RAFT -- A Domain Adaptation Framework for RGB & LiDAR Semantic Segmentation
作者: Edward Humes, Xiaomin Lin, Boxun Hu, Rithvik Jonna, Tinoosh Mohsenin
分类: cs.CV
发布日期: 2025-05-07 (更新: 2025-11-11)
备注: Submitted to RA-L
💡 一句话要点
提出RAFT框架,通过数据增强和主动学习,提升RGB-LiDAR语义分割的域适应性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语义分割 域适应 数据增强 主动学习 RGB-LiDAR 深度学习 计算机视觉
📋 核心要点
- 现有图像分割模型在真实场景部署时,受限于真实数据标注成本高昂和合成数据与真实数据存在gap的问题。
- RAFT框架的核心思想是利用数据增强、特征增强和主动学习,以最小的真实数据标注成本,实现有效的域适应。
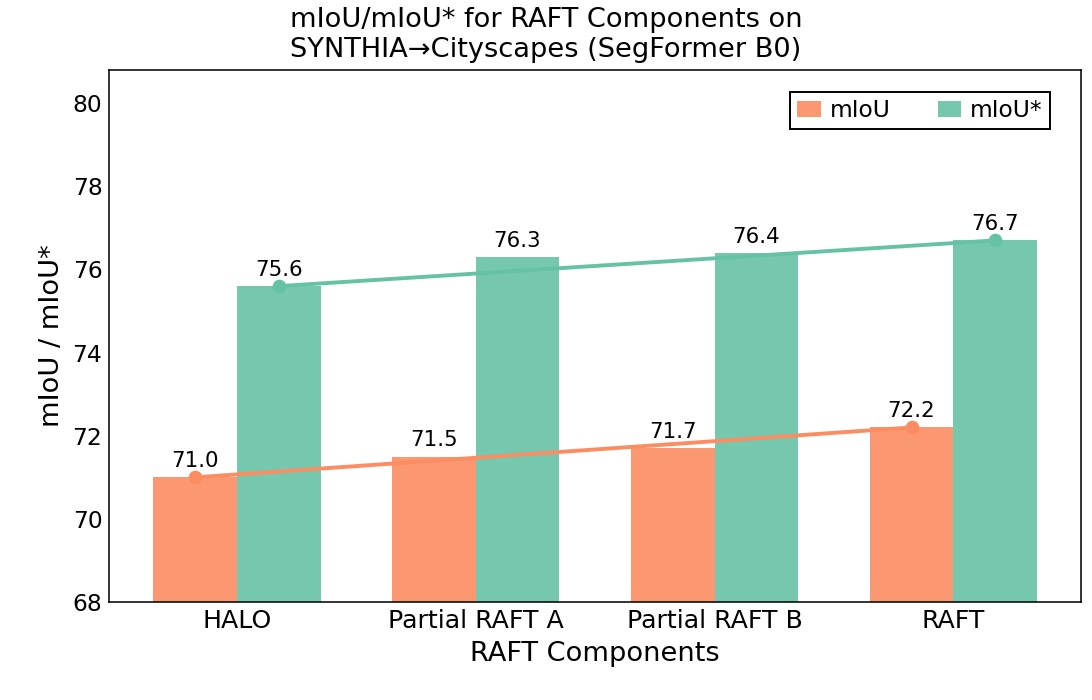
- 实验结果表明,RAFT在多个合成到真实以及真实到真实的分割数据集上,均超越了现有最佳方法HALO。
📝 摘要(中文)
图像分割是场景理解中一项强大的计算机视觉技术。然而,真实世界的部署受到高质量、精细标注数据集需求的阻碍。合成数据提供了高质量的标签,减少了手动数据收集和标注的需求。但是,在合成数据上训练的深度神经网络通常面临Syn2Real问题,导致在真实世界部署中性能不佳。为了缓解图像分割中的上述差距,我们提出了一种新的框架RAFT,该框架通过数据和特征增强以及主动学习,使用最少的标记真实世界数据来调整图像分割模型。为了验证RAFT,我们在synthetic-to-real的“SYNTHIA->Cityscapes”和“GTAV->Cityscapes”基准上进行了实验。我们成功地超越了先前的最先进水平HALO。SYNTHIA->Cityscapes在域适应后的mIoU*提高了2.1%/79.9%,GTAV->Cityscapes的mIoU提高了0.4%/78.2%。此外,我们在“Cityscapes->ACDC”的real-to-real基准上测试了我们的方法,并再次超越了HALO,适应后的mIoU增益为1.3%/73.2%。最后,我们研究了分配的标注预算和RAFT的各种组件对最终迁移mIoU的影响。
🔬 方法详解
问题定义:论文旨在解决RGB和LiDAR数据的语义分割任务中,模型从合成数据迁移到真实数据时性能下降的问题,即Syn2Real问题。现有方法通常需要大量的真实数据进行微调,成本高昂,或者域适应效果不佳。
核心思路:RAFT框架的核心思路是通过数据增强、特征增强和主动学习相结合的方式,尽可能利用有限的真实数据,提升模型在目标域上的泛化能力。数据增强和特征增强旨在缩小源域和目标域之间的差距,而主动学习则用于选择最有价值的样本进行标注,从而提高标注效率。
技术框架:RAFT框架包含以下几个主要模块:1) 数据增强模块:对源域和目标域数据进行多种增强,例如颜色抖动、几何变换等。2) 特征增强模块:在特征空间进行增强,例如对抗训练或风格迁移。3) 主动学习模块:根据模型的不确定性或多样性指标,选择最有价值的样本进行标注。4) 分割模型:使用现有的分割模型作为backbone,例如DeepLabv3+。整个流程是先使用合成数据预训练模型,然后利用少量真实数据,通过数据增强、特征增强和主动学习进行域适应。
关键创新:RAFT的关键创新在于将数据增强、特征增强和主动学习有机结合,形成一个完整的域适应框架。这种结合能够更有效地利用有限的真实数据,提升模型在目标域上的性能。此外,RAFT框架具有较强的通用性,可以应用于不同的分割模型和数据集。
