Visual Affordance Prediction: Survey and Reproducibility
作者: Tommaso Apicella, Alessio Xompero, Andrea Cavallaro
分类: cs.CV, cs.RO
发布日期: 2025-05-08 (更新: 2025-10-13)
备注: 18 pages, 3 figures, 13 tables. Project website at https://apicis.github.io/aff-survey/
💡 一句话要点
统一视觉可供性预测框架,解决定义不一致和可复现性问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉可供性 可供性预测 机器人操作 可复现性 统一框架
📋 核心要点
- 现有视觉可供性预测方法在任务定义上存在差异,缺乏统一的框架,导致方法间难以公平比较。
- 论文提出了统一的视觉可供性预测框架,整合了物体信息和智能体交互信息,便于系统性地分析现有方法。
- 论文强调了可复现性的重要性,并提出了Affordance Sheet,旨在提高研究透明度和促进公平的基准测试。
📝 摘要(中文)
本文针对相机视角下智能体与物体交互的视觉可供性预测问题,指出抓取检测、可供性分类、可供性分割和手势估计等任务中,可供性预测存在定义不一致的问题,阻碍了方法间的公平比较。为此,本文提出了一个统一的视觉可供性预测框架,考虑了目标物体的完整信息以及智能体与物体的交互。该框架支持全面系统地回顾不同的视觉可供性研究,突出方法和数据集的优缺点。此外,本文还讨论了可复现性问题,例如方法实现和实验设置细节的缺失,导致视觉可供性预测的基准测试不公平且不可靠。为了提高透明度,本文引入了Affordance Sheet,详细记录了方法、数据集和验证信息,以支持未来的可复现性和公平性。
🔬 方法详解
问题定义:视觉可供性预测旨在预测智能体与物体交互的可能性。现有方法在不同任务(如抓取检测、可供性分类等)中对可供性进行了不同的定义,导致评估标准不一致,难以进行公平比较。此外,许多研究缺乏足够的实现细节和实验设置信息,使得结果难以复现。
核心思路:论文的核心思路是提出一个统一的视觉可供性预测框架,该框架能够整合物体本身的完整信息以及智能体与物体交互的信息,从而为各种可供性预测任务提供一个通用的基础。同时,论文强调了可复现性的重要性,并提出了Affordance Sheet来记录实验细节。
技术框架:论文提出的框架并非一个具体的模型架构,而是一个概念性的框架,旨在统一不同可供性预测任务的输入和输出表示。该框架强调需要同时考虑物体的几何、材质等属性以及智能体的姿态、动作等信息。具体实现时,可以采用各种现有的深度学习模型作为骨干网络,例如卷积神经网络、Transformer等。
关键创新:该论文的关键创新在于提出了一个统一的视觉可供性预测框架,并强调了可复现性的重要性。虽然没有提出新的模型架构,但通过统一的框架,可以更好地理解和比较不同的可供性预测方法。Affordance Sheet的提出也有助于提高研究的透明度和可复现性。
关键设计:Affordance Sheet是论文中的一个关键设计,它是一个文档模板,用于记录方法的详细信息,包括模型架构、数据集、训练细节、评估指标等。通过Affordance Sheet,可以方便其他研究者复现实验结果,并进行公平的比较。
🖼️ 关键图片

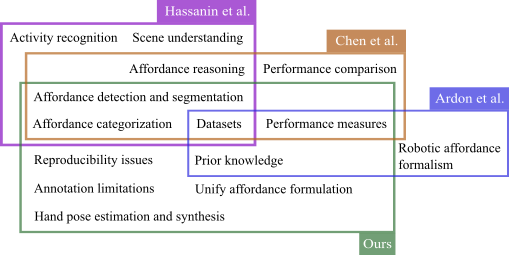
