Early Exit and Multi Stage Knowledge Distillation in VLMs for Video Summarization
作者: Anas Anwarul Haq Khan, Utkarsh Verma, Ganesh Ramakrishnan
分类: cs.CV, cs.AI
发布日期: 2025-04-30 (更新: 2025-09-11)
💡 一句话要点
提出DEEVISum,一种基于多阶段知识蒸馏和早退机制的轻量级视频摘要VLM模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频摘要 视觉语言模型 知识蒸馏 早退机制 多模态融合 轻量级模型 模型压缩
📋 核心要点
- 现有视频摘要模型通常计算成本高昂,难以在资源受限的环境中部署。
- DEEVISum通过多阶段知识蒸馏和早退机制,在保持性能的同时显著降低了模型的计算复杂度。
- 实验表明,DEEVISum在TVSum数据集上取得了与大型模型相当的性能,同时推理速度更快。
📝 摘要(中文)
本文提出DEEVISum(用于摘要的蒸馏早退视觉语言模型),这是一个轻量级、高效且可扩展的视觉语言模型,专为分段视频摘要而设计。DEEVISum利用结合了文本和音频信号的多模态提示,并结合了多阶段知识蒸馏(MSKD)和早退(EE)机制,以在性能和效率之间取得平衡。MSKD相比基线蒸馏(0.5%)提供了1.33%的绝对F1提升,而EE在F1值下降约1.3个点的情况下,将推理时间减少了约21%。在TVSum数据集上评估,我们最好的模型PaLI Gemma2 3B + MSKD实现了61.1的F1分数,与计算量大得多的模型相比具有竞争力,同时保持了较低的计算占用。我们公开发布了我们的代码和处理后的数据集,以支持进一步的研究。
🔬 方法详解
问题定义:论文旨在解决视频摘要任务中,现有视觉语言模型(VLM)计算成本高、效率低的问题。现有方法通常依赖于大型模型,推理速度慢,难以部署在资源受限的设备上。因此,需要一种轻量级、高效的VLM来进行视频摘要。
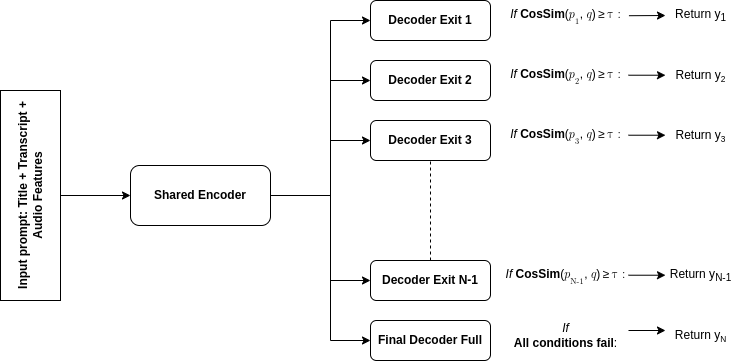
核心思路:论文的核心思路是利用知识蒸馏和早退机制来压缩大型VLM,从而获得一个小型、高效的模型。多阶段知识蒸馏(MSKD)通过逐步蒸馏,将知识从大型教师模型传递到小型学生模型,从而提高学生模型的性能。早退(EE)机制允许模型在早期层就做出预测,从而减少计算量。
技术框架:DEEVISum的技术框架主要包括以下几个模块:1) 多模态提示编码器:用于将文本和音频信号编码为多模态提示。2) 视觉语言模型:使用PaLI Gemma2 3B作为基础模型。3) 多阶段知识蒸馏:使用大型教师模型(未知)来训练小型学生模型(PaLI Gemma2 3B)。4) 早退机制:在模型的不同层添加早退分支,允许模型提前做出预测。
关键创新:论文的关键创新在于将多阶段知识蒸馏和早退机制结合起来,用于压缩VLM。MSKD可以有效地将知识从大型模型传递到小型模型,而EE可以减少推理时间。此外,论文还使用了多模态提示,将文本和音频信息融合到模型中,从而提高了摘要的质量。
关键设计:论文的关键设计包括:1) 多阶段知识蒸馏的训练策略,包括选择合适的教师模型、设计合适的损失函数等(具体细节未知)。2) 早退分支的添加位置和损失函数的设计,需要在性能和效率之间进行权衡(具体细节未知)。3) 多模态提示的编码方式,如何有效地融合文本和音频信息(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DEEVISum在TVSum数据集上取得了61.1的F1分数,与大型模型相比具有竞争力。此外,MSKD相比基线蒸馏提供了1.33%的绝对F1提升,而EE在F1值下降约1.3个点的情况下,将推理时间减少了约21%。这些结果表明,DEEVISum在性能和效率之间取得了良好的平衡。
🎯 应用场景
DEEVISum可应用于各种视频摘要场景,例如新闻视频摘要、体育赛事视频摘要、监控视频摘要等。该模型可以帮助用户快速了解视频内容,节省时间和精力。此外,DEEVISum的轻量级特性使其可以部署在移动设备和嵌入式系统中,为用户提供更加便捷的视频摘要服务。未来,该研究可以扩展到其他视觉语言任务,例如视频问答、视频描述等。
📄 摘要(原文)
We introduce DEEVISum (Distilled Early Exit Vision language model for Summarization), a lightweight, efficient, and scalable vision language model designed for segment wise video summarization. Leveraging multi modal prompts that combine textual and audio derived signals, DEEVISum incorporates Multi Stage Knowledge Distillation (MSKD) and Early Exit (EE) to strike a balance between performance and efficiency. MSKD offers a 1.33% absolute F1 improvement over baseline distillation (0.5%), while EE reduces inference time by approximately 21% with a 1.3 point drop in F1. Evaluated on the TVSum dataset, our best model PaLI Gemma2 3B + MSKD achieves an F1 score of 61.1, competing the performance of significantly larger models, all while maintaining a lower computational footprint. We publicly release our code and processed dataset to support further research.