Temperature-Driven Robust Disease Detection in Brain and Gastrointestinal Disorders via Context-Aware Adaptive Knowledge Distillation
作者: Saif Ur Rehman Khan, Muhammad Nabeel Asim, Sebastian Vollmer, Andreas Dengel
分类: cs.CV
发布日期: 2025-05-09 (更新: 2025-09-19)
备注: This version v2 updates the title to match the version accepted for publication in biomedical-signal-processing-and-control. The title has been changed to 'Temperature-Driven Robust Disease Detection in Brain and Gastrointestinal Disorders via Context-Aware Adaptive Knowledge Distillation'. The scientific content is unchanged from v1
💡 一句话要点
提出基于上下文感知自适应知识蒸馏的稳健疾病检测方法,提升脑部和胃肠道疾病诊断精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 医学影像 疾病检测 知识蒸馏 上下文感知 自适应温度 蚁群优化 深度学习
📋 核心要点
- 医学图像数据复杂多变,传统知识蒸馏方法难以有效处理图像质量差异和疾病复杂性带来的不确定性。
- 提出一种上下文感知的自适应知识蒸馏框架,利用蚁群优化算法进行模型选择,并根据图像上下文动态调整温度参数。
- 在脑肿瘤和胃肠道疾病数据集上验证,显著优于现有方法,在三个数据集上分别提升了0.77%、1.38%和1.2%。
📝 摘要(中文)
医学疾病预测,特别是通过影像学手段,由于医学数据的复杂性和可变性(包括噪声、模糊性和不同的图像质量)而仍然是一项具有挑战性的任务。近期的深度学习模型,包括知识蒸馏(KD)方法,在脑肿瘤图像识别方面显示出有希望的结果,但在处理不确定性和推广到不同的医学条件方面仍然面临限制。传统的KD方法通常依赖于上下文无关的温度参数来软化教师模型的预测,这不能有效地适应医学图像中存在的不同不确定性水平。为了解决这个问题,我们提出了一个新颖的框架,该框架集成了蚁群优化(ACO)以实现最佳的教师-学生模型选择,以及一种新颖的上下文感知预测器方法来进行温度缩放。所提出的上下文感知框架基于图像质量、疾病复杂性和教师模型置信度等因素来调整温度,从而实现更稳健的知识转移。此外,ACO有效地从一组预训练模型中选择最合适的教师-学生模型对,通过探索更广泛的解决方案空间并更好地处理数据中复杂的非线性关系,优于当前的优化方法。所提出的框架使用三个公开可用的基准数据集进行评估,每个数据集对应于一个不同的医学成像任务。结果表明,所提出的框架显着优于当前最先进的方法,实现了最高的准确率:在MRI脑肿瘤(Kaggle)数据集上为98.01%,在Figshare MRI数据集上为92.81%,在GastroNet数据集上为96.20%。这种增强的性能通过改进的结果进一步证明,超过了现有的基准97.24%(Kaggle),91.43%(Figshare)和95.00%(GastroNet)。
🔬 方法详解
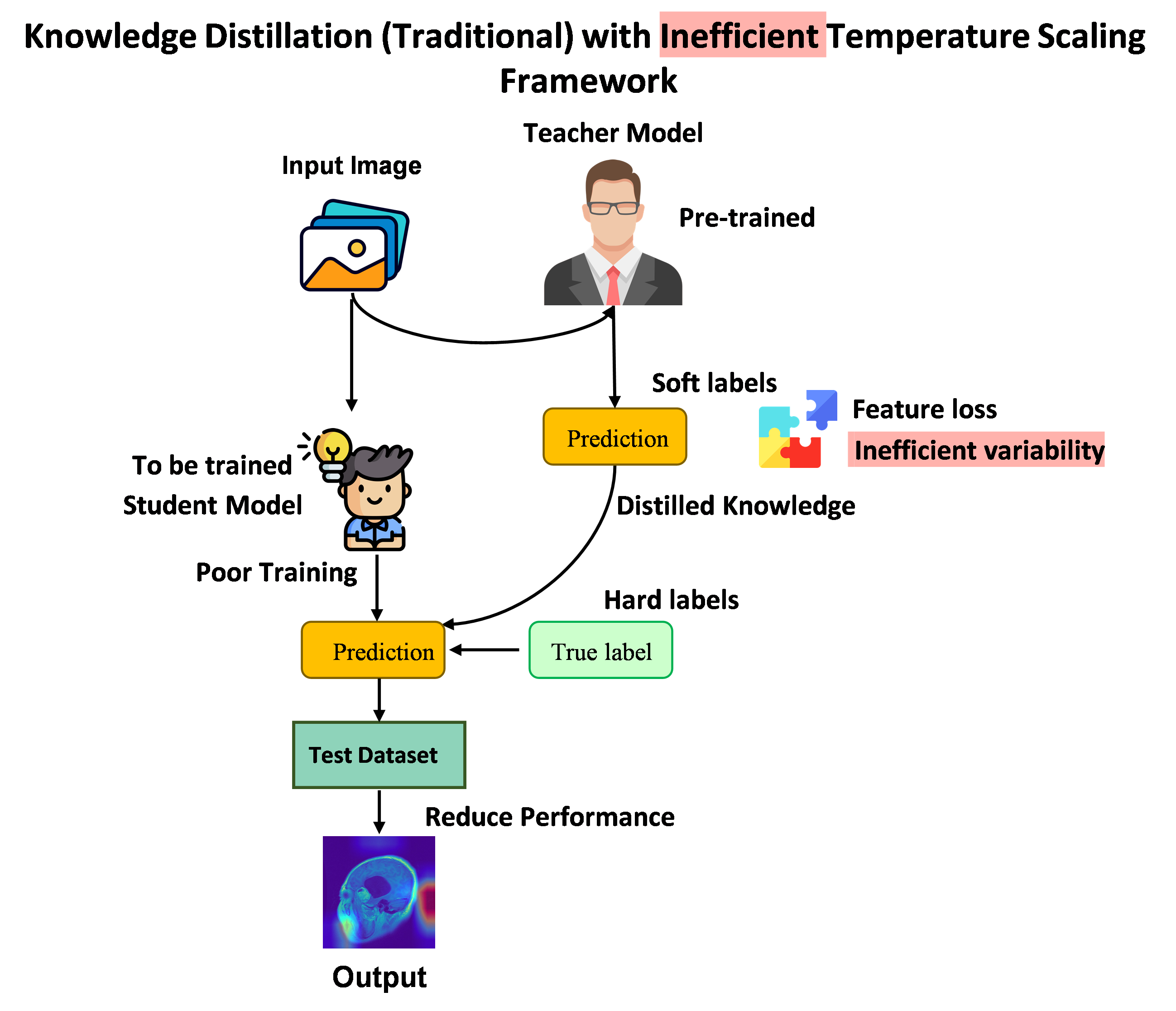
问题定义:医学图像的疾病检测任务面临数据质量参差不齐、疾病表现形式多样等挑战,导致模型泛化能力受限。传统的知识蒸馏方法在软化教师模型预测时,通常采用固定的温度参数,无法有效适应不同图像的不确定性水平,影响知识迁移效果。
核心思路:论文的核心思路是引入上下文感知机制,根据图像质量、疾病复杂度和教师模型置信度等因素动态调整知识蒸馏过程中的温度参数,从而实现更稳健的知识迁移。此外,采用蚁群优化算法(ACO)自动选择最佳的教师-学生模型组合,进一步提升模型性能。
技术框架:整体框架包含两个主要部分:1) 基于蚁群优化(ACO)的教师-学生模型选择模块;2) 上下文感知的自适应温度缩放知识蒸馏模块。首先,ACO从预训练的模型池中选择最佳的教师-学生模型对。然后,上下文感知模块根据输入图像的特征(如图像质量、疾病复杂性等)动态调整温度参数,用于软化教师模型的预测结果。最后,学生模型通过最小化与软化后的教师模型预测结果之间的差异进行训练。
关键创新:论文的关键创新在于提出了上下文感知的自适应温度缩放方法。与传统的固定温度参数的知识蒸馏方法不同,该方法能够根据输入图像的特征动态调整温度参数,从而更好地适应不同图像的不确定性水平,实现更有效的知识迁移。此外,使用ACO进行模型选择,能够自动找到最佳的教师-学生模型组合,避免了手动选择的繁琐和主观性。
