Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
作者: Jiaxu Qian, Chendong Wang, Yifan Yang, Chaoyun Zhang, Huiqiang Jiang, Xufang Luo, Yu Kang, Qingwei Lin, Anlan Zhang, Shiqi Jiang, Ting Cao, Tianjun Mao, Suman Banerjee, Guyue Liu, Saravan Rajmohan, Dongmei Zhang, Yuqing Yang, Qi Zhang, Lili Qiu
分类: cs.CV, cs.AI, eess.IV
发布日期: 2025-04-30 (更新: 2025-12-31)
备注: TMLR accepted
💡 一句话要点
Zoomer:针对黑盒MLLM的自适应图像焦点优化框架,提升小物体识别能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉提示 自适应图像处理 黑盒优化 小物体识别
📋 核心要点
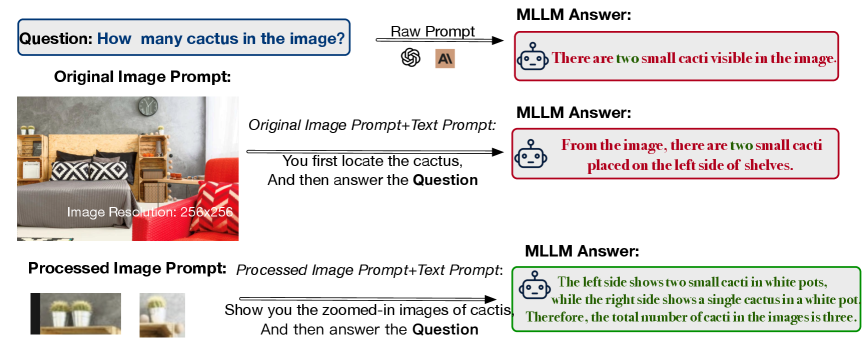
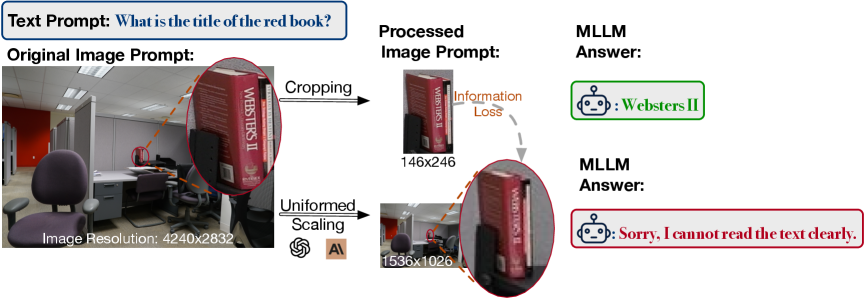
- 现有MLLM在处理小物体或精细空间信息时易产生幻觉,原因是缺乏区域自适应注意力和token预算限制。
- Zoomer通过提示感知的强调模块、空间保留的编排模式和预算感知的策略,实现token高效的图像表示。
- 实验表明,Zoomer在多个基准测试中显著提升了MLLM的准确率,并降低了图像token的使用量。
📝 摘要(中文)
多模态大型语言模型(MLLM),如GPT-4o、Gemini Pro和Claude 3.5,实现了对文本和视觉输入的统一推理。然而,在现实场景中,尤其是在涉及小物体或精细空间上下文时,它们经常出现幻觉。我们指出了这种失败的两个核心原因:缺乏区域自适应注意力和不灵活的token预算,这迫使模型进行均匀下采样,导致关键信息丢失。为了克服这些限制,我们引入了Zoomer,一个视觉提示框架,为黑盒MLLM提供token高效、细节保留的图像表示。Zoomer集成了(1)一个提示感知的强调模块,以突出语义相关的区域,(2)一个空间保留的编排模式,以维持对象关系,以及(3)一个预算感知的策略,以自适应地在全局上下文和局部细节之间分配token。在九个基准测试和三个商业MLLM上的大量实验表明,Zoomer将准确率提高了高达27%,同时将图像token使用量减少了高达67%。我们的方法为在模型内部不可访问的环境中实现鲁棒、资源感知的多模态理解建立了一个原则性的方法。
🔬 方法详解
问题定义:MLLM在处理包含小物体或精细空间信息的图像时,容易出现“幻觉”问题,即错误地识别或理解图像内容。现有的方法通常采用均匀下采样,导致关键细节信息丢失,且缺乏对图像不同区域重要性的区分,无法有效利用有限的token预算。
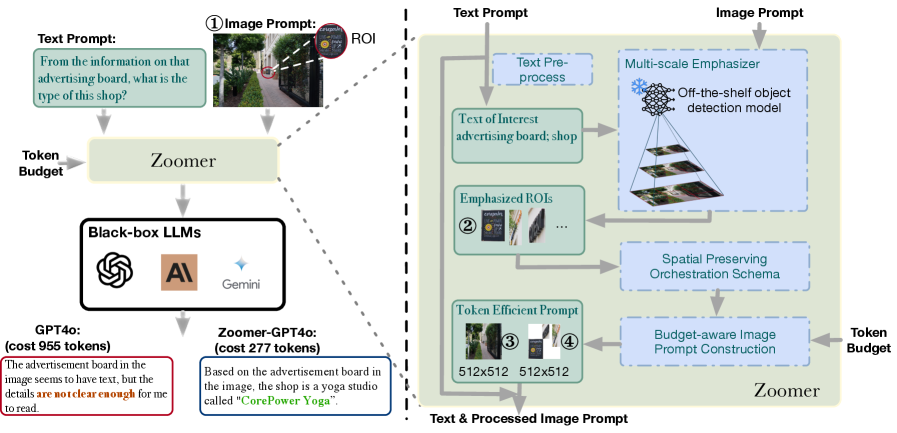
核心思路:Zoomer的核心思路是根据给定的提示(prompt),自适应地调整图像不同区域的关注度,并智能地分配token预算,从而在有限的token数量下,尽可能保留重要的细节信息,提升MLLM对图像的理解能力。通过突出语义相关的区域,并保持对象之间的空间关系,Zoomer能够为MLLM提供更具信息量的视觉输入。
技术框架:Zoomer框架主要包含三个模块:1) 提示感知的强调模块(Prompt-aware Emphasis Module):根据给定的文本提示,确定图像中与提示相关的区域,并赋予更高的权重。2) 空间保留的编排模式(Spatial-preserving Orchestration Schema):在突出重要区域的同时,保持图像中对象之间的空间关系,避免信息丢失。3) 预算感知的策略(Budget-aware Strategy):根据预设的token预算,自适应地分配token给全局上下文和局部细节,确保重要区域能够获得足够的token。
