RTV-Bench: Benchmarking MLLM Continuous Perception, Understanding and Reasoning through Real-Time Video
作者: Shuhang Xun, Sicheng Tao, Jungang Li, Yibo Shi, Zhixin Lin, Zhanhui Zhu, Yibo Yan, Hanqian Li, Linghao Zhang, Shikang Wang, Yixin Liu, Hanbo Zhang, Ying Ma, Xuming Hu
分类: cs.CV
发布日期: 2025-05-04 (更新: 2026-01-15)
备注: Accepted by NeurIPS 2025 Datasets and Benchmarks Track;
💡 一句话要点
RTV-Bench:提出实时视频多模态大语言模型评测基准,用于连续感知、理解和推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 实时视频分析 评测基准 连续感知 视频理解
📋 核心要点
- 现有MLLM评测基准难以评估模型在连续动态视频流中的感知、理解和推理能力,无法反映真实应用场景。
- RTV-Bench通过多时间戳问答、分层问题结构和多维度评估,构建细粒度的实时视频分析评测基准。
- 实验表明,实时模型优于离线模型,但仍有提升空间;简单增加帧密度不能持续提升性能,需专门设计流视频处理模型。
📝 摘要(中文)
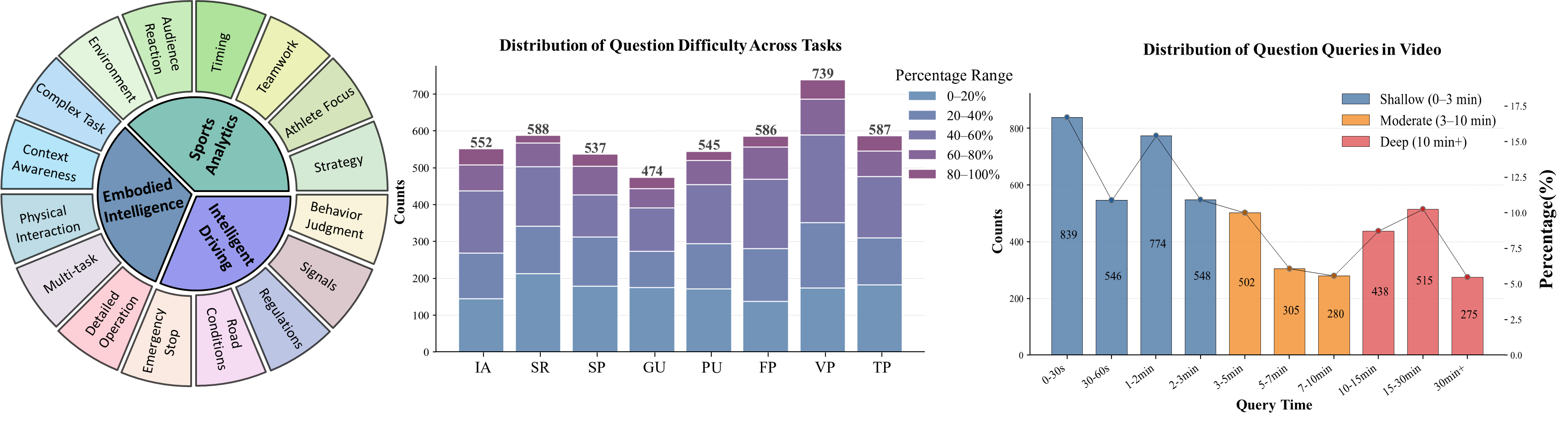
多模态大语言模型(MLLM)在感知、理解和推理方面取得了快速进展,但现有的基准测试无法充分评估这些模型在连续和动态的真实世界视频流中的能力。这种设置要求模型在视觉场景随时间演变时保持连贯的理解和推理。我们引入了RTV-Bench,这是一个用于MLLM实时视频分析的细粒度基准。它建立在三个关键原则之上:多时间戳问答、涵盖感知和推理的分层问题结构以及对连续感知、理解和推理的多维度评估。RTV-Bench包含552个不同的视频和4,608个精心策划的QA对,涵盖了广泛的动态场景。我们评估了各种最先进的MLLM,包括专有模型、开源离线模型和开源实时模型。结果表明,实时模型通常优于离线模型,但仍落后于领先的专有系统。虽然扩展模型容量通常会带来性能提升,但简单地增加采样输入帧的密度并不能始终转化为改进的结果。这些观察结果表明,当前架构在处理长时程视频流时存在固有的局限性,突显了对专门为流视频处理和分析设计的模型的需求。
🔬 方法详解
问题定义:现有MLLM评测基准无法有效评估模型在连续、动态的真实世界视频流中的感知、理解和推理能力。现有方法难以处理时间依赖性,无法保证模型在长时间序列上的连贯性和一致性。现有基准缺乏对实时性能的考量,无法反映实际应用场景的需求。
核心思路:RTV-Bench的核心思路是构建一个细粒度的、面向实时视频分析的评测基准,通过精心设计的视频数据集和问答对,全面评估MLLM在连续感知、理解和推理方面的能力。该基准强调多时间戳问答,要求模型能够理解视频中事件随时间的变化,并进行相应的推理。
技术框架:RTV-Bench包含以下几个主要组成部分:1)视频数据集:包含552个不同的视频,涵盖了广泛的动态场景。2)问答对:包含4,608个精心策划的QA对,涵盖感知和推理两个层次。问题结构是分层的,从简单的感知问题到复杂的推理问题。3)评估指标:从多个维度评估模型的性能,包括连续感知、理解和推理能力。
关键创新:RTV-Bench的关键创新在于其对实时视频分析的关注,以及对连续感知、理解和推理能力的全面评估。与现有基准相比,RTV-Bench更贴近真实应用场景,能够更有效地评估MLLM的性能。另一个创新点是多时间戳问答的设计,这要求模型能够理解视频中事件随时间的变化,并进行相应的推理。
