Direct Motion Models for Assessing Generated Videos
作者: Kelsey Allen, Carl Doersch, Guangyao Zhou, Mohammed Suhail, Danny Driess, Ignacio Rocco, Yulia Rubanova, Thomas Kipf, Mehdi S. M. Sajjadi, Kevin Murphy, Joao Carreira, Sjoerd van Steenkiste
分类: cs.CV, cs.LG
发布日期: 2025-04-30
备注: Project page: http://trajan-paper.github.io
💡 一句话要点
提出基于轨迹自编码器的视频生成质量评估方法,提升运动一致性与真实性评估。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 视频质量评估 运动估计 点轨迹 自编码器
📋 核心要点
- 现有视频生成模型在运动效果上存在不足,而FVD等评估指标难以有效衡量运动质量。
- 论文提出基于点轨迹自编码的运动特征提取方法,用于评估视频的运动一致性和真实性。
- 实验表明,该方法在检测时间扭曲和预测人类评价方面优于现有方法,并能定位时空不一致性。
📝 摘要(中文)
当前视频生成模型的局限性在于生成的帧在视觉上看似合理,但运动效果不佳。传统的FVD等评估方法难以有效捕捉这一问题。本文提出了一种超越FVD的指标,能够更好地衡量物体交互和运动的合理性。该方法基于点轨迹的自编码,生成运动特征,用于比较视频分布(从单个生成视频和真实视频,到多个数据集),并评估单个视频的运动质量。实验表明,使用点轨迹而非像素重建或动作识别特征,能更敏锐地检测合成数据中的时间扭曲,并且能比其他方法更好地预测人类对生成视频的时间一致性和真实性的评价。此外,通过点轨迹表示,可以对生成视频中的时空不一致性进行定位,从而提供比以往工作更强的可解释性。
🔬 方法详解
问题定义:视频生成模型生成的视频在视觉上可能看起来逼真,但运动往往不自然或不连贯。现有的视频质量评估指标,如FVD,主要关注生成视频的视觉逼真度,而忽略了运动的合理性和时间一致性。因此,如何有效地评估生成视频的运动质量,成为了一个亟待解决的问题。
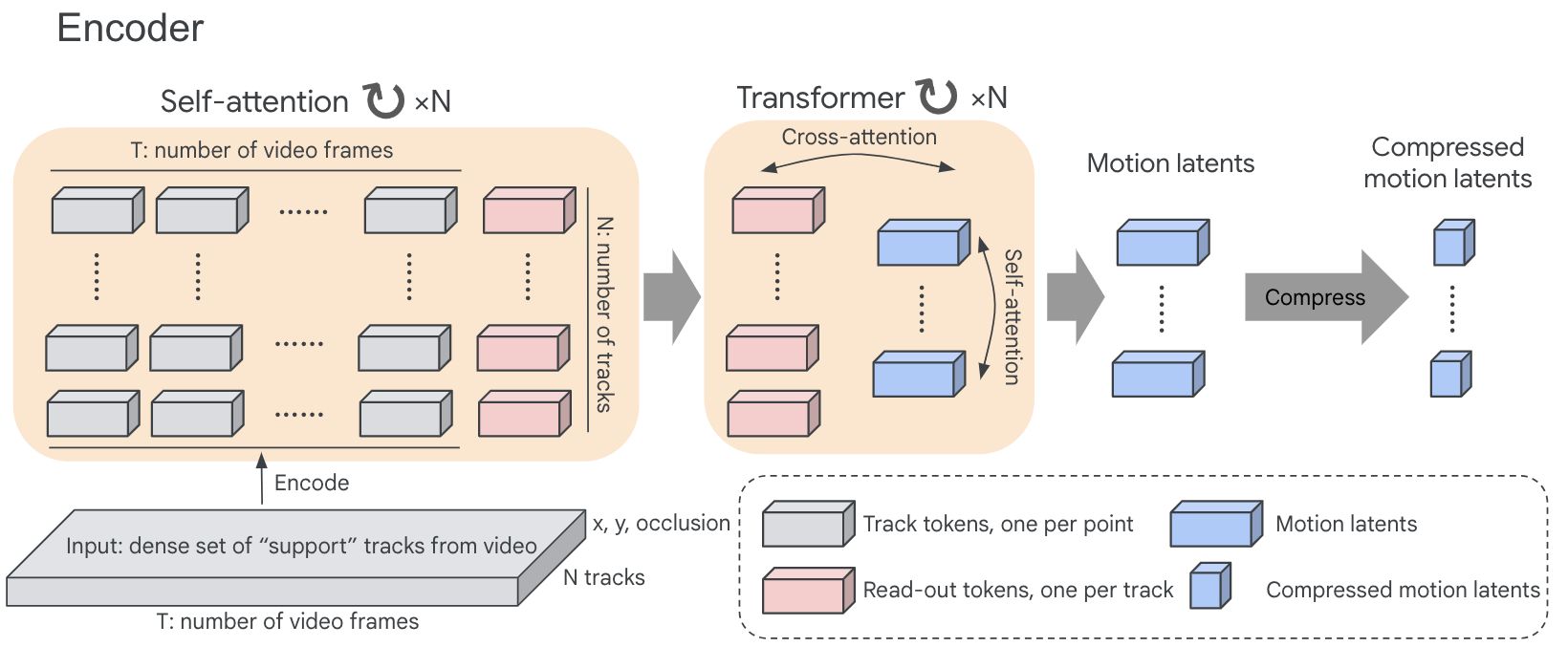
核心思路:本文的核心思路是利用视频中物体运动轨迹的信息来评估视频的运动质量。通过提取视频中关键点的运动轨迹,并使用自编码器学习这些轨迹的潜在表示,可以捕捉视频中的运动模式。然后,通过比较生成视频和真实视频的运动模式,可以评估生成视频的运动质量。这种方法的核心在于,它将运动质量的评估从像素层面转移到了运动轨迹层面,从而能够更有效地捕捉运动的不一致性和不自然性。
技术框架:该方法主要包含以下几个阶段:1) 点轨迹提取:使用现有的目标跟踪算法提取视频中关键点的运动轨迹。2) 轨迹编码:使用自编码器将运动轨迹编码成低维的运动特征向量。自编码器由编码器和解码器组成,编码器将轨迹映射到潜在空间,解码器则从潜在空间重构轨迹。3) 运动特征比较:比较生成视频和真实视频的运动特征分布。可以使用各种距离度量方法,如Wasserstein距离或KL散度。4) 时空定位:通过分析自编码器的重构误差,可以定位生成视频中存在时空不一致性的区域。
关键创新:该方法最重要的创新点在于使用点轨迹作为视频运动质量评估的表示。与传统的基于像素或动作识别特征的方法相比,点轨迹能够更直接地捕捉视频中的运动信息,并且对时间扭曲和运动不一致性更加敏感。此外,该方法还能够对生成视频中的时空不一致性进行定位,从而提供更强的可解释性。
