VAEmo: Efficient Representation Learning for Visual-Audio Emotion with Knowledge Injection
作者: Hao Cheng, Zhiwei Zhao, Yichao He, Zhenzhen Hu, Jia Li, Meng Wang, Richang Hong
分类: cs.CV, cs.SD
发布日期: 2025-05-05 (更新: 2025-08-02)
备注: Source code and pre-trained models will be available at https://github.com/MSA-LMC/VAEmo
💡 一句话要点
VAEmo:通过知识注入高效学习视觉-听觉情感表征,提升AVER性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视听情感识别 多模态学习 自监督学习 知识注入 对比学习 大型语言模型 情感计算
📋 核心要点
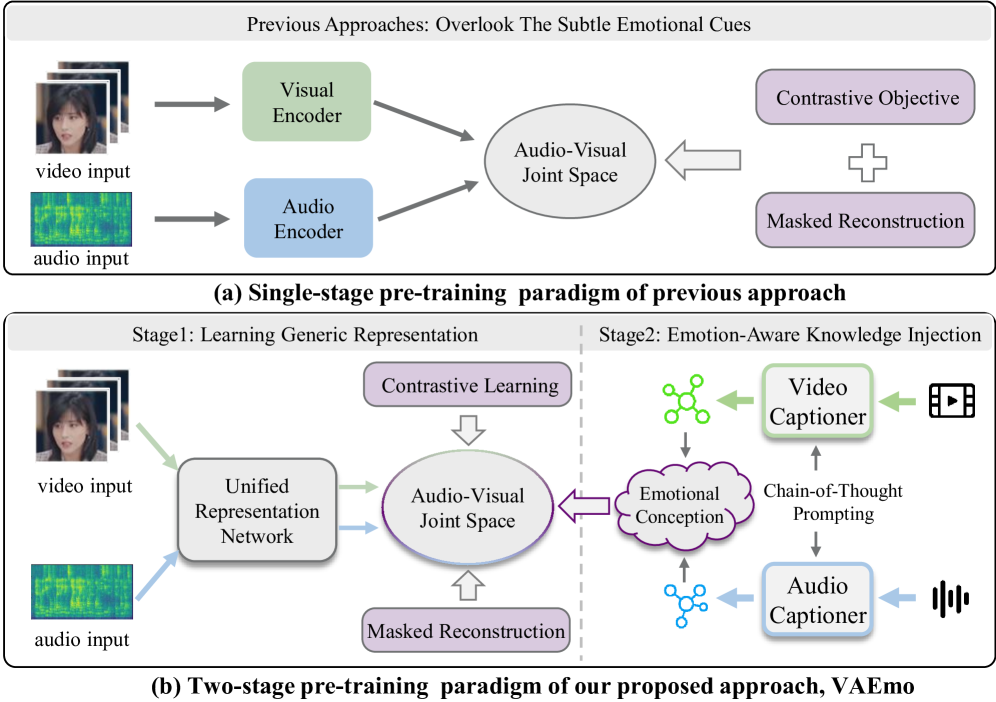
- 现有AVER方法依赖模态特定编码器和粗略内容对齐,难以进行细粒度情感语义建模,限制了性能。
- VAEmo提出两阶段框架,首先预训练统一轻量级网络学习互补表征,然后注入情感知识弥合差距。
- 实验表明,VAEmo在多个AVER基准上以紧凑设计实现了SOTA性能,验证了方法的有效性。
📝 摘要(中文)
视听情感识别(AVER)旨在从非语言的视觉-听觉(VA)线索中推断人类情感,具有模态互补和语言无关的优势。然而,情感表达的内在模糊性、跨模态表达差异以及可靠标注数据的稀缺性使得AVER仍然具有挑战性。最近的自监督AVER方法引入了强大的多模态表征,但它们主要依赖于模态特定的编码器和粗略的内容级对齐,限制了细粒度的情感语义建模。为了解决这些问题,我们提出了VAEmo,一个高效的两阶段框架,用于以情感为中心的联合VA表征学习,并注入外部知识。在第一阶段,通过掩码重建和对比目标,在大型以说话者为中心的VA语料库上预训练一个统一且轻量级的表征网络,从而缓解模态差距,并在没有情感标签的情况下学习富有表现力的互补表征。在第二阶段,多模态大型语言模型根据我们精心设计的思维链提示,自动生成详细的情感描述;然后,通过双路径对比学习将这些丰富的文本语义与相应的VA表征对齐,从而进一步弥合情感差距。在多个下游AVER基准上的大量实验表明,VAEmo以紧凑的设计实现了最先进的性能,突出了统一跨模态编码和情感感知语义指导对于高效、可泛化的VA情感表征的益处。
🔬 方法详解
问题定义:论文旨在解决视听情感识别(AVER)中情感表达模糊、跨模态差异以及标注数据稀缺带来的挑战。现有方法依赖于模态特定的编码器和粗略的内容级对齐,无法充分捕捉细粒度的情感语义信息,限制了模型的性能。
核心思路:论文的核心思路是分阶段学习视听情感表征,并注入外部知识来弥合模态和情感之间的差距。首先,通过自监督学习获得通用的视听表征,然后利用大型语言模型生成的情感描述作为知识,指导视听表征学习,从而提升情感识别的准确性。
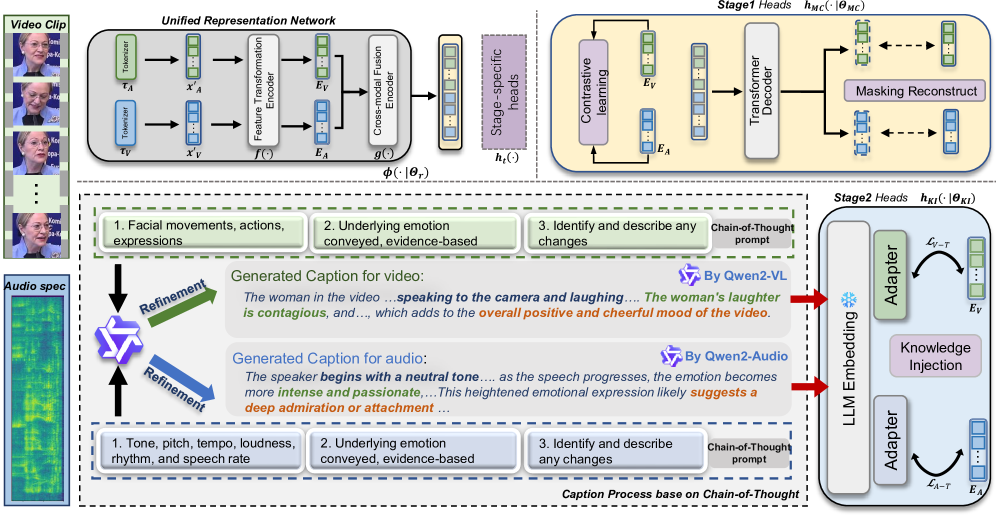
技术框架:VAEmo框架包含两个阶段:第一阶段是预训练阶段,使用统一的轻量级网络在大型视听语料库上进行自监督学习,包括掩码重建和对比学习,以学习模态互补的表征。第二阶段是知识注入阶段,利用多模态大型语言模型生成情感描述,并通过双路径对比学习将这些描述与视听表征对齐,从而注入情感知识。
关键创新:该论文的关键创新在于:1) 提出了一种统一的跨模态编码器,能够有效地学习视听数据的联合表征;2) 利用多模态大型语言模型生成的情感描述作为外部知识,指导视听表征学习,从而提升了情感识别的准确性;3) 提出了一个高效的两阶段框架,能够在有限的计算资源下实现最先进的性能。
关键设计:在第一阶段,使用了Transformer结构作为统一的编码器,并采用了掩码自编码器(MAE)和对比学习(Contrastive Learning)作为预训练目标。在第二阶段,使用了Chain-of-Thought prompting来引导大型语言模型生成更准确的情感描述。双路径对比学习损失函数用于对齐视听表征和情感描述的嵌入。
🖼️ 关键图片

📊 实验亮点
