Visual Text Processing: A Comprehensive Review and Unified Evaluation
作者: Yan Shu, Weichao Zeng, Fangmin Zhao, Zeyu Chen, Zhenhang Li, Xiaomeng Yang, Yu Zhou, Paolo Rota, Xiang Bai, Lianwen Jin, Xu-Cheng Yin, Nicu Sebe
分类: cs.CV
发布日期: 2025-04-30 (更新: 2025-06-05)
🔗 代码/项目: GITHUB
💡 一句话要点
针对视觉文本处理,提出VTPBench基准与VTPScore评估指标,促进文本特征有效利用。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文本处理 文本检测 文本识别 文本图像重建 文本图像操作 基准测试 评估指标
📋 核心要点
- 现有视觉文本处理方法难以有效捕获和利用文本的独特性质,导致模型鲁棒性不足,性能提升受限。
- 论文核心在于分析不同任务下适用的文本特征,并探讨如何将这些特征有效融入视觉文本处理框架。
- 论文构建了VTPBench基准和VTPScore评估指标,并通过实验验证了现有方法的改进空间,为未来研究奠定基础。
📝 摘要(中文)
视觉文本是文档和场景图像中的关键组成部分,蕴含丰富的语义信息,并引起计算机视觉领域的广泛关注。除了传统的文本检测和识别任务外,视觉文本处理在基础模型的推动下取得了快速进展,包括文本图像重建和文本图像操作。尽管取得了显著进展,但由于文本与一般对象的独特性质,仍然存在挑战。有效捕获和利用这些独特的文本特征对于开发鲁棒的视觉文本处理模型至关重要。本文对视觉文本处理的最新进展进行了全面、多角度的分析,重点关注两个关键问题:(1)哪些文本特征最适合不同的视觉文本处理任务?(2)如何将这些独特的文本特征有效地融入处理框架中?此外,我们还推出了VTPBench,这是一个包含广泛视觉文本处理数据集的新基准。利用多模态大型语言模型(MLLM)的先进视觉质量评估能力,我们提出了一种新的评估指标VTPScore,旨在确保公平和可靠的评估。我们对20多个特定模型的实证研究表明,当前技术仍有很大的改进空间。我们的目标是将这项工作确立为基础资源,以促进动态视觉文本处理领域的未来探索和创新。相关代码库可在https://github.com/shuyansy/Visual-Text-Processing-survey获取。
🔬 方法详解
问题定义:视觉文本处理旨在理解和操作图像中的文本信息,现有方法在处理视觉文本时,未能充分利用文本的独特性质,例如字符间的空间关系、字体风格等。这导致模型在复杂场景下表现不佳,泛化能力不足。此外,缺乏统一的评估标准也阻碍了该领域的发展。
核心思路:论文的核心思路是深入分析视觉文本的特征,并探讨如何将这些特征有效地融入到现有的视觉文本处理框架中。通过对不同任务的特性进行分析,选择合适的文本特征,并设计相应的模型结构,从而提高模型的性能和鲁棒性。同时,论文还提出了新的评估指标,以更全面地评估模型的性能。
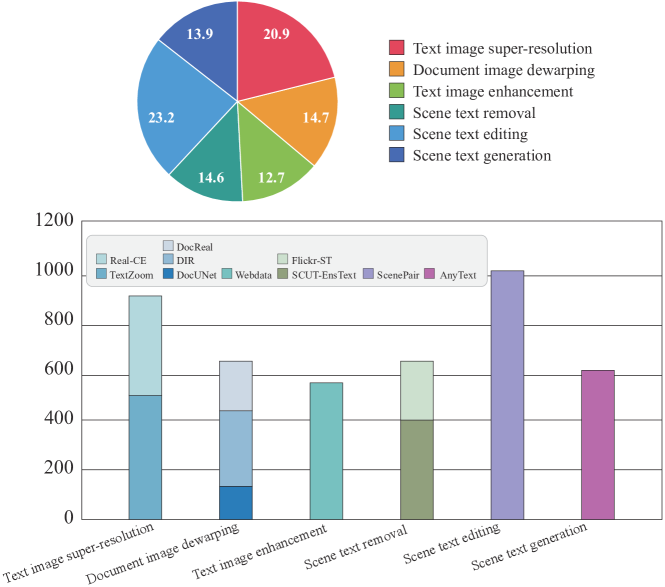
技术框架:论文首先对视觉文本处理的各个任务进行了分类,包括文本检测、文本识别、文本图像重建和文本图像操作等。然后,针对每个任务,分析了其所需的文本特征。接着,论文回顾了现有的视觉文本处理方法,并分析了它们在利用文本特征方面的优缺点。最后,论文提出了VTPBench基准和VTPScore评估指标,并对20多个模型进行了评估。
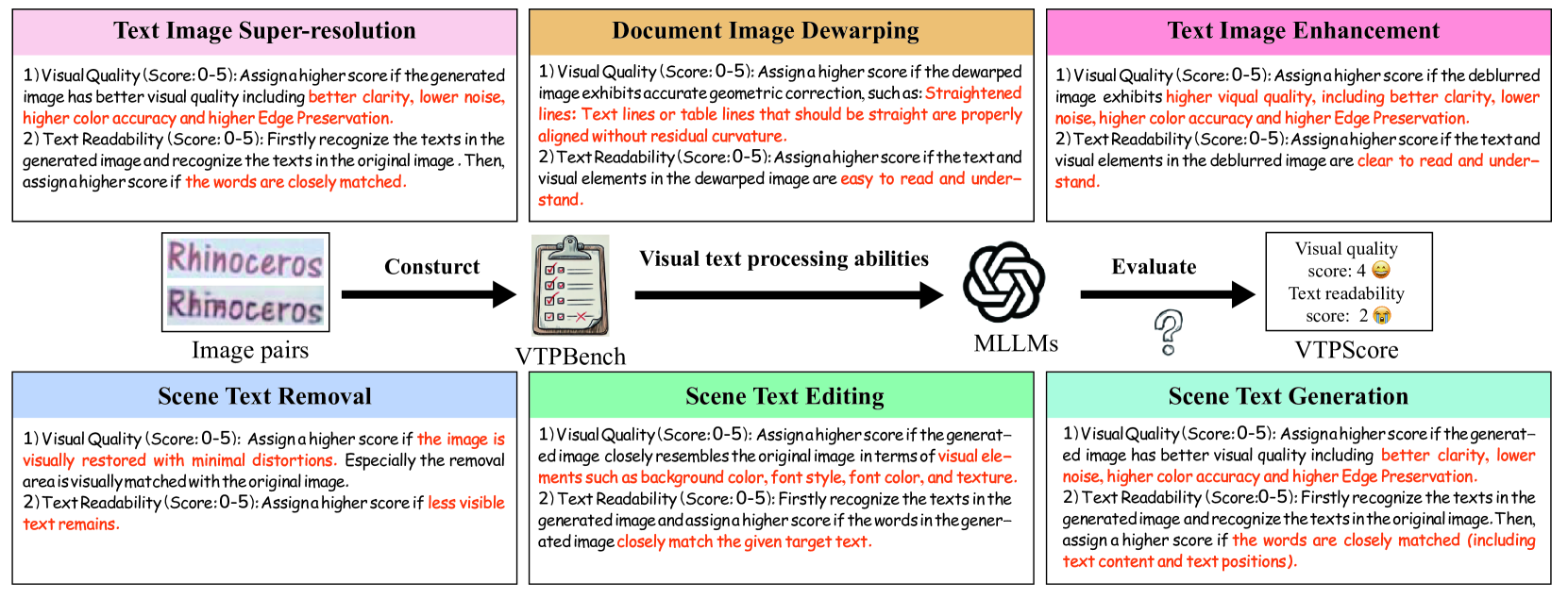
关键创新:论文的关键创新在于提出了VTPBench基准和VTPScore评估指标。VTPBench基准包含广泛的视觉文本处理数据集,可以用于评估不同模型的性能。VTPScore评估指标利用多模态大型语言模型(MLLM)的先进视觉质量评估能力,可以更全面地评估模型的性能,避免了传统评估指标的局限性。
关键设计:VTPBench基准的设计考虑了数据集的多样性和代表性,包含了不同场景、不同字体、不同语言的文本图像。VTPScore评估指标的设计利用了MLLM的视觉质量评估能力,通过比较生成图像和原始图像的视觉质量来评估模型的性能。具体来说,VTPScore会考虑图像的清晰度、真实感、文本的可读性等因素。
🖼️ 关键图片

📊 实验亮点