关键设计:在点轨迹提取阶段,可以使用各种现有的目标跟踪算法,如DeepSORT或Tracktor。自编码器的网络结构可以根据具体任务进行调整,可以使用LSTM、Transformer等模型。损失函数可以选择均方误差或交叉熵损失。在运动特征比较阶段,可以使用Wasserstein距离或KL散度等距离度量方法。在时空定位阶段,可以通过分析自编码器的重构误差来确定存在时空不一致性的区域。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在评估生成视频的运动一致性和真实性方面优于现有的评估指标,如FVD。具体来说,该方法能够更敏锐地检测合成数据中的时间扭曲,并且能够更好地预测人类对生成视频的时间一致性和真实性的评价。此外,该方法还能够对生成视频中的时空不一致性进行定位,从而提供更强的可解释性。项目主页提供了代码和更多结果。
🎯 应用场景
该研究成果可广泛应用于视频生成模型的评估和改进,例如用于评估GAN、VAE等生成模型的视频生成质量。此外,该方法还可用于视频编辑、视频修复等领域,例如可以用于检测和修复视频中的运动不一致性。未来,该方法有望推动视频生成技术的发展,并为用户提供更加逼真和自然的视频体验。
📄 摘要(原文)
A current limitation of video generative video models is that they generate plausible looking frames, but poor motion -- an issue that is not well captured by FVD and other popular methods for evaluating generated videos. Here we go beyond FVD by developing a metric which better measures plausible object interactions and motion. Our novel approach is based on auto-encoding point tracks and yields motion features that can be used to not only compare distributions of videos (as few as one generated and one ground truth, or as many as two datasets), but also for evaluating motion of single videos. We show that using point tracks instead of pixel reconstruction or action recognition features results in a metric which is markedly more sensitive to temporal distortions in synthetic data, and can predict human evaluations of temporal consistency and realism in generated videos obtained from open-source models better than a wide range of alternatives. We also show that by using a point track representation, we can spatiotemporally localize generative video inconsistencies, providing extra interpretability of generated video errors relative to prior work. An overview of the results and link to the code can be found on the project page: http://trajan-paper.github.io.