OpenFusion++: An Open-vocabulary Real-time Scene Understanding System
作者: Xiaofeng Jin, Matteo Frosi, Matteo Matteucci
分类: cs.CV
发布日期: 2025-04-27
备注: 8 pages, 9 figures
💡 一句话要点
提出OpenFusion++,实现开放词汇实时场景理解,提升3D感知的精度和响应速度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇场景理解 实时3D重建 TSDF 语义分割 视觉语言导航
📋 核心要点
- 现有方法在实例分割精度、静态语义更新以及处理复杂查询方面存在不足,难以满足视觉语言导航等应用需求。
- OpenFusion++通过融合置信度图优化点云,自适应更新语义标签,并采用双路径编码融合对象属性和环境上下文。
- 实验结果表明,OpenFusion++在ICL、Replica、ScanNet和ScanNet++数据集上,显著提升了语义准确性和查询响应速度。
📝 摘要(中文)
本文提出OpenFusion++,一个基于TSDF的实时3D语义几何重建系统,用于解决开放词汇场景理解问题。该系统通过融合基础模型的置信度图来优化3D点云,利用基于实例面积的自适应缓存动态更新全局语义标签,并采用双路径编码框架,将对象属性与环境上下文相结合,以实现精确的查询响应。在ICL、Replica、ScanNet和ScanNet++数据集上的实验表明,OpenFusion++在语义准确性和查询响应速度方面均显著优于基线方法。
🔬 方法详解