关键设计:RTV-Bench的关键设计包括:1)视频数据集的多样性,确保基准能够覆盖各种不同的动态场景。2)问答对的精心设计,确保问题能够有效地评估模型的感知、理解和推理能力。3)评估指标的多维度性,确保能够全面评估模型的性能。具体参数设置和网络结构取决于被评估的MLLM模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,实时模型通常优于离线模型,但仍落后于领先的专有系统。虽然扩展模型容量通常会带来性能提升,但简单地增加采样输入帧的密度并不能始终转化为改进的结果。这表明当前架构在处理长时程视频流时存在固有的局限性,需要专门为流视频处理和分析设计的模型。
🎯 应用场景
RTV-Bench可用于评估和改进MLLM在视频监控、自动驾驶、机器人导航、智能助手等领域的应用。通过该基准,研究人员可以更好地了解MLLM在处理实时视频流方面的优势和局限性,从而开发出更高效、更可靠的视频分析系统。该基准的推出将推动多模态大语言模型在视频理解领域的进一步发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have made rapid progress in perception, understanding, and reasoning, yet existing benchmarks fall short in evaluating these abilities under continuous and dynamic real-world video streams. Such settings require models to maintain coherent understanding and reasoning as visual scenes evolve over time. We introduce RTV-Bench, a fine-grained benchmark for real-time video analysis with MLLMs. It is built upon three key principles: multi-timestamp question answering, hierarchical question structures spanning perception and reasoning, and multi-dimensional evaluation of continuous perception, understanding, and reasoning. RTV-Bench comprises 552 diverse videos and 4,608 carefully curated QA pairs covering a wide range of dynamic scenarios. We evaluate a broad range of state-of-the-art MLLMs, including proprietary, open-source offline, and open-source real-time models. Our results show that real-time models generally outperform offline counterparts but still lag behind leading proprietary systems. While scaling model capacity generally yields performance gains, simply increasing the density of sampled input frames does not consistently translate into improved results. These observations suggest inherent limitations in current architectures when handling long-horizon video streams, underscoring the need for models explicitly designed for streaming video processing and analysis.