,使其能够理解光流信息并生成相应的文本描述和情感推断。
关键创新:本论文的关键创新在于提出了MEFlowNet,这是第一个专门用于微表情光流估计的网络。此外,将光流信息与大语言模型相结合,构建了MELLM,实现了对微表情的深入理解,而不仅仅是分类。
关键设计:MEFlowNet采用迭代的、基于扭曲的光流估计方法,以精确捕捉面部微小运动。MEU-Instruct数据集包含大量指令,指导LLM如何根据光流信息生成描述和情感推断。LLM的微调过程旨在使模型能够将光流信息与情感表达联系起来。
🖼️ 关键图片


📊 实验亮点
MEFlowNet在面部和微表情光流估计方面显著优于现有方法。MELLM在多个微表情基准测试中实现了最先进的准确性和泛化能力,证明了其在微表情理解方面的有效性。MELLM能够将微妙的运动模式转化为人类可读的描述,并生成相应的情感推断。
🎯 应用场景
MELLM在情感计算领域具有广泛的应用前景,例如心理健康评估、人机交互、安全监控和市场营销等。通过理解微表情,可以更准确地识别个体的情绪状态,从而提供更个性化和有效的服务。例如,在心理咨询中,可以帮助咨询师更好地理解患者的真实感受;在人机交互中,可以使机器能够更自然地与人交流。
📄 摘要(原文)
Micro-expressions (MEs), brief and low-intensity facial movements revealing concealed emotions, are crucial for affective computing. Despite notable progress in ME recognition, existing methods are largely confined to discrete emotion classification, lacking the capacity for comprehensive ME Understanding (MEU), particularly in interpreting subtle facial dynamics and underlying emotional cues. While Multimodal Large Language Models (MLLMs) offer potential for MEU with their advanced reasoning abilities, they still struggle to perceive such subtle facial affective behaviors. To bridge this gap, we propose a ME Large Language Model (MELLM) that integrates optical flow-based sensitivity to subtle facial motions with the powerful inference ability of LLMs. Specifically, an iterative, warping-based optical-flow estimator, named MEFlowNet, is introduced to precisely capture facial micro-movements. For its training and evaluation, we construct MEFlowDataset, a large-scale optical-flow dataset with 54,611 onset-apex image pairs spanning diverse identities and subtle facial motions. Subsequently, we design a Flow-Guided Micro-Expression Understanding paradigm. Under this framework, the optical flow signals extracted by MEFlowNet are leveraged to build MEU-Instruct, an instruction-tuning dataset for MEU. MELLM is then fine-tuned on MEU-Instruct, enabling it to translate subtle motion patterns into human-readable descriptions and generate corresponding emotional inferences. Experiments demonstrate that MEFlowNet significantly outperforms existing optical flow methods in facial and ME-flow estimation, while MELLM achieves state-of-the-art accuracy and generalization across multiple ME benchmarks. To the best of our knowledge, this work presents two key contributions: MEFlowNet as the first dedicated ME flow estimator, and MELLM as the first LLM tailored for MEU.