T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
作者: Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, Hongsheng Li
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-05-01 (更新: 2025-07-01)
备注: Project Page: https://github.com/CaraJ7/T2I-R1
🔗 代码/项目: GITHUB
💡 一句话要点
T2I-R1:利用双层CoT和强化学习提升文本到图像生成质量
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 思维链 强化学习 语义推理 Token推理 图像生成 深度学习 人工智能
📋 核心要点
- 现有文本到图像生成模型缺乏有效的推理机制,难以进行高级语义规划和低级像素控制。
- T2I-R1模型通过引入语义层和Token层双层CoT,分别指导提示词规划和像素生成,提升生成质量。
- 实验结果表明,T2I-R1在多个基准测试中显著优于现有模型,验证了双层CoT推理的有效性。
📝 摘要(中文)
本文提出了一种名为T2I-R1的、基于强化学习并采用双层思维链(CoT)推理的文本到图像生成模型。该模型旨在通过CoT推理来增强图像生成过程。具体而言,论文提出了两种CoT:(1) 语义层CoT,用于提示词的高级规划;(2) Token层CoT,用于逐块生成过程中低级像素的处理。为了更好地协调这两个层级的CoT,论文引入了BiCoT-GRPO,它通过生成奖励的集成,在同一训练步骤中无缝地优化两个生成CoT。通过将该推理策略应用于基线模型Janus-Pro,在T2I-CompBench上实现了13%的改进,在WISE基准上实现了19%的改进,甚至超过了最先进的模型FLUX.1。
🔬 方法详解
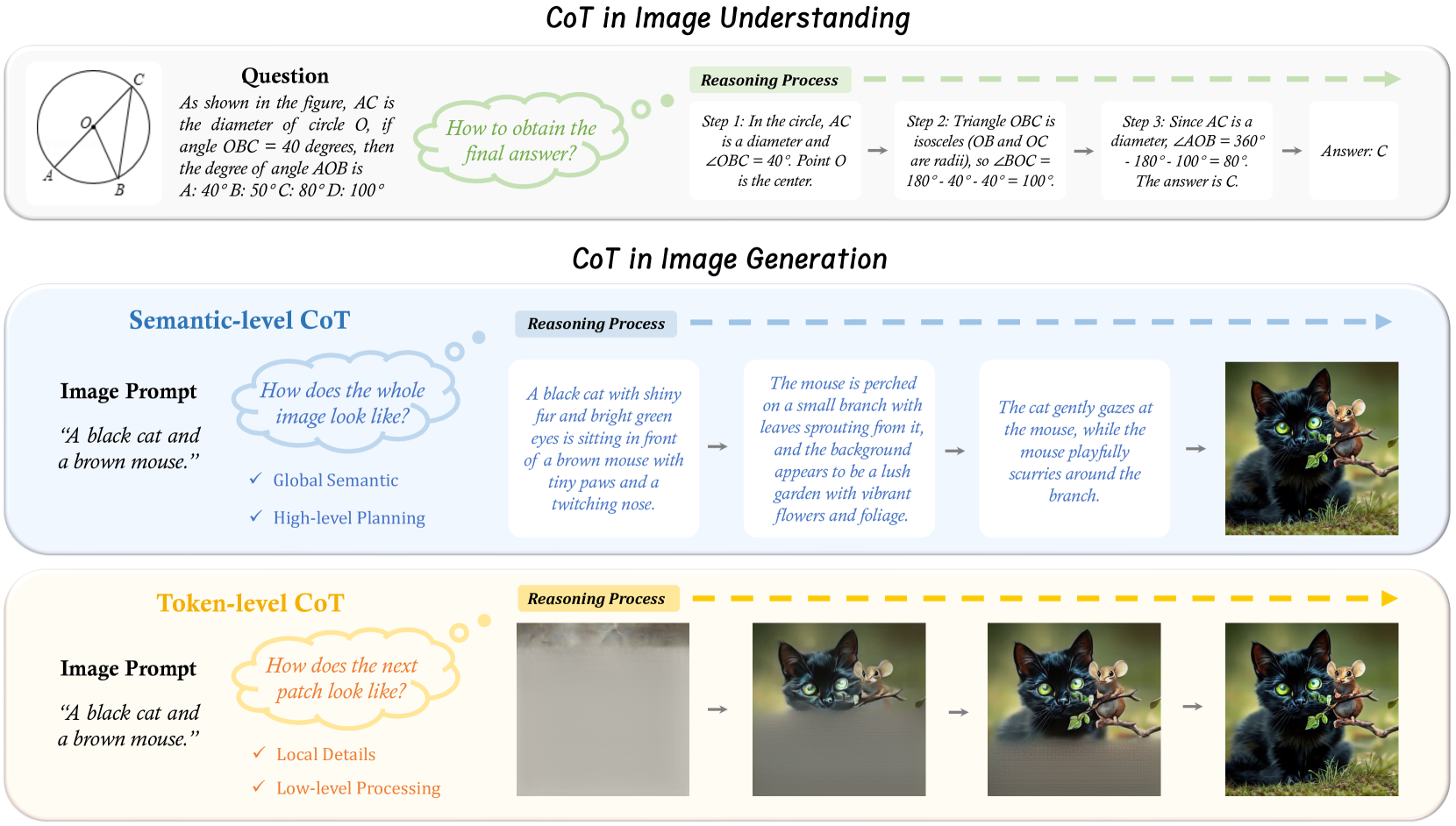
问题定义:现有的文本到图像生成方法在利用大型语言模型的推理能力方面存在不足。它们通常缺乏明确的推理过程,难以对prompt进行有效的语义规划,也难以在像素级别进行精细的控制,导致生成图像的质量和与文本描述的对齐度受到限制。
核心思路:T2I-R1的核心思路是引入思维链(CoT)推理,将复杂的图像生成过程分解为一系列可解释的步骤。通过在语义层面和Token层面分别进行CoT推理,模型可以更好地理解文本描述,并生成更符合描述的图像。语义层CoT负责对prompt进行高级规划,Token层CoT负责在像素级别进行精细控制。
技术框架:T2I-R1的整体框架包括一个文本编码器、一个图像生成器和一个强化学习模块。文本编码器将文本描述转换为语义向量,图像生成器根据语义向量生成图像。强化学习模块用于优化图像生成器的参数,使其能够更好地利用CoT推理。BiCoT-GRPO算法用于协调语义层和Token层CoT,并通过集成生成奖励来优化模型。
关键创新:T2I-R1的关键创新在于提出了双层CoT推理机制,并设计了BiCoT-GRPO算法来协调这两个层级的CoT。与现有方法相比,T2I-R1能够更有效地利用大型语言模型的推理能力,从而生成更高质量的图像。现有方法通常只关注图像生成器的结构和训练方法,而忽略了推理过程的重要性。
