VIDSTAMP: A Temporally-Aware Watermark for Ownership and Integrity in Video Diffusion Models
作者: Mohammadreza Teymoorianfard, Siddarth Sitaraman, Shiqing Ma, Amir Houmansadr
分类: cs.CV, cs.CR, cs.LG
发布日期: 2025-05-02 (更新: 2025-11-19)
🔗 代码/项目: GITHUB
💡 一句话要点
VidStamp:一种时序感知的视频扩散模型水印方案,用于所有权和完整性验证
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视频水印 扩散模型 所有权验证 完整性验证 时间一致性 深度学习 对抗训练
📋 核心要点
- 现有视频水印方法在容量、不可感知性和鲁棒性之间难以平衡,限制了其在视频扩散模型中的应用。
- VidStamp通过在视频扩散模型的解码器中嵌入帧级别消息,并采用两阶段微调策略,实现了高容量、低感知影响的水印。
- 实验表明,VidStamp在多个视频扩散模型上表现出色,实现了高容量水印,并对篡改具有很强的鲁棒性和精确定位能力。
📝 摘要(中文)
视频扩散模型能够生成逼真且时序一致的视频,但也引发了关于来源、所有权和完整性的担忧。水印技术通过将元数据直接嵌入内容中来解决这些问题。一个好的水印方案需要足够的容量来存储有意义的元数据,同时保持不可感知性并对常见的视频篡改具有鲁棒性。现有方法通常面临容量有限、额外的推理成本或视觉质量下降等问题。本文提出了一种名为VidStamp的水印框架,该框架通过潜在视频扩散模型的解码器嵌入帧级别的消息。解码器经过两个阶段的微调:第一阶段使用静态图像数据集来促进空间消息分离;第二阶段使用合成视频序列来恢复时间一致性。这种方法实现了高容量水印,同时对感知的影响最小。VidStamp还支持通过控制信号在推理过程中选择消息模板的动态水印,从而增加了灵活性并创建了第二个通信通道。在Stable Video Diffusion (I2V)、OpenSora和Wan (T2V)上的评估表明,该系统能够在保持视觉质量并对常见失真保持鲁棒性的同时,每帧嵌入48位信息。与VideoSeal、VideoShield和RivaGAN相比,VidStamp实现了更低的log P值和更强的可检测性。其逐帧水印设计还实现了精确的时间篡改定位,准确率达到0.96,超过了VideoShield基线。
🔬 方法详解
问题定义:视频扩散模型生成的视频面临所有权和完整性验证的难题。现有水印方法在容量、不可感知性和鲁棒性方面存在局限性,无法满足视频扩散模型的需求,例如容量不足以嵌入有意义的元数据,或引入明显的视觉伪影,或容易被攻击去除。
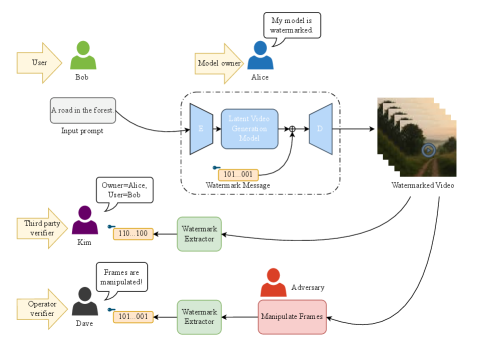
核心思路:VidStamp的核心思路是在视频扩散模型的解码器中嵌入水印信息,利用解码器将潜在表示转换为视觉内容的过程,巧妙地将水印信息融合到视频帧中。通过两阶段微调,首先保证空间消息分离,然后恢复时间一致性,从而实现高容量、低感知影响和高鲁棒性的水印。
技术框架:VidStamp框架主要包含以下几个部分:1) 潜在视频扩散模型:作为水印嵌入和提取的基础模型。2) 水印编码器:将元数据编码为帧级别消息。3) 解码器微调:分为两个阶段,第一阶段使用静态图像数据集进行空间消息分离,第二阶段使用合成视频序列恢复时间一致性。4) 水印解码器:从视频帧中提取水印信息。5) 动态水印控制信号:用于在推理过程中选择消息模板,实现动态水印。
关键创新:VidStamp的关键创新在于:1) 利用视频扩散模型的解码器进行水印嵌入,避免了额外的推理成本。2) 提出了两阶段微调策略,有效平衡了空间消息分离和时间一致性。3) 引入动态水印控制信号,增加了水印的灵活性和通信能力。4) 逐帧水印设计实现了精确的时间篡改定位。
关键设计:1) 两阶段微调:第一阶段使用静态图像数据集,例如ImageNet,通过对抗训练鼓励空间消息分离。第二阶段使用合成视频序列,通过最小化相邻帧之间的水印差异来恢复时间一致性。2) 损失函数:包括感知损失、水印损失和对抗损失,用于平衡视觉质量、水印容量和鲁棒性。3) 动态水印:通过控制信号选择不同的消息模板,实现动态水印,增加了水印的复杂性和安全性。
🖼️ 关键图片

📊 实验亮点
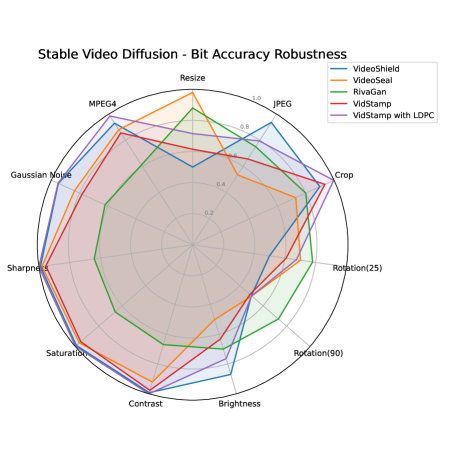
