Mcity Data Engine: Iterative Model Improvement Through Open-Vocabulary Data Selection
作者: Daniel Bogdoll, Rajanikant Patnaik Ananta, Abeyankar Giridharan, Isabel Moore, Gregory Stevens, Henry X. Liu
分类: cs.CV
发布日期: 2025-04-30 (更新: 2025-07-26)
备注: Accepted for publication at ITSC 2025
🔗 代码/项目: GITHUB
💡 一句话要点
Mcity数据引擎:通过开放词汇数据选择迭代改进智能交通系统模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 智能交通系统 数据引擎 开放词汇 数据选择 长尾学习
📋 核心要点
- 智能交通系统数据量巨大,但人工标注成本高昂,难以有效选择和标注训练样本,尤其对于长尾类别。
- Mcity数据引擎通过开放词汇数据选择,自动挖掘和选择稀有类别数据,从而提升模型对这些类别的识别能力。
- 该引擎提供从数据采集到模型部署的完整流程,并开源代码,旨在促进智能交通系统研究的开放协作。
📝 摘要(中文)
随着数据可用性的不断增长,为机器学习模型的训练选择和标注合适的样本变得越来越具有挑战性。尤其是在大量未标注数据中检测感兴趣的长尾类别非常困难。对于智能交通系统(ITS)而言,情况尤其如此,因为车辆和路边感知系统会生成大量的原始数据。虽然存在用于此类迭代数据选择和模型训练过程的工业专有数据引擎,但研究人员和开源社区缺乏一个公开可用的系统。我们提出了Mcity数据引擎,它为完整的数据驱动开发周期提供模块,从数据采集阶段开始到模型部署阶段结束。Mcity数据引擎通过开放词汇数据选择过程专注于稀有和新颖的类别。所有代码都可以在GitHub上以MIT许可证公开获得。
🔬 方法详解
问题定义:论文旨在解决智能交通系统(ITS)中,由于数据量庞大且长尾类别数据稀缺,导致机器学习模型难以有效训练的问题。现有方法依赖人工标注,成本高昂且难以覆盖所有类别,尤其对于罕见或新出现的类别。
核心思路:论文的核心思路是利用“开放词汇数据选择”方法,自动从海量未标注数据中挖掘和选择包含目标类别的数据样本。通过迭代地选择数据、训练模型、评估模型并改进数据选择策略,逐步提升模型对长尾类别的识别能力。这种方法避免了对所有数据进行标注的需求,降低了成本并提高了效率。
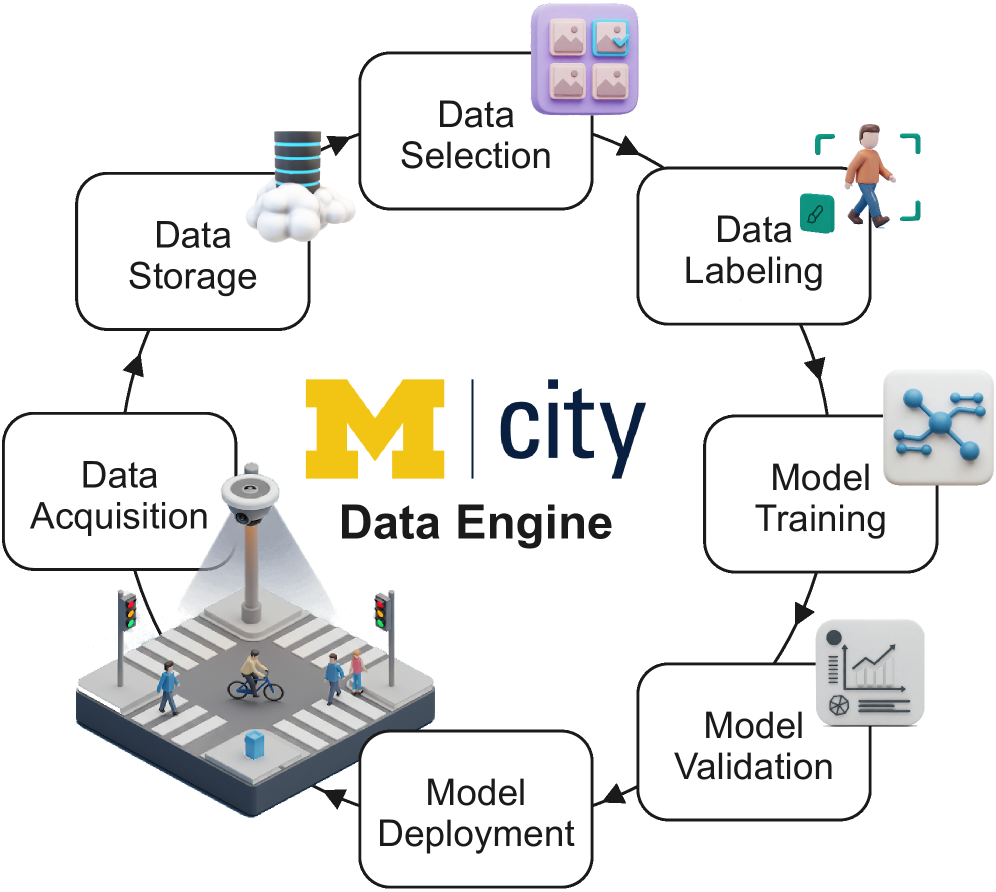
技术框架:Mcity数据引擎包含以下主要模块:1) 数据采集模块:负责从车辆、路边传感器等来源收集原始数据。2) 数据选择模块:利用开放词汇数据选择策略,从海量数据中筛选出可能包含目标类别的数据样本。3) 模型训练模块:使用选择的数据训练机器学习模型。4) 模型评估模块:评估模型在验证集上的性能,并根据评估结果调整数据选择策略。5) 模型部署模块:将训练好的模型部署到实际应用中。
关键创新:该论文的关键创新在于提出了一个完整的、开源的智能交通系统数据引擎,并采用了开放词汇数据选择策略。与传统的依赖人工标注或闭源数据引擎的方法相比,Mcity数据引擎能够更有效地利用海量未标注数据,并专注于稀有和新颖的类别。
