Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
作者: Han Xiao, Yina Xie, Guanxin Tan, Yinghao Chen, Rui Hu, Ke Wang, Aojun Zhou, Hao Li, Hao Shao, Xudong Lu, Peng Gao, Yafei Wen, Xiaoxin Chen, Shuai Ren, Hongsheng Li
分类: cs.CV, cs.CL
发布日期: 2025-05-08
备注: CVPR2025
💡 一句话要点
提出自适应标记语言生成方法,用于上下文感知的视觉文档理解。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文档理解 多模态学习 标记语言生成 上下文感知 结构化表示
📋 核心要点
- 现有视觉文档理解方法难以有效整合视觉感知和文本理解,尤其是在复杂布局的文档中。
- 论文提出自适应生成标记语言(如Markdown、JSON等)的方法,构建结构化文档表示,实现上下文感知的响应。
- 实验表明,该模型在多个视觉文档理解基准上显著优于现有模型,提升了复杂场景下的推理和理解能力。
📝 摘要(中文)
随着富文本视觉内容的增加,视觉文档理解变得至关重要。该领域面临着有效整合视觉感知和文本理解的重大挑战,尤其是在具有复杂布局的各种文档类型中。此外,现有的微调数据集通常缺乏用于鲁棒理解的详细上下文信息,导致幻觉和对视觉元素之间空间关系的有限理解。为了应对这些挑战,我们提出了一种创新的流程,该流程利用自适应生成标记语言(如Markdown、JSON、HTML和TiKZ)来构建高度结构化的文档表示并提供上下文相关的响应。我们引入了两个细粒度的结构化数据集:DocMark-Pile,包含约380万个用于文档解析的预训练数据对;DocMark-Instruct,包含62.4万个用于基于上下文指令跟随的微调数据标注。大量实验表明,我们提出的模型在各种视觉文档理解基准测试中显著优于现有的最先进的多模态大语言模型,从而促进了复杂视觉场景中的高级推理和理解能力。我们的代码和模型已在https://github.com/Euphoria16/DocMark上发布。
🔬 方法详解
问题定义:视觉文档理解旨在理解包含文本和视觉信息的文档,现有方法在处理复杂布局和缺乏上下文信息时表现不佳,容易产生幻觉,无法准确理解视觉元素间的空间关系。现有的微调数据集也难以提供足够的上下文信息,限制了模型的泛化能力。