论文通过VTPBench基准对20多个视觉文本处理模型进行了评估,结果表明现有模型在多个任务上仍有较大的提升空间。VTPScore评估指标能够更全面地反映模型的性能,并与人工评估结果具有较高的一致性。实验结果为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可广泛应用于文档图像分析、场景文本理解、图像编辑等领域。例如,可以用于提高OCR的准确率,改善图像翻译的效果,以及实现更逼真的文本图像编辑。此外,该研究还可以促进视觉文本处理领域的发展,为未来的研究提供基础资源和评估标准。
📄 摘要(原文)
Visual text is a crucial component in both document and scene images, conveying rich semantic information and attracting significant attention in the computer vision community. Beyond traditional tasks such as text detection and recognition, visual text processing has witnessed rapid advancements driven by the emergence of foundation models, including text image reconstruction and text image manipulation. Despite significant progress, challenges remain due to the unique properties that differentiate text from general objects. Effectively capturing and leveraging these distinct textual characteristics is essential for developing robust visual text processing models. In this survey, we present a comprehensive, multi-perspective analysis of recent advancements in visual text processing, focusing on two key questions: (1) What textual features are most suitable for different visual text processing tasks? (2) How can these distinctive text features be effectively incorporated into processing frameworks? Furthermore, we introduce VTPBench, a new benchmark that encompasses a broad range of visual text processing datasets. Leveraging the advanced visual quality assessment capabilities of multimodal large language models (MLLMs), we propose VTPScore, a novel evaluation metric designed to ensure fair and reliable evaluation. Our empirical study with more than 20 specific models reveals substantial room for improvement in the current techniques. Our aim is to establish this work as a fundamental resource that fosters future exploration and innovation in the dynamic field of visual text processing. The relevant repository is available at https://github.com/shuyansy/Visual-Text-Processing-survey.