VidStamp在Stable Video Diffusion (I2V)、OpenSora和Wan (T2V)等多个视频扩散模型上进行了评估,结果表明,该系统能够在保持视觉质量的同时,每帧嵌入48位信息。与VideoSeal、VideoShield和RivaGAN相比,VidStamp实现了更低的log P值和更强的可检测性。其逐帧水印设计还实现了精确的时间篡改定位,准确率达到0.96,超过了VideoShield基线。
🎯 应用场景
VidStamp可应用于视频内容版权保护、来源追溯、完整性验证等领域。例如,可以用于防止AI生成视频的滥用,对新闻视频进行真伪鉴别,以及保护电影、电视剧等数字内容的版权。该技术还有助于构建更安全、可信的视频内容生态系统。
📄 摘要(原文)
Video diffusion models can generate realistic and temporally consistent videos. This raises concerns about provenance, ownership, and integrity. Watermarking can help address these issues by embedding metadata directly into the content. To work well, a watermark needs enough capacity for meaningful metadata. It must also stay imperceptible and remain robust to common video manipulations. Existing methods struggle with limited capacity, extra inference cost, or reduced visual quality. We introduce VidStamp, a watermarking framework that embeds frame-level messages through the decoder of a latent video diffusion model. The decoder is fine-tuned in two stages. The first stage uses static image datasets to encourage spatial message separation. The second stage uses synthesized video sequences to restore temporal consistency. This approach enables high-capacity watermarks with minimal perceptual impact. VidStamp also supports dynamic watermarking through a control signal that selects message templates during inference. This adds flexibility and creates a second channel for communication. We evaluate VidStamp on Stable Video Diffusion (I2V), OpenSora, and Wan (T2V). The system embeds 48 bits per frame while preserving visual quality and staying robust to common distortions. Compared with VideoSeal, VideoShield, and RivaGAN, it achieves lower log P-values and stronger detectability. Its frame-wise watermarking design also enables precise temporal tamper localization, with an accuracy of 0.96, which exceeds the VideoShield baseline. Code: https://github.com/SPIN-UMass/VidStamp