OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
作者: Xianhang Li, Yanqing Liu, Haoqin Tu, Hongru Zhu, Cihang Xie
分类: cs.CV
发布日期: 2025-05-07
💡 一句话要点
OpenVision:全开放、高性价比的视觉编码器,用于多模态学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉编码器 多模态学习 对比学习 开放模型 CLIP LLaVA Transformer 计算机视觉
📋 核心要点
- 现有视觉编码器(如CLIP)在多模态学习中表现出色,但其训练数据和训练方法通常不完全开放,限制了研究和应用。
- OpenVision旨在提供一个完全开放且高性价比的视觉编码器系列,通过借鉴现有工作并进行改进,实现与或超过CLIP的性能。
- OpenVision提供了不同参数规模的视觉编码器,允许在多模态模型的性能和效率之间进行权衡,适用于不同的部署场景。
📝 摘要(中文)
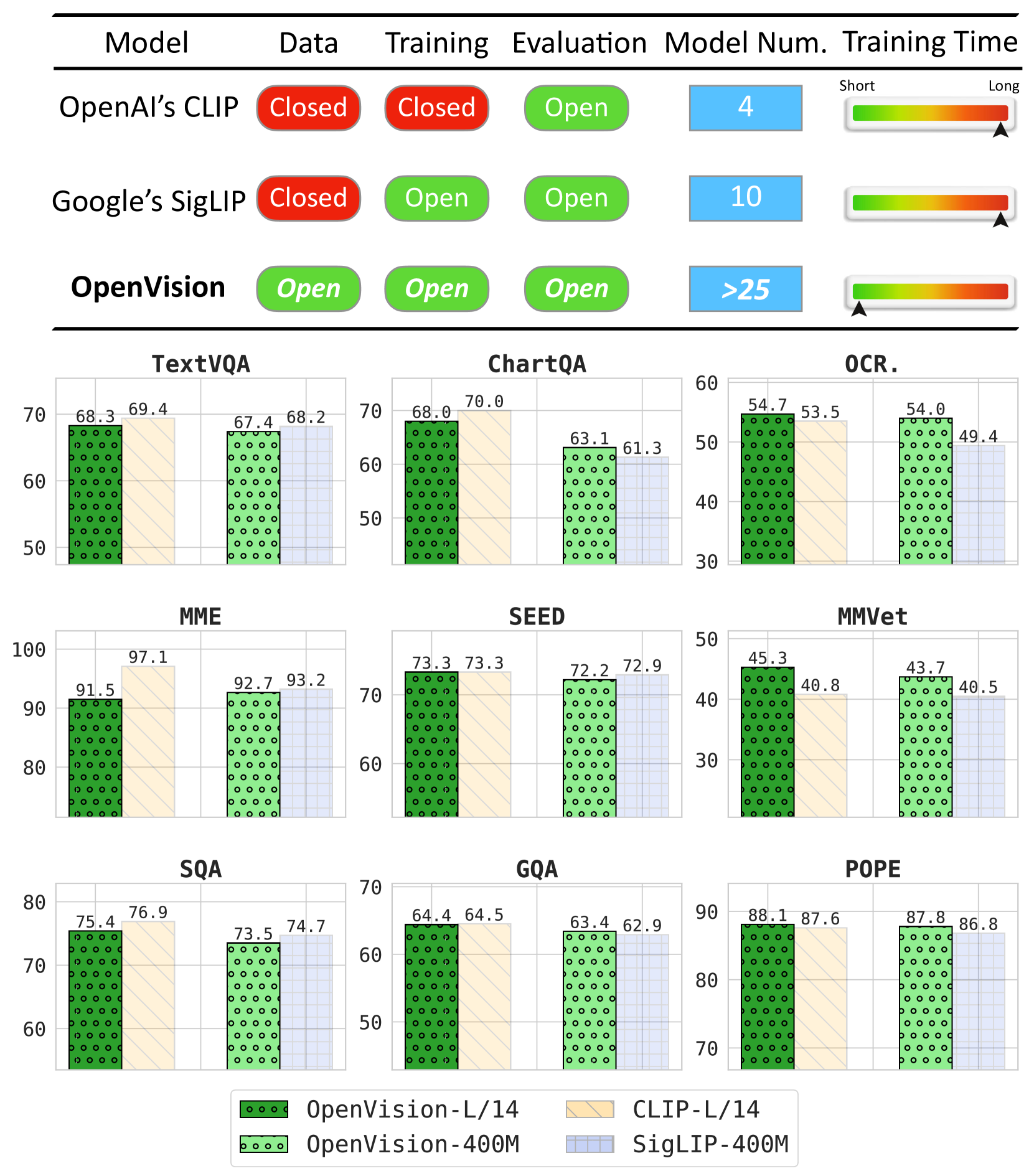
OpenAI的CLIP模型自2021年初发布以来,一直是构建多模态基础模型的首选视觉编码器。尽管最近出现了诸如SigLIP等替代方案,但据我们所知,没有一个是完全开放的:它们的训练数据仍然是专有的,并且/或者它们的训练方法没有发布。本文通过OpenVision填补了这一空白,OpenVision是一个完全开放、高性价比的视觉编码器系列,当集成到像LLaVA这样的多模态框架中时,其性能与OpenAI的CLIP相匹配或超过了CLIP。OpenVision建立在现有工作的基础上——例如,用于训练框架的CLIPS和用于训练数据的Recap-DataComp-1B——同时揭示了增强编码器质量的多个关键见解,并展示了在推进多模态模型方面的实际好处。