MemeBLIP2: A novel lightweight multimodal system to detect harmful memes
作者: Jiaqi Liu, Ran Tong, Aowei Shen, Shuzheng Li, Changlin Yang, Lisha Xu
分类: cs.CV, cs.AI
发布日期: 2025-04-29 (更新: 2025-07-26)
备注: 11 pages, 3 figures. Accepted at the First Workshop on Multimodal Knowledge and Language Modeling (MKLM), IJCAI-25
💡 一句话要点
提出MemeBLIP2轻量级多模态系统,用于检测有害Meme内容
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 Meme检测 有害内容识别 视觉语言模型 BLIP-2 内容审核 社交媒体 轻量级模型
📋 核心要点
- 现有方法难以有效识别Meme中包含的细微的、具有文化背景的有害信息。
- MemeBLIP2通过对齐图像和文本表示,并进行有效融合,从而提升有害Meme的检测能力。
- 在PrideMM数据集上的实验表明,MemeBLIP2能够有效提升有害信息的检测效果。
📝 摘要(中文)
Meme通常将视觉元素与简短文本结合,以分享幽默或观点,但部分Meme包含仇恨言论等有害信息。本文提出了一种轻量级多模态系统MemeBLIP2,它通过有效结合图像和文本特征来检测有害Meme。该系统在先前研究的基础上,增加了将图像和文本表示对齐到共享空间的模块,并将它们融合以实现更好的分类。MemeBLIP2以BLIP-2作为核心视觉-语言模型,并在PrideMM数据集上进行了评估。结果表明,MemeBLIP2能够捕捉两种模态中的细微线索,即使在具有讽刺意味或文化特定内容的情况下,也能提高有害内容的检测效果。
🔬 方法详解
问题定义:该论文旨在解决有害Meme的自动检测问题。现有的方法在处理包含讽刺、文化特定内容或细微语义的Meme时,表现不佳,难以准确识别其中的有害信息。这些Meme通常需要对图像和文本进行深入理解和关联才能判断其是否具有危害性。
核心思路:论文的核心思路是利用多模态融合的方法,将图像和文本信息结合起来,从而更全面地理解Meme的内容。通过将图像和文本表示映射到同一个语义空间,可以更好地捕捉它们之间的关联性,从而提高有害Meme的检测准确率。
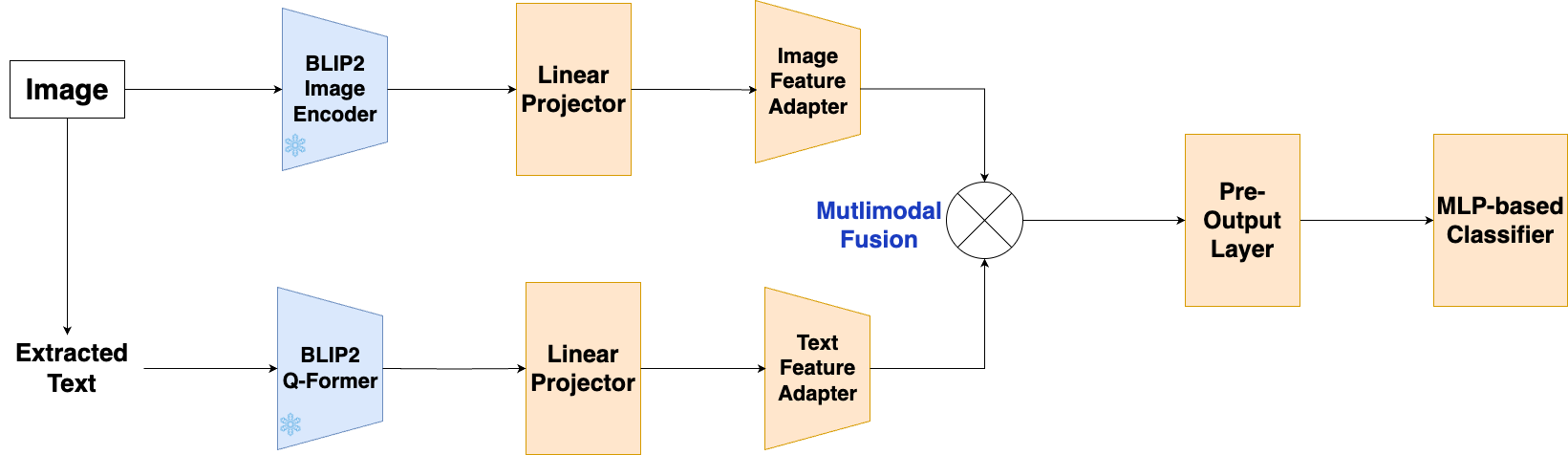
技术框架:MemeBLIP2以BLIP-2作为核心视觉-语言模型。整体框架包含以下几个主要模块:1) 图像编码器:用于提取图像的视觉特征。2) 文本编码器:用于提取文本的语义特征。3) 多模态对齐模块:将图像和文本特征映射到共享的语义空间,学习它们之间的对应关系。4) 多模态融合模块:将对齐后的图像和文本特征进行融合,得到最终的Meme表示。5) 分类器:根据Meme表示,判断其是否包含有害信息。
关键创新:MemeBLIP2的关键创新在于其轻量化的设计和有效的多模态融合策略。通过在BLIP-2的基础上添加专门的对齐和融合模块,该系统能够更好地捕捉图像和文本之间的细微关联,同时保持较低的计算复杂度。这种设计使得MemeBLIP2能够在资源有限的环境下高效地检测有害Meme。
关键设计:论文中可能涉及的关键设计细节包括:1) 多模态对齐模块的具体实现方式,例如使用对比学习或注意力机制。2) 多模态融合模块的结构,例如使用拼接、加权平均或Transformer等方法。3) 损失函数的设计,例如使用交叉熵损失或Focal Loss来优化分类器。4) 模型训练的超参数设置,例如学习率、batch size和训练轮数等。(具体细节需参考论文原文)
🖼️ 关键图片


📊 实验亮点
MemeBLIP2在PrideMM数据集上进行了评估,实验结果表明,该系统能够有效捕捉图像和文本中的细微线索,即使在具有讽刺意味或文化特定内容的情况下,也能提高有害内容的检测效果。具体的性能数据(例如准确率、召回率、F1值)以及与基线方法的对比结果需要在论文中查找。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,自动检测和过滤有害Meme,从而减少仇恨言论、网络欺凌等不良信息的传播。此外,该技术还可以用于构建更安全的在线社区,提升用户体验,并为社会和谐做出贡献。未来,该技术有望扩展到其他多模态内容审核场景,例如视频和音频内容。
📄 摘要(原文)
Memes often merge visuals with brief text to share humor or opinions, yet some memes contain harmful messages such as hate speech. In this paper, we introduces MemeBLIP2, a light weight multimodal system that detects harmful memes by combining image and text features effectively. We build on previous studies by adding modules that align image and text representations into a shared space and fuse them for better classification. Using BLIP-2 as the core vision-language model, our system is evaluated on the PrideMM datasets. The results show that MemeBLIP2 can capture subtle cues in both modalities, even in cases with ironic or culturally specific content, thereby improving the detection of harmful material.