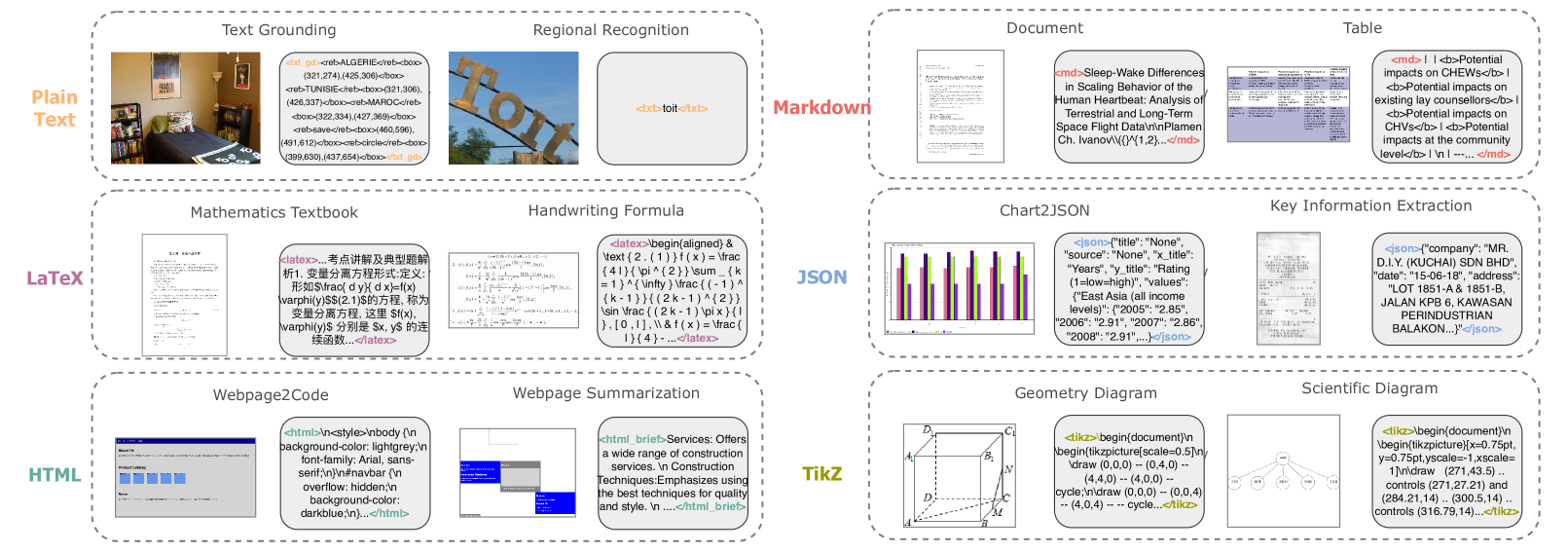
核心思路:论文的核心思路是利用自适应生成的标记语言(如Markdown、JSON、HTML、TiKZ)来显式地表示文档的结构和上下文信息。通过将文档转换为结构化的标记语言,模型可以更好地理解文档的布局和元素之间的关系,从而提高理解能力和减少幻觉。
技术框架:该方法包含一个自适应标记语言生成器,用于将视觉文档转换为结构化的标记语言表示。然后,一个多模态大语言模型(MLLM)利用这种结构化的表示来执行各种视觉文档理解任务,例如文档解析和基于上下文的指令跟随。此外,论文还构建了两个新的数据集:DocMark-Pile(用于预训练)和DocMark-Instruct(用于微调),以支持模型的训练和评估。
关键创新:该方法最重要的创新点在于自适应地生成标记语言来表示视觉文档的结构和上下文信息。与以往直接处理像素或文本的方法不同,该方法通过显式地建模文档的结构,使得模型能够更好地理解文档的内容和布局。这种方法可以有效地减少幻觉,并提高模型在复杂视觉场景中的推理能力。
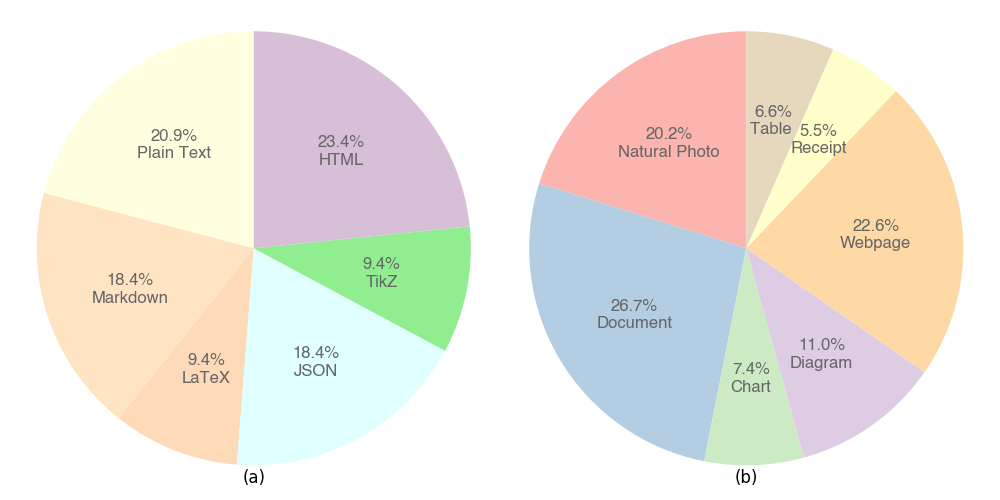
关键设计:自适应标记语言生成器的具体实现细节未知,但可以推测其目标是生成能够准确反映文档结构和内容的标记语言代码。DocMark-Pile数据集包含380万个预训练数据对,DocMark-Instruct数据集包含62.4万个微调数据标注。损失函数和网络结构等技术细节在论文中未明确说明,需要参考论文原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该模型在多个视觉文档理解基准测试中显著优于现有的最先进的多模态大语言模型。具体的性能数据和提升幅度在摘要中未给出,需要在论文原文中查找。该模型在复杂视觉场景中的推理和理解能力得到了显著提升。
🎯 应用场景
该研究成果可应用于自动化文档处理、信息抽取、智能办公、辅助阅读等领域。例如,可以用于自动解析合同、发票等文档,提取关键信息;也可以用于构建智能文档助手,帮助用户快速理解和处理各种类型的文档。未来的研究可以进一步探索更复杂的文档结构和更有效的标记语言生成方法。
📄 摘要(原文)
Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.