Multimodal Deep Learning for Stroke Prediction and Detection using Retinal Imaging and Clinical Data
作者: Saeed Shurrab, Aadim Nepal, Terrence J. Lee-St. John, Nicola G. Ghazi, Bartlomiej Piechowski-Jozwiak, Farah E. Shamout
分类: eess.IV, cs.CV
发布日期: 2025-05-05 (更新: 2025-12-16)
DOI: 10.1109/EMBC58623.2025.11253814
💡 一句话要点
提出基于视网膜影像和临床数据的多模态深度学习方法,用于卒中预测和检测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 卒中预测 多模态学习 视网膜影像 深度学习 自监督学习 临床数据融合 风险评估
📋 核心要点
- 现有卒中预测方法依赖于昂贵的CT等医学影像,限制了其大规模应用和普及。
- 提出一种多模态深度学习框架,融合OCT、红外视网膜扫描和临床数据,提升卒中预测能力。
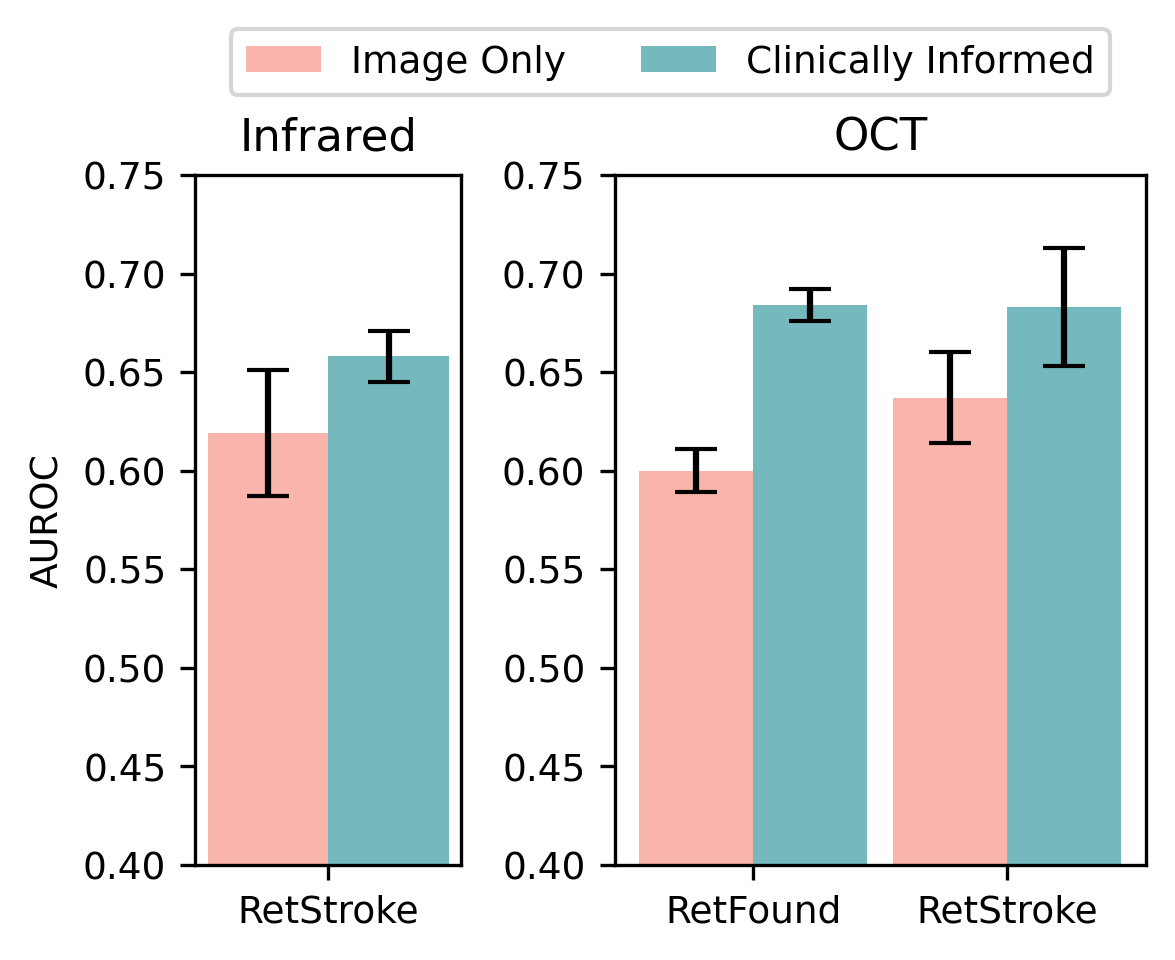
- 实验表明,该方法在卒中检测和风险预测方面优于单模态基线和现有SOTA模型,AUROC最高提升8%。
📝 摘要(中文)
卒中是全球性的重大公共卫生问题。深度学习在卒中诊断和风险预测方面展现出潜力。然而,现有方法依赖于昂贵的医学影像,如计算机断层扫描。由于视网膜和大脑之间存在共同的临床通路,视网膜影像可能为脑血管健康评估提供一种经济有效的替代方案。本研究探索了利用视网膜图像和临床数据进行卒中检测和风险预测的影响。我们提出了一种多模态深度神经网络,处理光学相干断层扫描(OCT)和红外反射视网膜扫描,并结合人口统计学、生命体征和诊断代码等临床数据。我们使用包含3.7万次扫描的真实世界数据集,通过自监督学习框架预训练模型,然后使用较小的标记子集对模型进行微调和评估。实验结果表明,所考虑的模态在检测与急性卒中相关的视网膜持久影响以及预测特定时间范围内的未来风险方面具有预测能力。与仅使用图像的单模态基线相比,我们的框架实现了5%的AUROC提升,与现有的最先进的基础模型相比,提升了8%。总之,我们的研究强调了视网膜影像在识别高风险患者和改善长期预后方面的潜力。
🔬 方法详解
问题定义:论文旨在解决卒中早期预测和检测问题,现有方法主要依赖于昂贵的CT等医学影像,难以大规模应用。同时,如何有效融合视网膜影像和临床数据以提升预测精度也是一个挑战。
核心思路:论文的核心思路是利用视网膜影像与大脑血管的关联性,结合易于获取的临床数据,构建一个多模态深度学习模型,从而实现低成本、高精度的卒中预测。这种方法旨在弥补现有方法对昂贵影像的依赖,并充分利用多源数据的信息互补性。
技术框架:整体框架包含以下几个主要阶段:1) 数据收集:收集包含OCT、红外视网膜扫描和临床数据的真实世界数据集。2) 自监督预训练:使用大规模无标签数据,通过自监督学习方法预训练模型,提升特征提取能力。3) 多模态融合:将视网膜影像和临床数据输入到深度神经网络中,进行特征提取和融合。4) 微调和评估:使用小规模标注数据对模型进行微调,并在测试集上评估模型的卒中预测性能。
关键创新:该论文的关键创新在于:1) 提出了一种基于视网膜影像和临床数据的多模态卒中预测框架,降低了对昂贵医学影像的依赖。2) 采用了自监督学习方法进行模型预训练,有效利用了大规模无标签数据。3) 实验结果表明,该方法在卒中检测和风险预测方面取得了显著的性能提升。
关键设计:论文中关于网络结构、损失函数和参数设置等技术细节没有详细描述,属于未知信息。但可以推测,多模态融合可能采用了注意力机制或特征拼接等方法,损失函数可能采用了交叉熵损失或Focal Loss等,以优化模型的分类性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在卒中检测和风险预测方面取得了显著的性能提升。与仅使用图像的单模态基线相比,该方法实现了5%的AUROC提升。与现有的最先进的基础模型相比,该方法实现了8%的AUROC提升,验证了多模态融合和自监督学习的有效性。