问题定义:现有开放词汇场景理解方法在3D感知中面临精度和效率的挑战。具体来说,实例分割不够精确,语义更新是静态的,无法适应动态环境,并且难以处理复杂的查询请求,限制了其在机器人、增强现实等领域的应用。
核心思路:OpenFusion++的核心在于利用预训练的基础模型(foundational models)的强大语义理解能力,并将其与传统的TSDF(Truncated Signed Distance Function)重建方法相结合,从而实现高精度、实时的3D场景理解。通过动态更新语义标签和融合环境上下文信息,提升了系统对复杂查询的响应能力。
技术框架:OpenFusion++系统主要包含以下几个模块:1) 点云优化模块:融合基础模型的置信度图,对3D点云进行优化,提升几何精度。2) 语义更新模块:基于实例面积的自适应缓存机制,动态更新全局语义标签,适应环境变化。3) 查询响应模块:采用双路径编码框架,同时考虑对象属性和环境上下文,实现精确的查询响应。整个系统基于TSDF进行3D重建,并实时更新语义信息。
关键创新:OpenFusion++的关键创新在于:1) 融合基础模型置信度图:利用预训练模型的语义信息来指导点云优化,提升重建精度。2) 自适应语义更新:根据实例面积动态调整语义标签,适应环境变化,避免静态语义带来的误差。3) 双路径编码框架:同时考虑对象属性和环境上下文,提升查询响应的准确性。
关键设计:关于关键设计,论文中未提供足够的技术细节,例如具体的置信度图融合方法、自适应缓存的参数设置、双路径编码框架的网络结构和损失函数等。这些细节需要参考论文原文或补充材料才能进一步了解。自适应缓存可能涉及到缓存大小、替换策略等参数的设置。双路径编码框架可能包含特定的网络结构,例如Transformer或GNN,以及相应的损失函数来训练模型。
🖼️ 关键图片
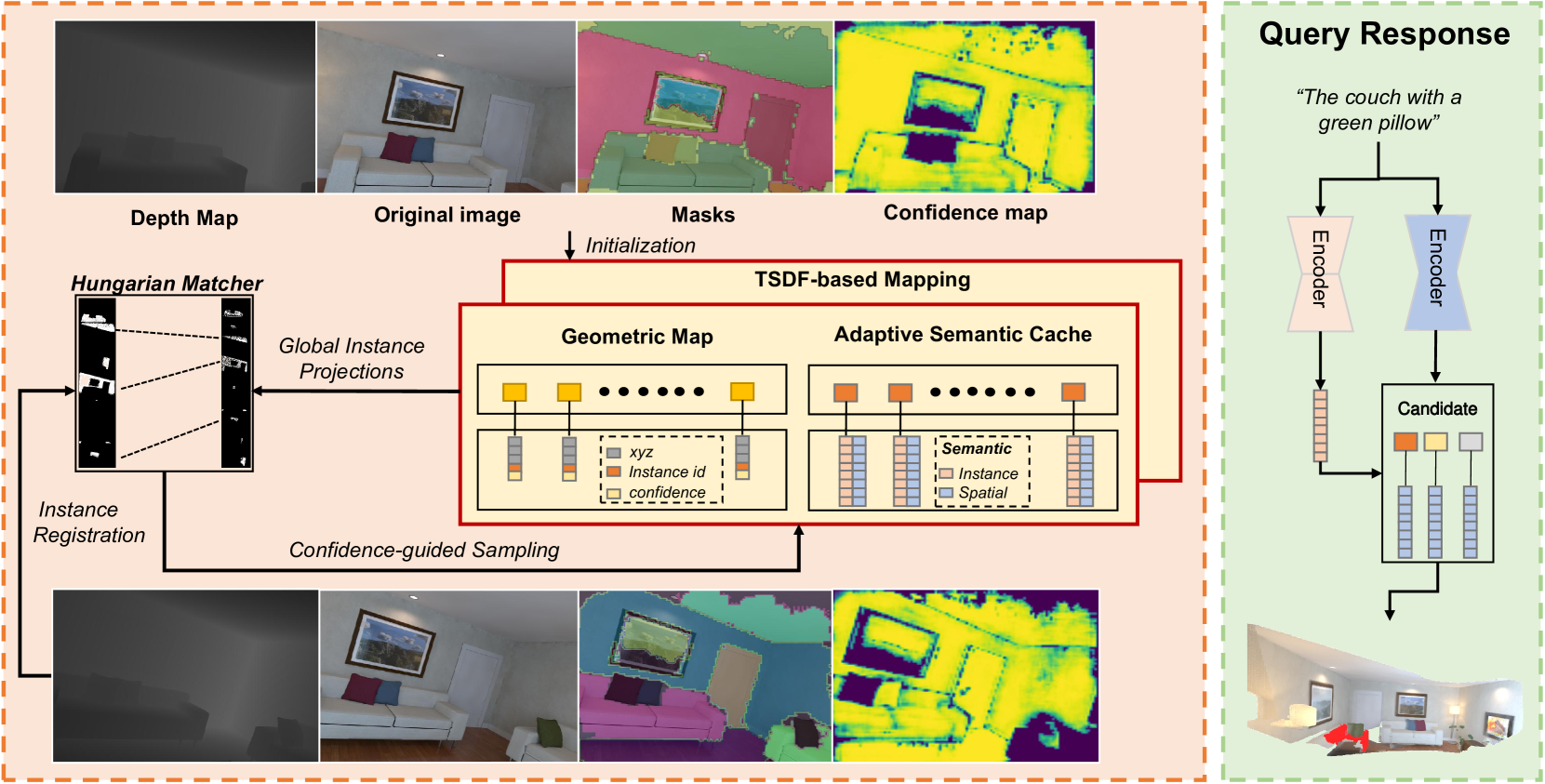

