Using Knowledge Graphs to harvest datasets for efficient CLIP model training
作者: Simon Ging, Sebastian Walter, Jelena Bratulić, Johannes Dienert, Hannah Bast, Thomas Brox
分类: cs.CV, cs.CL, cs.IR, cs.LG
发布日期: 2025-05-05 (更新: 2025-09-30)
备注: Accepted for oral presentation at GCPR 2025 (German Conference on Pattern Recognition). This is the version submitted to the conference, not the official conference proceedings
💡 一句话要点
利用知识图谱增强数据收集,高效训练CLIP模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CLIP模型 知识图谱 数据收集 领域特定模型 对比学习 多模态学习 EntityNet数据集
📋 核心要点
- 现有CLIP模型训练依赖海量数据,限制了领域特定模型的开发和应用,增加了训练成本。
- 论文提出利用知识图谱增强的网络搜索策略,更高效地收集高质量训练数据,降低数据需求。
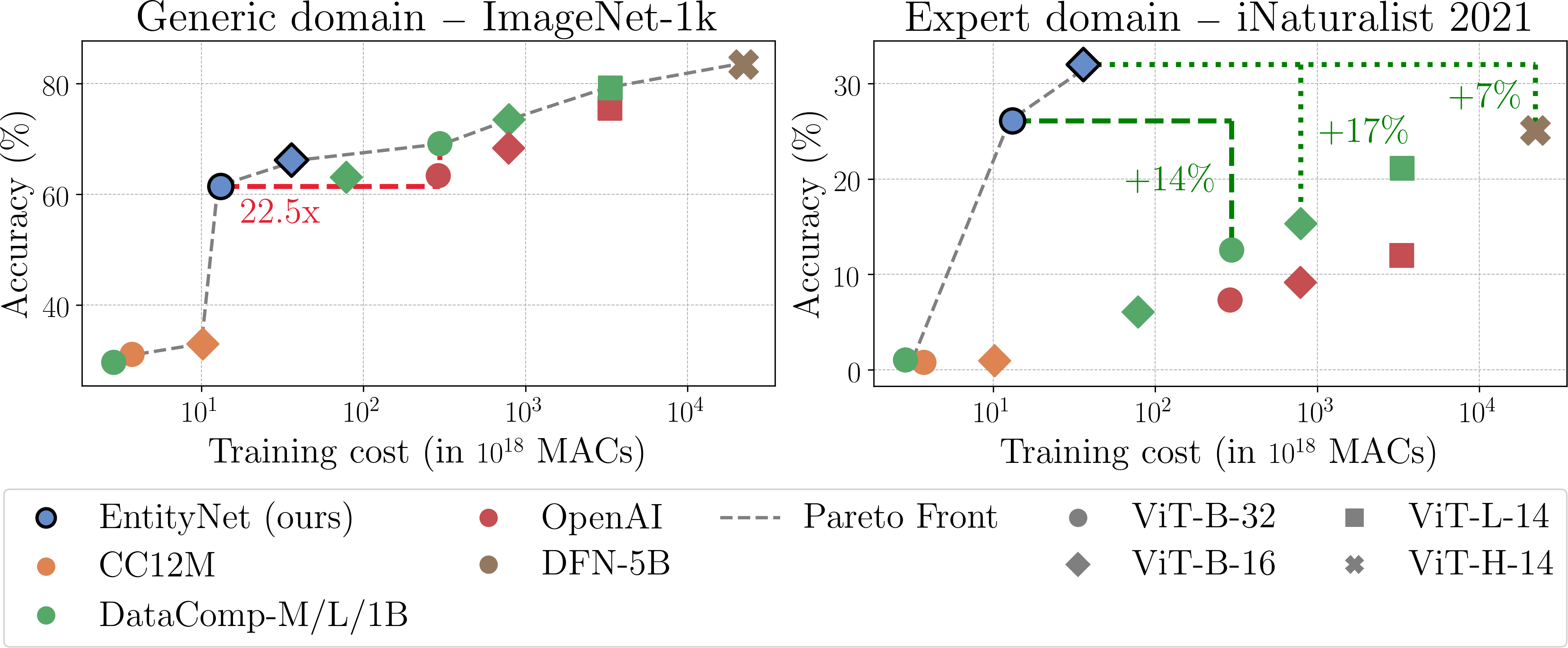
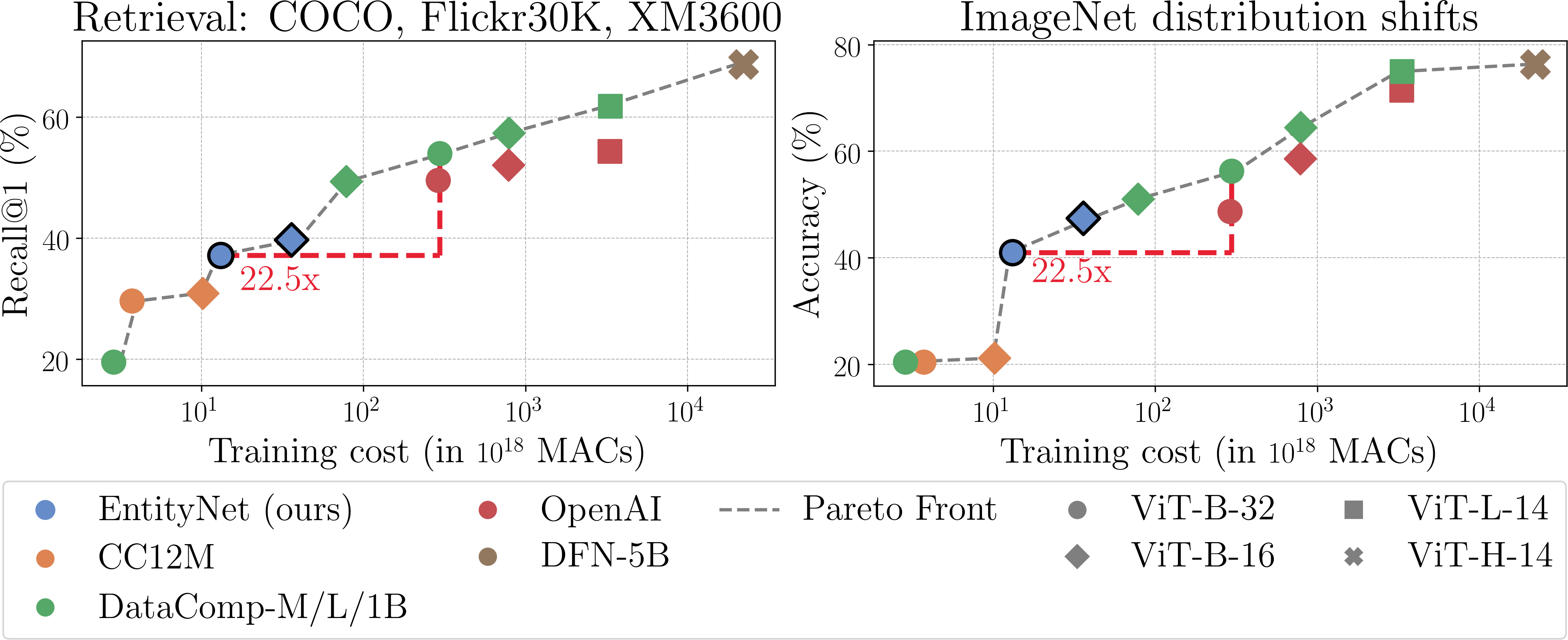
- 实验证明,仅用1000万张图像即可训练生物体专家CLIP模型,并发布包含3300万图像的EntityNet数据集。
📝 摘要(中文)
高质量CLIP模型的训练通常需要庞大的数据集,这限制了领域特定模型的发展,尤其是在大型CLIP模型覆盖不足的领域,并增加了训练成本。这给需要对CLIP模型训练过程进行细粒度控制的科学研究带来了挑战。本文表明,通过采用知识图谱增强的智能网络搜索策略,可以用更少的数据从头开始训练一个鲁棒的CLIP模型。具体来说,我们证明了仅使用1000万张图像就可以构建一个生物体专家基础模型。此外,我们还引入了EntityNet数据集,该数据集包含3300万张图像和4600万个文本描述,从而能够以显著减少的时间训练通用CLIP模型。
🔬 方法详解
问题定义:现有CLIP模型训练需要大量数据,这使得在数据稀缺的领域(例如特定生物物种)训练专业模型变得困难。此外,对训练过程的细粒度控制也受到限制,阻碍了科学研究。
核心思路:利用知识图谱来指导网络搜索,从而更有效地收集与目标领域相关的图像和文本数据。知识图谱可以提供实体之间的关系信息,帮助搜索算法找到更准确、更全面的训练数据。
技术框架:该方法的核心在于使用知识图谱来增强网络搜索策略。具体流程可能包括:1) 定义目标领域相关的实体和关系;2) 使用这些实体和关系构建查询语句;3) 利用查询语句进行网络搜索,收集图像和文本数据;4) 对收集到的数据进行清洗和过滤,构建训练数据集。此外,论文还提出了EntityNet数据集,用于通用CLIP模型的训练。