关键设计:开放词汇数据选择策略是该引擎的关键设计。具体实现细节未知,但推测可能涉及使用预训练的视觉模型或自然语言处理模型来识别图像或文本中包含的物体或概念,并根据这些信息选择数据。损失函数和网络结构的选择取决于具体的机器学习任务(例如,目标检测、图像分类等)。数据选择策略的迭代改进可能基于主动学习或强化学习等技术。
🖼️ 关键图片


📊 实验亮点
由于论文摘要中没有提供具体的实验结果,因此无法总结实验亮点。需要查阅论文全文才能了解具体的性能数据、对比基线和提升幅度。但可以推测,该引擎在长尾类别识别方面应该优于传统的依赖人工标注的方法。
🎯 应用场景
Mcity数据引擎可应用于智能交通系统的多个领域,例如自动驾驶、交通监控、车辆安全等。通过提升模型对长尾类别的识别能力,可以提高自动驾驶系统的鲁棒性和安全性,改善交通监控系统的准确性,并为车辆安全提供更可靠的保障。该引擎的开源特性也促进了智能交通系统研究的开放协作。
📄 摘要(原文)
With an ever-increasing availability of data, it has become more and more challenging to select and label appropriate samples for the training of machine learning models. It is especially difficult to detect long-tail classes of interest in large amounts of unlabeled data. This holds especially true for Intelligent Transportation Systems (ITS), where vehicle fleets and roadside perception systems generate an abundance of raw data. While industrial, proprietary data engines for such iterative data selection and model training processes exist, researchers and the open-source community suffer from a lack of an openly available system. We present the Mcity Data Engine, which provides modules for the complete data-based development cycle, beginning at the data acquisition phase and ending at the model deployment stage. The Mcity Data Engine focuses on rare and novel classes through an open-vocabulary data selection process. All code is publicly available on GitHub under an MIT license: https://github.com/mcity/mcity_data_engine