关键设计:上下文感知模块的设计是关键。该模块利用图像质量评估指标(如清晰度、对比度等)、疾病复杂性度量(如病灶大小、形状等)以及教师模型的置信度作为输入,通过一个预测器(predictor)来预测最佳的温度参数。预测器可以是一个简单的线性模型或一个更复杂的神经网络。损失函数通常采用交叉熵损失或KL散度,用于衡量学生模型的预测结果与软化后的教师模型预测结果之间的差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在三个公开数据集上均取得了显著的性能提升。在MRI脑肿瘤(Kaggle)数据集上,准确率达到98.01%,超过现有最佳结果0.77%;在Figshare MRI数据集上,准确率达到92.81%,提升1.38%;在GastroNet数据集上,准确率达到96.20%,提升1.2%。这些结果验证了该方法在提升医学图像疾病检测准确性和鲁棒性方面的有效性。
🎯 应用场景
该研究成果可广泛应用于医学影像辅助诊断领域,例如脑肿瘤检测、胃肠道疾病筛查等。通过提升疾病检测的准确性和鲁棒性,可以帮助医生更快速、更准确地做出诊断,提高诊疗效率,改善患者预后。未来,该方法有望推广到其他医学影像模态和疾病类型,为精准医疗提供更强大的技术支持。
📄 摘要(原文)
Medical disease prediction, particularly through imaging, remains a challenging task due to the complexity and variability of medical data, including noise, ambiguity, and differing image quality. Recent deep learning models, including Knowledge Distillation (KD) methods, have shown promising results in brain tumor image identification but still face limitations in handling uncertainty and generalizing across diverse medical conditions. Traditional KD methods often rely on a context-unaware temperature parameter to soften teacher model predictions, which does not adapt effectively to varying uncertainty levels present in medical images. To address this issue, we propose a novel framework that integrates Ant Colony Optimization (ACO) for optimal teacher-student model selection and a novel context-aware predictor approach for temperature scaling. The proposed context-aware framework adjusts the temperature based on factors such as image quality, disease complexity, and teacher model confidence, allowing for more robust knowledge transfer. Additionally, ACO efficiently selects the most appropriate teacher-student model pair from a set of pre-trained models, outperforming current optimization methods by exploring a broader solution space and better handling complex, non-linear relationships within the data. The proposed framework is evaluated using three publicly available benchmark datasets, each corresponding to a distinct medical imaging task. The results demonstrate that the proposed framework significantly outperforms current state-of-the-art methods, achieving top accuracy rates: 98.01% on the MRI brain tumor (Kaggle) dataset, 92.81% on the Figshare MRI dataset, and 96.20% on the GastroNet dataset. This enhanced performance is further evidenced by the improved results, surpassing existing benchmarks of 97.24% (Kaggle), 91.43% (Figshare), and 95.00% (GastroNet).