通过发布参数量从5.9M到632.1M的视觉编码器,OpenVision为从业者在构建多模态模型时提供了容量和效率之间的灵活权衡:较大的模型提供增强的多模态性能,而较小的版本则支持轻量级、边缘就绪的多模态部署。
🔬 方法详解
问题定义:当前多模态学习领域依赖的视觉编码器,如OpenAI的CLIP,虽然性能优异,但其训练数据和训练流程并未完全开源。这限制了研究人员深入理解其工作原理,也阻碍了在资源受限场景下的应用。因此,需要一个完全开放、高性价比的视觉编码器,以促进多模态学习的进一步发展。
核心思路:OpenVision的核心思路是构建一个完全开放的视觉编码器家族,通过复现和改进现有先进方法(如CLIP)的训练流程,并利用大规模公开数据集(如Recap-DataComp-1B)进行训练,从而在保证性能的同时,实现完全的透明性和可复现性。这样可以促进研究人员对视觉编码器内部机制的理解,并降低使用门槛。
技术框架:OpenVision的技术框架主要包括数据准备、模型训练和模型评估三个阶段。数据准备阶段主要负责清洗和预处理Recap-DataComp-1B等大规模数据集。模型训练阶段采用对比学习框架,借鉴CLIP的训练方式,并进行改进。模型评估阶段则将训练好的视觉编码器集成到多模态模型(如LLaVA)中,评估其在下游任务上的性能。
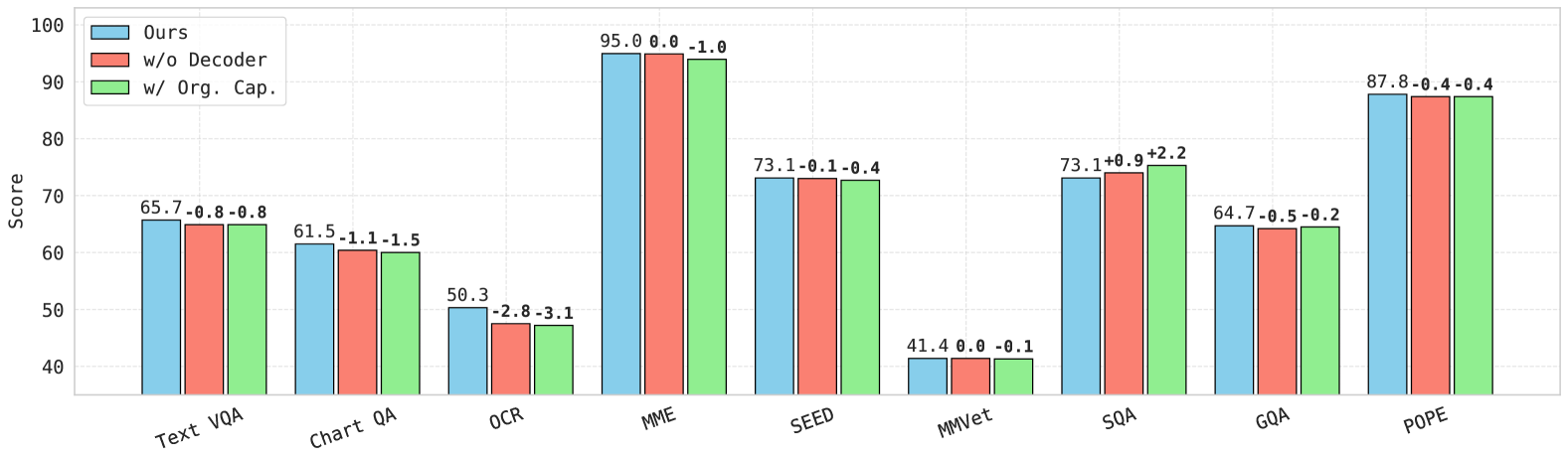
关键创新:OpenVision的关键创新在于其完全开放性。与现有方法相比,OpenVision不仅开源了模型权重,还公开了训练数据和训练流程,使得研究人员可以完全复现和改进该模型。此外,OpenVision还通过实验揭示了提升视觉编码器质量的关键因素,例如数据增强策略和模型结构选择。