关键创新:Zoomer的关键创新在于其自适应性,能够根据不同的提示和token预算,动态地调整图像的关注区域和细节保留程度。与传统的均匀下采样方法相比,Zoomer能够更有效地利用有限的token资源,提升MLLM的性能。此外,Zoomer作为一个视觉提示框架,可以应用于各种黑盒MLLM,无需访问模型内部参数。
关键设计:提示感知的强调模块可能采用注意力机制或显著性检测算法,根据提示文本生成注意力图,并将其应用于图像特征。空间保留的编排模式可能采用图像分割或关键点检测等技术,以保持对象之间的空间关系。预算感知的策略可能采用强化学习或优化算法,以找到最佳的token分配方案。具体的参数设置、损失函数和网络结构等细节,论文中可能有所描述,但此处无法得知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Zoomer在九个基准测试和三个商业MLLM(如GPT-4o, Gemini Pro, Claude 3.5)上取得了显著的性能提升。具体而言,Zoomer将准确率提高了高达27%,同时将图像token使用量减少了高达67%。这些结果表明,Zoomer能够有效地提升MLLM的性能,并降低计算成本。
🎯 应用场景
Zoomer可应用于各种需要多模态理解的场景,例如智能客服、自动驾驶、医疗诊断等。通过提升MLLM对图像细节的理解能力,Zoomer可以提高这些应用的准确性和可靠性。未来,Zoomer可以进一步扩展到视频等多模态数据,并与其他视觉提示技术相结合,实现更强大的多模态理解能力。
📄 摘要(原文)
Multimodal large language models (MLLMs) such as GPT-4o, Gemini Pro, and Claude 3.5 have enabled unified reasoning over text and visual inputs, yet they often hallucinate in real world scenarios especially when small objects or fine spatial context are involved. We pinpoint two core causes of this failure: the absence of region-adaptive attention and inflexible token budgets that force uniform downsampling, leading to critical information loss. To overcome these limitations, we introduce Zoomer, a visual prompting framework that delivers token-efficient, detail-preserving image representations for black-box MLLMs. Zoomer integrates (1) a prompt-aware emphasis module to highlight semantically relevant regions, (2) a spatial-preserving orchestration schema to maintain object relationships, and (3) a budget-aware strategy to adaptively allocate tokens between global context and local details. Extensive experiments on nine benchmarks and three commercial MLLMs demonstrate that Zoomer boosts accuracy by up to 27% while cutting image token usage by up to 67%. Our approach establishes a principled methodology for robust, resource-aware multimodal understanding in settings where model internals are inaccessible.