TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation
作者: Haokun Lin, Teng Wang, Yixiao Ge, Yuying Ge, Zhichao Lu, Ying Wei, Qingfu Zhang, Zhenan Sun, Ying Shan
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-05-08 (更新: 2025-08-15)
备注: Technical Report
🔗 代码/项目: GITHUB
💡 一句话要点
TokLIP通过语义化视觉tokens并融合CLIP语义,提升多模态理解与生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉Token CLIP语义 自回归模型 图像理解 图像生成 向量量化
📋 核心要点
- 现有基于token的多模态方法训练成本高昂,且由于缺乏高层语义,理解能力有限。
- TokLIP通过语义化VQ tokens并融入CLIP语义,实现了高效的多模态自回归训练。
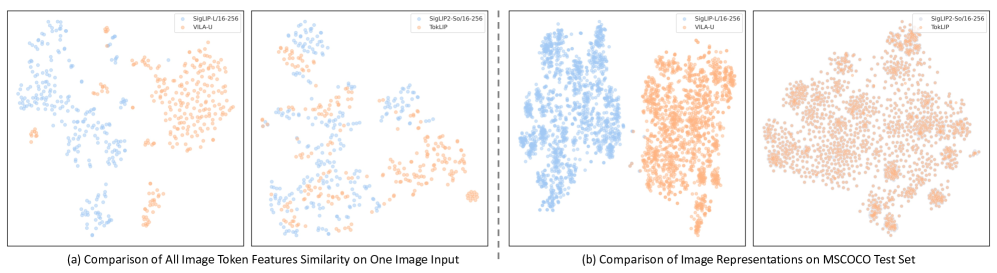
- 实验表明,TokLIP在数据效率、语义理解和生成能力方面均有显著提升。
📝 摘要(中文)
本文提出TokLIP,一种视觉tokenizer,通过语义化向量量化(VQ) tokens并结合CLIP级别的语义来增强理解能力。TokLIP使用标准的VQ tokens,实现了端到端的多模态自回归训练,克服了现有基于token的方法(如Chameleon和Emu3)训练计算开销大和缺乏高层语义导致理解性能受限的挑战。TokLIP集成了低层离散VQ tokenizer和一个基于ViT的token编码器,以捕获高层连续语义。与以往离散化高层特征的方法(如VILA-U)不同,TokLIP解耦了理解和生成的训练目标,可以直接应用先进的VQ tokenizer,而无需定制的量化操作。实验结果表明,TokLIP具有卓越的数据效率,赋予视觉tokens高层语义理解能力,同时增强了低层生成能力,使其非常适合自回归Transformer的理解和生成任务。
🔬 方法详解
问题定义:现有基于token的多模态模型,例如Chameleon和Emu3,在多模态统一方面取得了进展,但面临着两个主要问题:一是训练计算开销巨大,二是由于缺乏高层语义信息,导致理解性能受到限制。这些模型难以在计算资源有限的情况下,实现对复杂视觉信息的有效理解和生成。
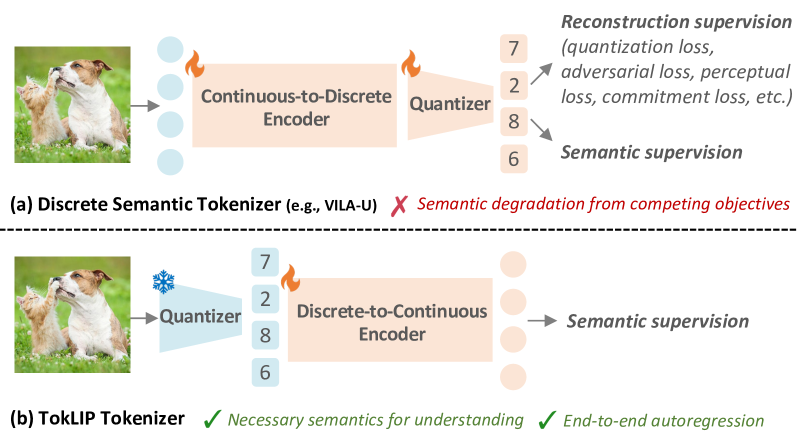
核心思路:TokLIP的核心思路是将低层离散的视觉tokens与高层连续的语义信息相结合,从而在保证生成能力的同时,提升模型的理解能力。具体来说,TokLIP通过语义化向量量化(VQ)tokens,并融入CLIP级别的语义,使得模型能够更好地理解视觉tokens所代表的含义。这种设计解耦了理解和生成的训练目标,允许直接应用先进的VQ tokenizer,而无需进行定制化的量化操作。
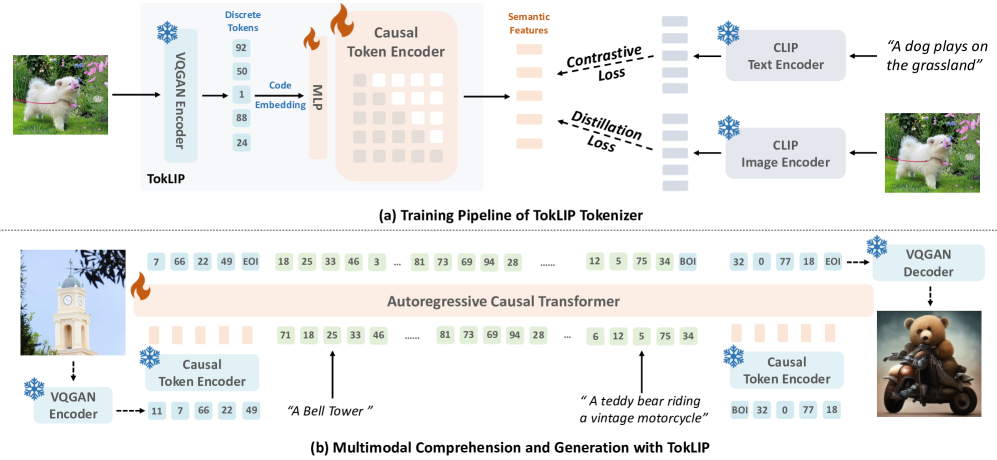
技术框架:TokLIP的技术框架主要包括两个关键模块:一个低层离散的VQ tokenizer和一个基于ViT的token编码器。VQ tokenizer负责将原始图像转换为离散的视觉tokens,而ViT-based token编码器则负责将这些tokens编码为高层连续的语义表示。这两个模块共同作用,使得TokLIP能够同时捕获图像的低层细节和高层语义信息。整个框架采用端到端的多模态自回归训练方式,使得模型能够同时学习理解和生成的能力。
关键创新:TokLIP最关键的创新在于其将低层离散的VQ tokens与高层连续的CLIP语义相结合的方式。与以往直接离散化高层特征的方法(如VILA-U)不同,TokLIP保留了低层tokens的生成能力,同时通过ViT编码器引入了高层语义信息,从而实现了更好的理解和生成性能。此外,TokLIP还解耦了理解和生成的训练目标,使得模型能够更加专注于学习每个任务的特定特征。
