DeepInsert: Early Layer Bypass for Efficient and Performant Multimodal Understanding
作者: Moulik Choraria, Xinbo Wu, Akhil Bhimaraju, Nitesh Sekhar, Yue Wu, Xu Zhang, Prateek Singhal, Lav R. Varshney
分类: cs.CV, cs.AI
发布日期: 2025-04-27 (更新: 2025-09-21)
💡 一句话要点
DeepInsert:通过早期层旁路提升多模态理解的效率与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 Transformer模型 早期层旁路 计算效率 资源优化
📋 核心要点
- 现有Transformer模型在多模态学习中,处理多模态数据计算开销大,限制了实际应用。
- DeepInsert通过将多模态token直接插入到中间层,绕过早期层,减少计算量。
- 实验表明,该方法在视觉、音频和分子数据等多模态任务中,降低计算成本的同时,保持甚至提升了性能。
📝 摘要(中文)
Transformer模型的数据和参数规模的过度增长,导致性能提升逐渐减缓,尤其是在考虑训练成本时。这种瓶颈凸显了对更高效的微调和推理的需求,同时不牺牲性能。这对于多模态学习尤为重要,因为处理多模态token的开销通常限制了这些系统的实际可行性。与此同时,表征学习和可解释性的进展加深了我们对模型如何处理和编码信息的理解。值得注意的是,最近的研究揭示了大型预训练模型深层中存在隐式的跨模态对齐。这与我们自己的观察结果一致,即模型自然地将大多数跨模态token交互推迟到更深的计算阶段。基于此,我们提出了一种简单的修改方法:将多模态token直接插入到中间层,而不是在开始时与语言提示连接,从而允许它们完全绕过早期层。我们对视觉(LLaVA & BLIP)、音频(LTU)和分子数据(MoLCA)等多种模态的结果表明,我们的方法降低了训练和推理过程中的计算成本,同时至少保持,甚至超过了现有基线的性能。我们的工作对于以资源高效的方式扩展和组合预训练模型具有重要意义。
🔬 方法详解
问题定义:现有的大型Transformer模型在处理多模态数据时,通常采用将多模态token与语言提示在模型输入端进行拼接的方式。这种方式的缺点在于,模型的所有层都需要处理这些多模态token,即使早期层可能并不需要进行复杂的跨模态交互,从而造成了计算资源的浪费。因此,需要解决的问题是如何在不牺牲性能的前提下,降低多模态Transformer模型的计算成本,提高效率。
核心思路:论文的核心思路是观察到大型预训练模型通常在较深的层中才进行有效的跨模态信息融合。因此,可以将多模态token直接插入到模型的中间层,让它们绕过早期层,从而减少早期层的计算负担。这种做法基于一个假设,即早期层主要负责处理语言信息,而跨模态信息的融合可以延迟到更深的层进行。
技术框架:DeepInsert方法的核心在于修改了多模态数据的输入方式。传统的输入方式是将多模态token与语言prompt在输入层进行拼接。而DeepInsert方法则是将多模态token插入到Transformer模型的中间层。具体来说,需要确定一个插入层的位置,这个位置的选择可能需要根据具体的任务和模型进行调整。插入层之后的层将同时处理语言和多模态信息,而之前的层则只处理语言信息。
关键创新:DeepInsert的关键创新在于提出了“早期层旁路”的概念,即让多模态token绕过Transformer模型的早期层。这种做法与传统的输入方式不同,它充分利用了模型不同层的功能差异,将跨模态信息融合的任务交给更适合的深层网络,从而提高了计算效率。这种方法的核心在于对模型结构的理解,以及对不同层功能的合理分配。
关键设计:DeepInsert方法的关键设计在于确定多模态token的插入位置。论文中并没有明确说明如何选择最佳的插入位置,这可能需要根据具体的任务和模型进行实验调整。此外,还需要考虑如何处理不同模态token的长度差异,以及如何保证插入后的token能够与语言token进行有效的交互。这些都是在实际应用中需要考虑的关键技术细节。论文中没有明确提及具体的参数设置、损失函数或网络结构上的修改,重点在于输入方式的改变。
🖼️ 关键图片
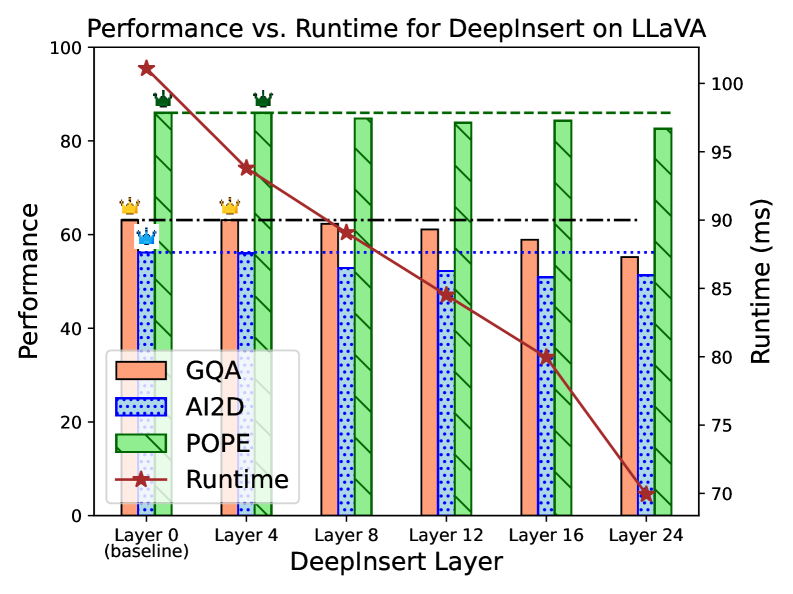