关键设计:BiCoT-GRPO算法的关键设计在于生成奖励的集成。该算法通过结合多个生成奖励,例如图像质量奖励和文本对齐度奖励,来优化模型。此外,该算法还引入了一个平衡系数,用于控制语义层CoT和Token层CoT的相对重要性。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
T2I-R1在T2I-CompBench上实现了13%的改进,在WISE基准上实现了19%的改进,甚至超过了最先进的模型FLUX.1。这些结果表明,T2I-R1能够显著提升文本到图像生成模型的性能,验证了双层CoT推理的有效性。
🎯 应用场景
T2I-R1具有广泛的应用前景,包括艺术创作、游戏开发、广告设计、虚拟现实等领域。它可以用于生成各种风格和内容的图像,从而满足不同用户的需求。未来,该技术有望应用于更复杂的场景,例如视频生成、3D模型生成等。
📄 摘要(原文)
Recent advancements in large language models have demonstrated how chain-of-thought (CoT) and reinforcement learning (RL) can improve performance. However, applying such reasoning strategies to the visual generation domain remains largely unexplored. In this paper, we present T2I-R1, a novel reasoning-enhanced text-to-image generation model, powered by RL with a bi-level CoT reasoning process. Specifically, we identify two levels of CoT that can be utilized to enhance different stages of generation: (1) the semantic-level CoT for high-level planning of the prompt and (2) the token-level CoT for low-level pixel processing during patch-by-patch generation. To better coordinate these two levels of CoT, we introduce BiCoT-GRPO with an ensemble of generation rewards, which seamlessly optimizes both generation CoTs within the same training step. By applying our reasoning strategies to the baseline model, Janus-Pro, we achieve superior performance with 13% improvement on T2I-CompBench and 19% improvement on the WISE benchmark, even surpassing the state-of-the-art model FLUX.1. Code is available at: https://github.com/CaraJ7/T2I-R1