关键设计:在数据增强方面,论文采用了多种常用的增强方法,例如随机裁剪、翻转、颜色抖动等。在特征增强方面,论文可能采用了对抗训练或风格迁移等方法,具体细节未知。在主动学习方面,论文可能使用了不确定性采样或委员会查询等策略,具体细节未知。损失函数方面,论文可能使用了交叉熵损失或Dice损失等常用的分割损失函数,具体细节未知。
🖼️ 关键图片


📊 实验亮点
RAFT在SYNTHIA->Cityscapes和GTAV->Cityscapes基准测试中,mIoU分别提升了2.1%/79.9%和0.4%/78.2%,超越了之前的state-of-the-art方法HALO。在Cityscapes->ACDC的real-to-real基准测试中,mIoU提升了1.3%/73.2%,也超越了HALO。这些结果表明RAFT在域适应方面具有显著优势。
🎯 应用场景
RAFT框架可应用于自动驾驶、机器人导航、遥感图像分析等领域,这些领域通常需要精确的场景理解,但获取大量标注数据成本高昂。通过RAFT,可以使用合成数据进行预训练,然后利用少量真实数据进行微调,从而降低标注成本,加速模型部署。
📄 摘要(原文)
Image segmentation is a powerful computer vision technique for scene understanding. However, real-world deployment is stymied by the need for high-quality, meticulously labeled datasets. Synthetic data provides high-quality labels while reducing the need for manual data collection and annotation. However, deep neural networks trained on synthetic data often face the Syn2Real problem, leading to poor performance in real-world deployments. To mitigate the aforementioned gap in image segmentation, we propose RAFT, a novel framework for adapting image segmentation models using minimal labeled real-world data through data and feature augmentations, as well as active learning. To validate RAFT, we perform experiments on the synthetic-to-real "SYNTHIA->Cityscapes" and "GTAV->Cityscapes" benchmarks. We managed to surpass the previous state of the art, HALO. SYNTHIA->Cityscapes experiences an improvement in mIoU* upon domain adaptation of 2.1%/79.9%, and GTAV->Cityscapes experiences a 0.4%/78.2% improvement in mIoU. Furthermore, we test our approach on the real-to-real benchmark of "Cityscapes->ACDC", and again surpass HALO, with a gain in mIoU upon adaptation of 1.3%/73.2%. Finally, we examine the effect of the allocated annotation budget and various components of RAFT upon the final transfer mIoU.