Blending 3D Geometry and Machine Learning for Multi-View Stereopsis
作者: Vibhas Vats, Md. Alimoor Reza, David Crandall, Soon-heung Jung
分类: cs.CV, cs.AI, cs.CG, cs.LG
发布日期: 2025-05-06 (更新: 2025-09-14)
备注: A pre-print -- accepted at Neurocomputing. arXiv admin note: substantial text overlap with arXiv:2310.19583
期刊: Neurocomputing, 2025
💡 一句话要点
提出GC MVSNet++,通过多视角多尺度几何一致性约束加速多视角立体匹配学习。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 多视角立体匹配 几何一致性 深度学习 三维重建 代价体正则化
📋 核心要点
- 传统MVS方法依赖光度与几何一致性,学习方法则在后处理阶段进行几何一致性检查,缺乏对学习过程的指导。
- GC MVSNet++在学习阶段主动强制多视角、多尺度的几何一致性,通过惩罚不一致像素加速学习。
- 实验表明,该方法在DTU和BlendedMVS数据集上达到SOTA,并在Tanks and Temples基准测试中获得第二名。
📝 摘要(中文)
传统的多视角立体匹配(MVS)方法主要依赖于光度一致性和几何一致性约束。相比之下,现代基于学习的算法通常依赖于平面扫描算法来推断3D几何,仅在后处理步骤中应用显式的几何一致性(GC)检查,而对学习过程本身没有影响。本文提出GC MVSNet++,一种新颖的方法,在学习阶段主动地在多个源视图(多视角)和多个尺度(多尺度)上强制参考视图深度图的几何一致性。这种集成的GC检查通过直接惩罚几何不一致的像素,显著加速了学习过程,有效地将训练迭代次数减少了一半。此外,我们引入了一个具有两种不同块设计(简单和特征密集)的密集连接成本正则化网络,该网络经过优化,可以利用密集特征连接来增强正则化。大量实验表明,我们的方法在DTU和BlendedMVS数据集上取得了新的state-of-the-art,并在Tanks and Temples基准测试中获得了第二名。据我们所知,GC MVSNet++是第一种在学习过程中强制执行多视角、多尺度监督几何一致性的方法。我们的代码已开源。
🔬 方法详解
问题定义:论文旨在解决多视角立体匹配(MVS)中,现有学习方法对几何一致性利用不足的问题。现有方法通常在后处理阶段才进行几何一致性检查,无法在学习过程中指导深度图的优化,导致训练效率低下,且容易陷入局部最优。
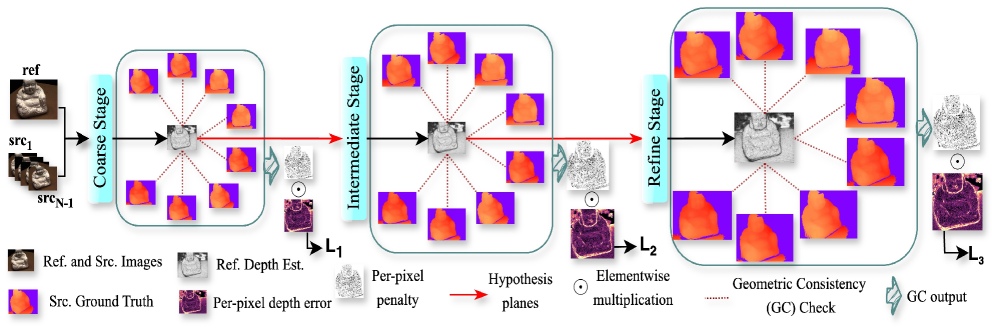
核心思路:论文的核心思路是在学习过程中主动地、显式地强制执行多视角、多尺度的几何一致性约束。通过在损失函数中引入几何一致性损失,直接惩罚几何不一致的像素,从而引导网络学习更准确的深度图。这种方法将几何信息融入到学习过程中,加速了训练,并提高了深度图的质量。
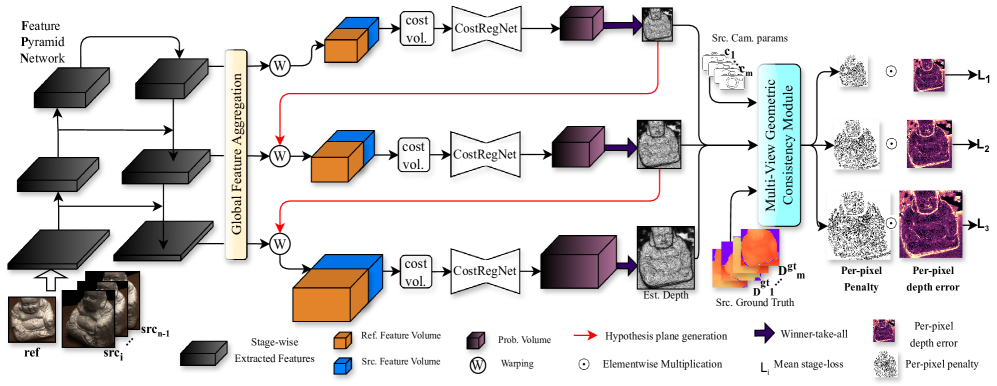
技术框架:GC MVSNet++的整体框架基于MVSNet,主要包括以下几个模块:1. 特征提取网络:从参考图像和源图像中提取特征。2. 代价体构建:基于平面扫描算法构建代价体。3. 代价体正则化:使用密集连接的成本正则化网络对代价体进行正则化。4. 深度图估计:从正则化后的代价体中估计深度图。5. 几何一致性检查:在多个源视图和多个尺度上检查深度图的几何一致性。6. 损失函数计算:计算光度损失和几何一致性损失,并进行反向传播。
关键创新:最重要的技术创新点是在学习过程中引入了多视角、多尺度的监督几何一致性约束。具体来说,论文通过将参考视图的深度图投影到其他源视图,并计算投影后的深度图与源视图深度图之间的差异,来衡量几何一致性。这种方法能够有效地利用多视角信息,提高深度图的准确性和鲁棒性。此外,论文还提出了一个密集连接的成本正则化网络,该网络能够更好地利用特征之间的相关性,提高正则化效果。