关键设计:TokLIP的关键设计包括:1) 使用标准的VQ tokenizer,避免了定制化的量化操作;2) 采用ViT作为token编码器,以捕获高层语义信息;3) 使用CLIP级别的语义信息来增强视觉tokens的理解能力;4) 采用端到端的多模态自回归训练方式,使得模型能够同时学习理解和生成的能力。具体的参数设置和损失函数等技术细节在论文中进行了详细描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
TokLIP在多个多模态任务上取得了显著的性能提升,展现了其卓越的数据效率和强大的语义理解能力。具体性能数据和对比基线未知,但论文强调TokLIP在赋予视觉tokens高层语义理解能力的同时,增强了低层生成能力。
🎯 应用场景
TokLIP在多模态对话、图像描述、视觉问答等领域具有广泛的应用前景。通过提升模型对视觉信息的理解能力,TokLIP可以帮助构建更智能、更自然的交互系统。未来,TokLIP有望应用于智能客服、自动驾驶、医疗影像分析等领域,为人们的生活和工作带来便利。
📄 摘要(原文)
Pioneering token-based works such as Chameleon and Emu3 have established a foundation for multimodal unification but face challenges of high training computational overhead and limited comprehension performance due to a lack of high-level semantics. In this paper, we introduce TokLIP, a visual tokenizer that enhances comprehension by semanticizing vector-quantized (VQ) tokens and incorporating CLIP-level semantics while enabling end-to-end multimodal autoregressive training with standard VQ tokens. TokLIP integrates a low-level discrete VQ tokenizer with a ViT-based token encoder to capture high-level continuous semantics. Unlike previous approaches (e.g., VILA-U) that discretize high-level features, TokLIP disentangles training objectives for comprehension and generation, allowing the direct application of advanced VQ tokenizers without the need for tailored quantization operations. Our empirical results demonstrate that TokLIP achieves exceptional data efficiency, empowering visual tokens with high-level semantic understanding while enhancing low-level generative capacity, making it well-suited for autoregressive Transformers in both comprehension and generation tasks. The code and models are available at https://github.com/TencentARC/TokLIP.