VAEmo在多个AVER基准测试中取得了最先进的性能。例如,在CMU-MOSEI数据集上,VAEmo的准确率显著优于现有方法,并且模型参数量更小,表明了该方法在效率和准确性方面的优势。实验结果验证了统一跨模态编码和情感感知语义指导对于学习高效、可泛化的VA情感表征的重要性。
🎯 应用场景
该研究成果可应用于情感计算、人机交互、智能客服、心理健康监测等领域。通过准确识别用户的情感状态,可以提升用户体验,改善沟通效果,并为个性化服务提供支持。未来,该技术有望在虚拟现实、游戏、教育等领域发挥更大的作用。
📄 摘要(原文)
Audiovisual emotion recognition (AVER) aims to infer human emotions from nonverbal visual-audio (VA) cues, offering modality-complementary and language-agnostic advantages. However, AVER remains challenging due to the inherent ambiguity of emotional expressions, cross-modal expressive disparities, and the scarcity of reliably annotated data. Recent self-supervised AVER approaches have introduced strong multimodal representations, yet they predominantly rely on modality-specific encoders and coarse content-level alignment, limiting fine-grained emotional semantic modeling. To address these issues, we propose VAEmo, an efficient two-stage framework for emotion-centric joint VA representation learning with external knowledge injection. In Stage~1, a unified and lightweight representation network is pre-trained on large-scale speaker-centric VA corpora via masked reconstruction and contrastive objectives, mitigating the modality gap and learning expressive, complementary representations without emotion labels. In Stage~2, multimodal large language models automatically generate detailed affective descriptions according to our well-designed chain-of-thought prompting for only a small subset of VA samples; these rich textual semantics are then injected by aligning their corresponding embeddings with VA representations through dual-path contrastive learning, further bridging the emotion gap. Extensive experiments on multiple downstream AVER benchmarks show that VAEmo achieves state-of-the-art performance with a compact design, highlighting the benefit of unified cross-modal encoding and emotion-aware semantic guidance for efficient, generalizable VA emotion representations.