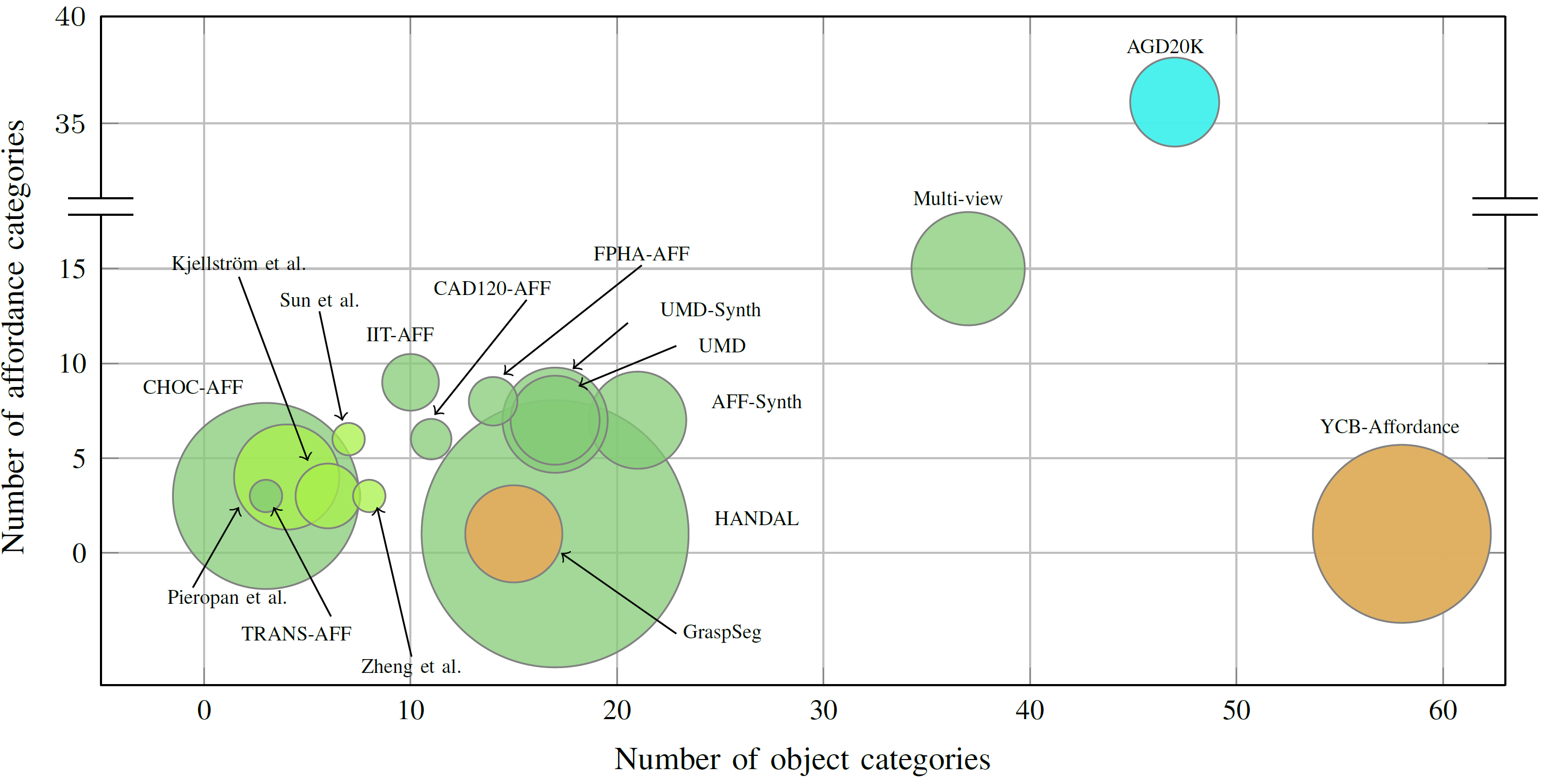
📊 实验亮点
论文的主要贡献在于提出了一个统一的视觉可供性预测框架,并强调了可复现性的重要性。虽然没有提供具体的性能数据,但通过对现有方法的系统性回顾,指出了不同方法和数据集的优缺点,为未来的研究方向提供了指导。Affordance Sheet的提出也有助于提高研究的透明度和可复现性,促进该领域的发展。
🎯 应用场景
该研究成果可应用于机器人操作、人机交互、自动驾驶等领域。例如,在机器人操作中,可供性预测可以帮助机器人理解物体的功能和交互方式,从而更好地完成抓取、放置等任务。在人机交互中,可供性预测可以帮助系统理解用户的意图,提供更自然、更智能的交互体验。在自动驾驶中,可供性预测可以帮助车辆理解周围环境,预测其他车辆和行人的行为。
📄 摘要(原文)
Affordances are the potential actions an agent can perform on an object, as observed by a camera. Visual affordance prediction is formulated differently for tasks such as grasping detection, affordance classification, affordance segmentation, and hand pose estimation. This diversity in formulations leads to inconsistent definitions that prevent fair comparisons between methods. In this paper, we propose a unified formulation of visual affordance prediction by accounting for the complete information on the objects of interest and the interaction of the agent with the objects to accomplish a task. This unified formulation allows us to comprehensively and systematically review disparate visual affordance works, highlighting strengths and limitations of both methods and datasets. We also discuss reproducibility issues, such as the unavailability of methods implementation and experimental setups details, making benchmarks for visual affordance prediction unfair and unreliable. To favour transparency, we introduce the Affordance Sheet, a document that details the solution, datasets, and validation of a method, supporting future reproducibility and fairness in the community.