关键设计:论文的关键设计包括:1. 多尺度几何一致性损失:在多个尺度上计算几何一致性损失,以提高对不同尺度几何误差的敏感性。2. 密集连接的成本正则化网络:采用两种不同的块设计(简单和特征密集)来优化网络结构,以更好地利用特征之间的相关性。3. 损失函数权重:平衡光度损失和几何一致性损失的权重,以获得最佳的性能。
🖼️ 关键图片

📊 实验亮点
GC MVSNet++在DTU和BlendedMVS数据集上取得了新的state-of-the-art,并在Tanks and Temples基准测试中获得了第二名。与现有方法相比,该方法能够显著减少训练迭代次数(减少一半),并提高深度图的精度。例如,在DTU数据集上,该方法的精度指标优于其他方法。
🎯 应用场景
该研究成果可应用于三维重建、自动驾驶、机器人导航、虚拟现实等领域。高质量的深度图对于这些应用至关重要。通过提高深度图的精度和鲁棒性,可以提升相关应用的性能和用户体验。未来,该方法可以进一步扩展到动态场景的三维重建,以及与其他传感器(如激光雷达)的融合。
📄 摘要(原文)
Traditional multi-view stereo (MVS) methods primarily depend on photometric and geometric consistency constraints. In contrast, modern learning-based algorithms often rely on the plane sweep algorithm to infer 3D geometry, applying explicit geometric consistency (GC) checks only as a post-processing step, with no impact on the learning process itself. In this work, we introduce GC MVSNet plus plus, a novel approach that actively enforces geometric consistency of reference view depth maps across multiple source views (multi view) and at various scales (multi scale) during the learning phase (see Fig. 1). This integrated GC check significantly accelerates the learning process by directly penalizing geometrically inconsistent pixels, effectively halving the number of training iterations compared to other MVS methods. Furthermore, we introduce a densely connected cost regularization network with two distinct block designs simple and feature dense optimized to harness dense feature connections for enhanced regularization. Extensive experiments demonstrate that our approach achieves a new state of the art on the DTU and BlendedMVS datasets and secures second place on the Tanks and Temples benchmark. To our knowledge, GC MVSNet plus plus is the first method to enforce multi-view, multi-scale supervised geometric consistency during learning. Our code is available.