AlignDiT: Multimodal Aligned Diffusion Transformer for Synchronized Speech Generation
作者: Jeongsoo Choi, Ji-Hoon Kim, Kim Sung-Bin, Tae-Hyun Oh, Joon Son Chung
分类: cs.CV, cs.AI, cs.MM
发布日期: 2025-04-29 (更新: 2025-10-03)
备注: ACM Multimedia 2025
💡 一句话要点
AlignDiT:多模态对齐扩散Transformer用于同步语音生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态语音生成 扩散Transformer 音视频同步 说话人相似度 无分类器引导 多模态对齐 DiT
📋 核心要点
- 现有方法在多模态语音生成中,语音清晰度、音视频同步以及说话人相似度方面存在不足。
- AlignDiT利用扩散Transformer的上下文学习能力,通过对齐多模态表示来解决上述问题。
- 实验结果表明,AlignDiT在语音质量、同步性和说话人相似性方面均优于现有方法,并具有良好的泛化能力。
📝 摘要(中文)
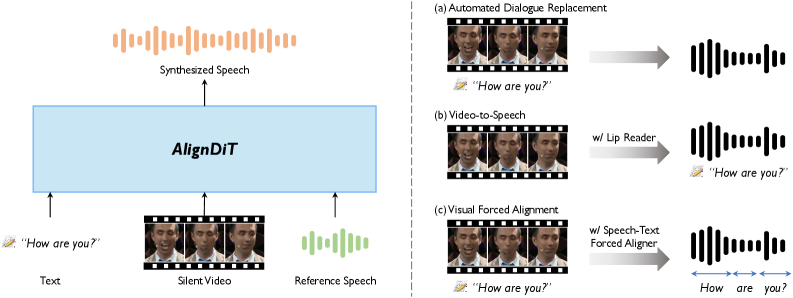
本文提出了一种多模态到语音生成的方法,旨在从文本、视频和参考音频等多种输入模态合成高质量的语音。该任务在电影制作、配音和虚拟化身等领域具有广泛的应用前景。然而,现有方法在语音清晰度、音视频同步、语音自然度和与参考说话人的声音相似度方面仍存在局限性。为了解决这些挑战,我们提出了AlignDiT,一种多模态对齐扩散Transformer,它可以从对齐的多模态输入中生成准确、同步且听起来自然的语音。AlignDiT基于DiT架构的上下文学习能力,探索了三种有效的策略来对齐多模态表示。此外,我们还引入了一种新颖的多模态无分类器引导机制,使模型能够在语音合成过程中自适应地平衡来自每种模态的信息。大量实验表明,AlignDiT在质量、同步性和说话人相似性方面显著优于现有方法。此外,AlignDiT在各种多模态任务(如视频到语音合成和视觉强制对齐)中表现出强大的泛化能力,始终达到最先进的性能。
🔬 方法详解
问题定义:论文旨在解决多模态输入(文本、视频、参考音频)到高质量语音生成的问题。现有方法在音视频同步、语音自然度、说话人相似度等方面存在不足,难以生成高质量且与参考说话人一致的语音。
核心思路:论文的核心思路是利用扩散Transformer(DiT)的强大生成能力和上下文学习能力,通过有效对齐多模态信息,并引入多模态无分类器引导机制,从而生成高质量、同步且具有说话人特征的语音。
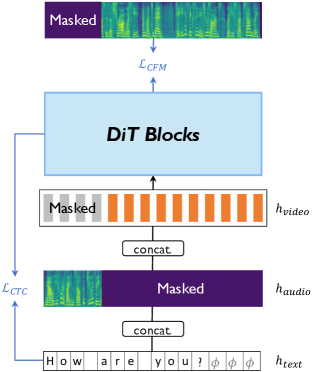
技术框架:AlignDiT的整体框架基于扩散模型,采用DiT作为核心生成器。输入包括文本、视频和参考音频,通过各自的编码器提取特征。关键在于设计了三种对齐策略,将多模态特征对齐到统一的表示空间。然后,DiT利用对齐后的特征生成语音频谱,最后通过声码器合成语音。此外,还引入了多模态无分类器引导机制,用于控制不同模态信息对生成过程的影响。
关键创新:论文的关键创新在于:1) 提出了三种有效的多模态对齐策略,能够更好地融合不同模态的信息;2) 引入了多模态无分类器引导机制,可以自适应地平衡不同模态信息对语音生成的影响,从而提高生成语音的质量和可控性。
关键设计:论文中,三种多模态对齐策略的具体实现细节未知,但强调了对齐的重要性。多模态无分类器引导机制通过调整不同模态的条件概率来实现,具体公式和参数设置未知。DiT的具体网络结构和训练细节也未详细描述,但强调了其强大的生成能力。
🖼️ 关键图片

📊 实验亮点
AlignDiT在多个基准测试中显著优于现有方法,在语音质量、音视频同步性和说话人相似性方面均取得了显著提升。此外,AlignDiT在视频到语音合成和视觉强制对齐等任务中也表现出强大的泛化能力,始终保持领先水平。具体性能数据和提升幅度在论文中未明确给出。
🎯 应用场景
该研究成果可广泛应用于电影制作、配音、虚拟化身等领域,能够根据视频内容、文本描述和参考音频自动生成高质量的同步语音,极大地提高了相关工作的效率和质量。未来,该技术还可能应用于语音助手、智能客服等领域,实现更加自然和个性化的语音交互。
📄 摘要(原文)
In this paper, we address the task of multimodal-to-speech generation, which aims to synthesize high-quality speech from multiple input modalities: text, video, and reference audio. This task has gained increasing attention due to its wide range of applications, such as film production, dubbing, and virtual avatars. Despite recent progress, existing methods still suffer from limitations in speech intelligibility, audio-video synchronization, speech naturalness, and voice similarity to the reference speaker. To address these challenges, we propose AlignDiT, a multimodal Aligned Diffusion Transformer that generates accurate, synchronized, and natural-sounding speech from aligned multimodal inputs. Built upon the in-context learning capability of the DiT architecture, AlignDiT explores three effective strategies to align multimodal representations. Furthermore, we introduce a novel multimodal classifier-free guidance mechanism that allows the model to adaptively balance information from each modality during speech synthesis. Extensive experiments demonstrate that AlignDiT significantly outperforms existing methods across multiple benchmarks in terms of quality, synchronization, and speaker similarity. Moreover, AlignDiT exhibits strong generalization capability across various multimodal tasks, such as video-to-speech synthesis and visual forced alignment, consistently achieving state-of-the-art performance. The demo page is available at https://mm.kaist.ac.kr/projects/AlignDiT.