Multi-Modal Language Models as Text-to-Image Model Evaluators
作者: Jiahui Chen, Candace Ross, Reyhane Askari-Hemmat, Koustuv Sinha, Melissa Hall, Michal Drozdzal, Adriana Romero-Soriano
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-05-01 (更新: 2025-05-12)
💡 一句话要点
提出MT2IE框架,利用多模态大语言模型评估文本生成图像模型,提高评估效率和一致性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本生成图像 多模态大语言模型 模型评估 提示工程 图像美学
📋 核心要点
- 文本生成图像模型快速发展,依赖静态数据集的自动评估基准逐渐过时,亟需新的评估方法。
- 利用多模态大语言模型作为评估代理,迭代生成提示并评估图像,从而评估提示-生成一致性和图像美学。
- MT2IE框架在保证评估效果的同时,大幅减少了评估所需的提示数量,并提高了与人类判断的相关性。
📝 摘要(中文)
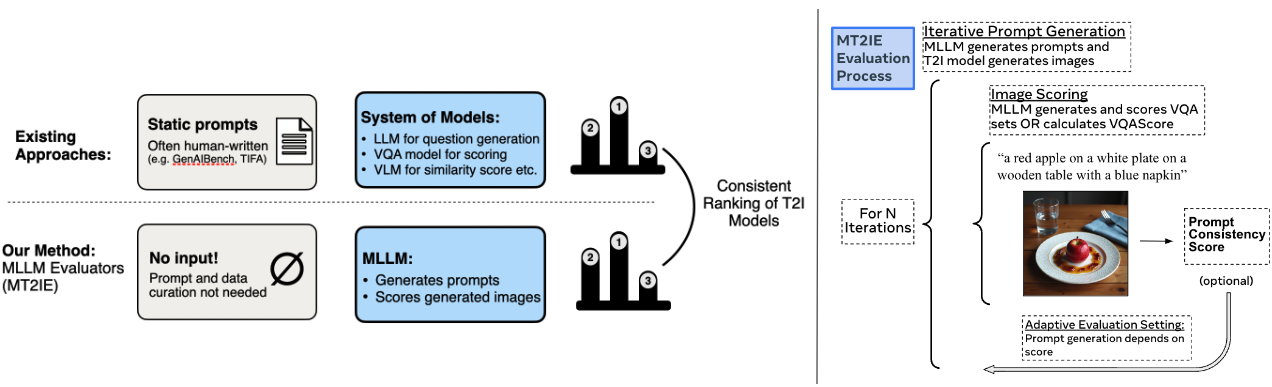
本文提出了一种新的文本生成图像(T2I)模型评估框架,名为多模态文本生成图像评估(MT2IE)。该框架利用多模态大型语言模型(MLLM)作为评估代理,与T2I模型交互,旨在评估提示-生成一致性和图像美学。MT2IE迭代地生成评估提示,对生成的图像进行评分,并以远低于现有静态基准的提示数量,匹配现有基准的T2I评估结果。此外,MT2IE的提示-生成一致性得分与人类判断的相关性高于先前文献中提出的得分。MT2IE生成的提示能够有效地探测T2I模型的性能,在仅使用现有基准1/80的提示数量的情况下,产生与现有基准相同的T2I模型相对排名。
🔬 方法详解
问题定义:现有文本生成图像(T2I)模型的评估依赖于静态数据集,这些数据集很快就会过时。此外,评估T2I模型需要大量的提示词,计算成本高昂。现有的自动评估指标与人类判断的一致性也存在问题。
核心思路:利用多模态大型语言模型(MLLM)的强大能力,使其能够理解文本提示和图像内容,并判断生成图像与提示的一致性和美学质量。通过迭代生成提示,可以更有效地探索T2I模型的性能,并减少所需的提示数量。
技术框架:MT2IE框架包含以下几个主要模块:1) 提示生成模块:使用MLLM生成用于评估T2I模型的提示。2) 图像生成模块:使用T2I模型根据生成的提示生成图像。3) 图像评估模块:使用MLLM评估生成的图像与提示的一致性和美学质量。4) 性能评估模块:根据图像评估模块的输出,计算T2I模型的性能指标。
关键创新:MT2IE的关键创新在于使用MLLM作为评估代理,并采用迭代生成提示的方法。这种方法能够更有效地探索T2I模型的性能,并减少所需的提示数量。此外,MT2IE的提示-生成一致性得分与人类判断的相关性更高。
关键设计:在提示生成模块中,可以使用不同的策略来生成提示,例如随机生成、基于知识库生成等。在图像评估模块中,可以使用不同的MLLM和评估指标,例如CLIP、BLIP等。性能评估模块可以计算各种性能指标,例如FID、Inception Score等。具体参数设置需要根据实际情况进行调整。
🖼️ 关键图片


📊 实验亮点
MT2IE框架在评估T2I模型时,仅使用现有静态基准1/80的提示数量,即可达到与现有基准相同的T2I模型相对排名。此外,MT2IE的提示-生成一致性得分与人类判断的相关性高于先前文献中提出的得分,表明MT2IE能够更准确地反映人类对T2I模型生成图像质量的感知。
🎯 应用场景
该研究成果可应用于文本生成图像模型的自动评估,帮助研究人员更高效、更准确地评估模型性能。此外,该方法还可以用于指导T2I模型的训练和优化,提高生成图像的质量和一致性。未来,该方法可以扩展到其他生成模型的评估,例如文本生成、视频生成等。
📄 摘要(原文)
The steady improvements of text-to-image (T2I) generative models lead to slow deprecation of automatic evaluation benchmarks that rely on static datasets, motivating researchers to seek alternative ways to evaluate the T2I progress. In this paper, we explore the potential of multi-modal large language models (MLLMs) as evaluator agents that interact with a T2I model, with the objective of assessing prompt-generation consistency and image aesthetics. We present Multimodal Text-to-Image Eval (MT2IE), an evaluation framework that iteratively generates prompts for evaluation, scores generated images and matches T2I evaluation of existing benchmarks with a fraction of the prompts used in existing static benchmarks. Moreover, we show that MT2IE's prompt-generation consistency scores have higher correlation with human judgment than scores previously introduced in the literature. MT2IE generates prompts that are efficient at probing T2I model performance, producing the same relative T2I model rankings as existing benchmarks while using only 1/80th the number of prompts for evaluation.