关键设计:OpenVision采用了Transformer架构作为视觉编码器的基础结构,并探索了不同的模型规模(从5.9M到632.1M参数)。在训练过程中,采用了对比学习损失函数,并使用了多种数据增强技术,如随机裁剪、颜色抖动等。此外,OpenVision还对学习率、batch size等超参数进行了精细调整,以获得最佳性能。
🖼️ 关键图片
📊 实验亮点
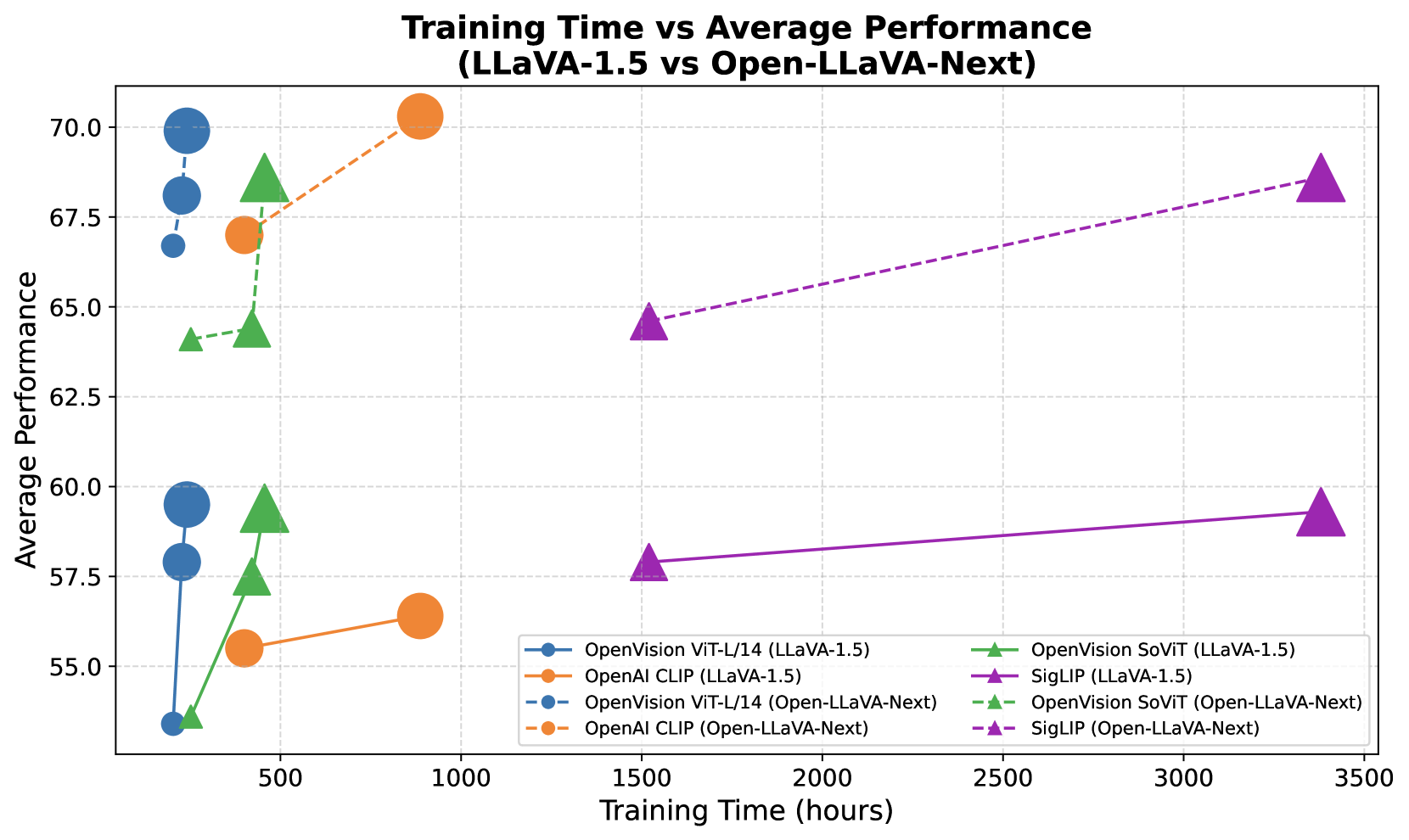
OpenVision在多个多模态任务上取得了与或超过OpenAI CLIP的性能。例如,在LLaVA框架下,OpenVision的性能与CLIP相当,同时保持了完全开放性。此外,OpenVision还提供了不同参数规模的模型,允许在性能和效率之间进行权衡,满足不同应用场景的需求。
🎯 应用场景
OpenVision在多模态学习领域具有广泛的应用前景,例如图像描述生成、视觉问答、跨模态检索等。其完全开放的特性使得研究人员可以更容易地对其进行定制和改进,以适应不同的应用场景。此外,OpenVision还可以在边缘设备上部署,实现轻量级、低功耗的多模态应用,例如智能监控、机器人导航等。
📄 摘要(原文)
OpenAI's CLIP, released in early 2021, have long been the go-to choice of vision encoder for building multimodal foundation models. Although recent alternatives such as SigLIP have begun to challenge this status quo, to our knowledge none are fully open: their training data remains proprietary and/or their training recipes are not released. This paper fills this gap with OpenVision, a fully-open, cost-effective family of vision encoders that match or surpass the performance of OpenAI's CLIP when integrated into multimodal frameworks like LLaVA. OpenVision builds on existing works -- e.g., CLIPS for training framework and Recap-DataComp-1B for training data -- while revealing multiple key insights in enhancing encoder quality and showcasing practical benefits in advancing multimodal models. By releasing vision encoders spanning from 5.9M to 632.1M parameters, OpenVision offers practitioners a flexible trade-off between capacity and efficiency in building multimodal models: larger models deliver enhanced multimodal performance, while smaller versions enable lightweight, edge-ready multimodal deployments.