关键创新:关键创新在于将知识图谱引入到CLIP模型的训练数据收集过程中。与传统的随机或基于关键词的搜索方法相比,基于知识图谱的搜索能够更准确地定位到与目标领域相关的图像和文本数据,从而提高训练效率。
关键设计:论文中可能涉及的关键设计包括:1) 如何构建和利用知识图谱;2) 如何设计查询语句,以最大程度地利用知识图谱中的信息;3) 如何对收集到的数据进行清洗和过滤,以保证数据的质量;4) EntityNet数据集的构建细节,包括图像和文本数据的来源、标注方式等。具体的损失函数和网络结构可能与标准的CLIP模型保持一致。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用知识图谱增强的数据收集方法,仅用1000万张图像即可训练出一个生物体专家CLIP模型,性能优于使用传统方法训练的模型。此外,EntityNet数据集的发布,为通用CLIP模型的训练提供了新的资源,可以显著减少训练时间。
🎯 应用场景
该研究成果可应用于多个领域,例如:生物多样性保护(训练特定物种的识别模型)、医学图像分析(训练特定疾病的诊断模型)、以及其他数据稀缺的专业领域。通过降低CLIP模型的训练成本和数据需求,可以促进领域特定模型的开发和应用,从而推动相关领域的研究和发展。
📄 摘要(原文)
Training high-quality CLIP models typically requires enormous datasets, which limits the development of domain-specific models -- especially in areas that even the largest CLIP models do not cover well -- and drives up training costs. This poses challenges for scientific research that needs fine-grained control over the training procedure of CLIP models. In this work, we show that by employing smart web search strategies enhanced with knowledge graphs, a robust CLIP model can be trained from scratch with considerably less data. Specifically, we demonstrate that an expert foundation model for living organisms can be built using just 10M images. Moreover, we introduce EntityNet, a dataset comprising 33M images paired with 46M text descriptions, which enables the training of a generic CLIP model in significantly reduced time.