🎯 应用场景
该研究成果可应用于卒中高风险人群的早期筛查和风险评估,有助于实现卒中的早期干预和预防,降低卒中发病率和致残率。此外,该方法也可推广到其他脑血管疾病的预测和诊断,具有重要的临床应用价值和社会意义。
📄 摘要(原文)
Stroke is a major public health problem, affecting millions worldwide. Deep learning has recently demonstrated promise for enhancing the diagnosis and risk prediction of stroke. However, existing methods rely on costly medical imaging modalities, such as computed tomography. Recent studies suggest that retinal imaging could offer a cost-effective alternative for cerebrovascular health assessment due to the shared clinical pathways between the retina and the brain. Hence, this study explores the impact of leveraging retinal images and clinical data for stroke detection and risk prediction. We propose a multimodal deep neural network that processes Optical Coherence Tomography (OCT) and infrared reflectance retinal scans, combined with clinical data, such as demographics, vital signs, and diagnosis codes. We pretrained our model using a self-supervised learning framework using a real-world dataset consisting of $37$ k scans, and then fine-tuned and evaluated the model using a smaller labeled subset. Our empirical findings establish the predictive ability of the considered modalities in detecting lasting effects in the retina associated with acute stroke and forecasting future risk within a specific time horizon. The experimental results demonstrate the effectiveness of our proposed framework by achieving $5$\% AUROC improvement as compared to the unimodal image-only baseline, and $8$\% improvement compared to an existing state-of-the-art foundation model. In conclusion, our study highlights the potential of retinal imaging in identifying high-risk patients and improving long-term outcomes.