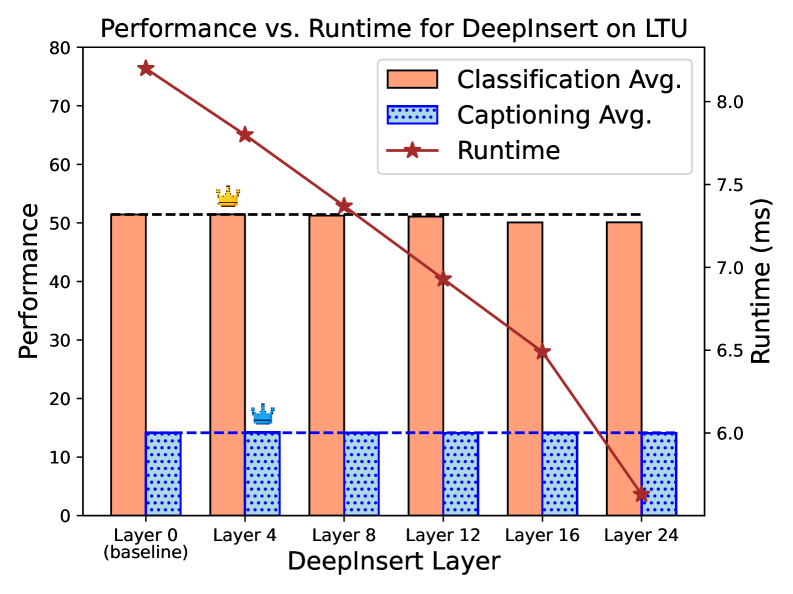
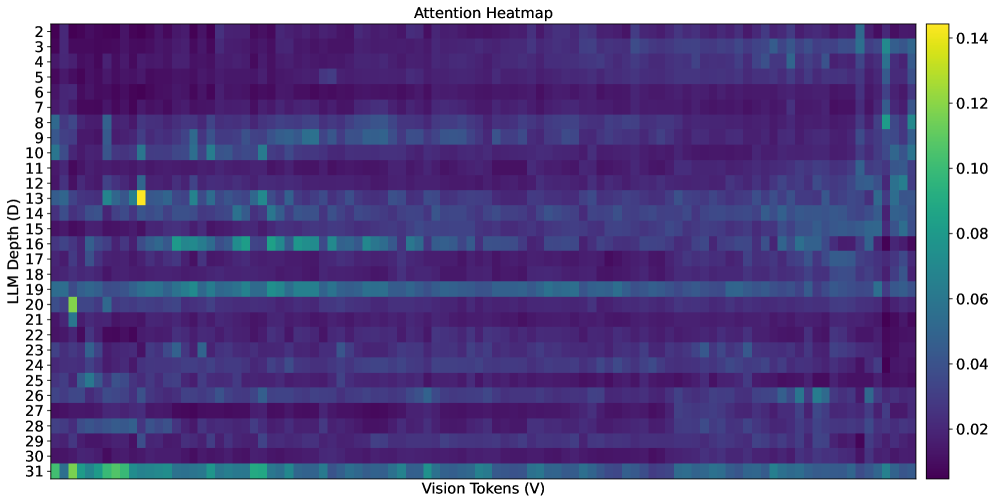
📊 实验亮点
实验结果表明,DeepInsert方法在视觉(LLaVA & BLIP)、音频(LTU)和分子数据(MoLCA)等多种模态的任务中,能够在降低计算成本的同时,保持甚至超过现有基线的性能。具体的性能提升幅度和计算成本降低比例在论文中没有给出明确的数据,但总体趋势是积极的,表明该方法具有实际应用价值。
🎯 应用场景
DeepInsert方法可应用于各种多模态学习场景,例如视觉-语言理解、语音-文本翻译、以及分子性质预测等。该方法通过降低计算成本,使得在资源受限的环境下部署大型多模态模型成为可能。此外,该方法还可以促进对多模态Transformer模型内部工作机制的理解,为未来的模型设计提供新的思路。
📄 摘要(原文)
The hyperscaling of data and parameter count in transformer models is yielding diminishing performance improvement, especially when weighed against training costs. Such plateauing underlines a growing need for more efficient finetuning and inference, without sacrificing performance. This is particularly pressing for multimodal learning, where the overhead of processing multimodal tokens alongside language data often limits the practical viability of these systems. In parallel, advances in representation learning and interpretability have deepened our understanding of how such models process and encode information. Notably, recent work has uncovered implicit cross-modal alignment in the deeper layers of large pretrained models. Interestingly, this aligns with our own observations that models naturally defer most cross-modal token interactions to deeper stages of computation. Building on this, we propose a simple modification. Instead of concatenation with the language prompt at the start, we insert multimodal tokens directly into the middle, allowing them to entirely bypass the early layers. Our results with diverse modalities: 1) LLaVA \& BLIP for vision, 2) LTU for audio, and 3) MoLCA for molecular data, indicate that our method reduces computational costs during both training and inference, while at the very least, preserving, if not surpassing the performance of existing baselines. Our work has important implications for scaling and composing pretrained models in a resource-efficient manner.