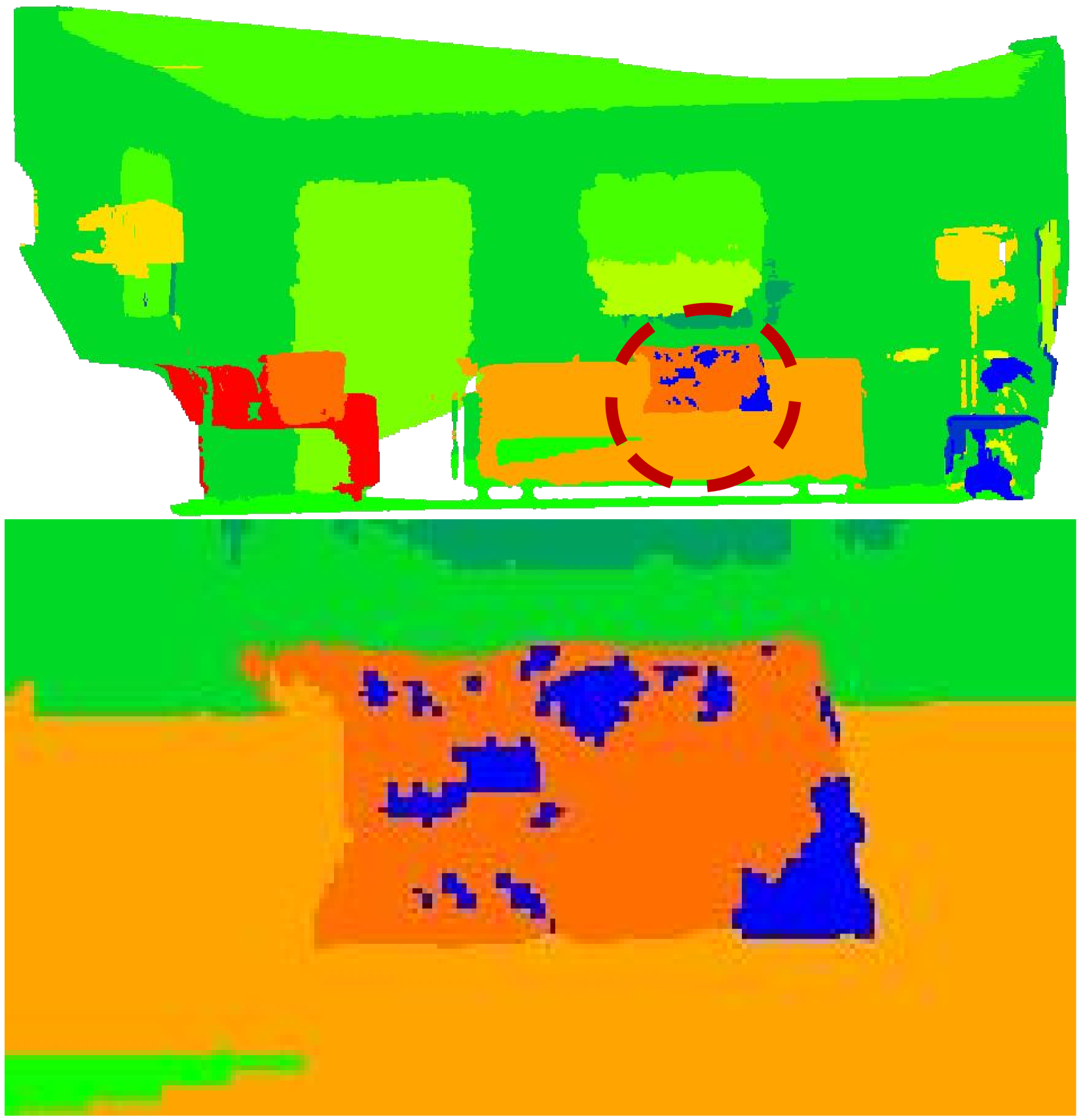
📊 实验亮点
OpenFusion++在ICL、Replica、ScanNet和ScanNet++数据集上进行了评估,实验结果表明,该方法在语义准确性和查询响应速度方面均显著优于基线方法。具体的性能提升数据需要在论文中查找,例如在ScanNet++数据集上,OpenFusion++可能在mIoU等指标上取得了显著的提升。
🎯 应用场景
OpenFusion++在视觉语言导航、具身智能和增强现实等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在增强现实中,它可以提供更精确的场景理解,从而实现更逼真的虚拟内容叠加。该研究的未来影响在于推动3D感知技术的发展,使其能够更好地理解和适应复杂多变的真实世界。
📄 摘要(原文)
Real-time open-vocabulary scene understanding is essential for efficient 3D perception in applications such as vision-language navigation, embodied intelligence, and augmented reality. However, existing methods suffer from imprecise instance segmentation, static semantic updates, and limited handling of complex queries. To address these issues, we present OpenFusion++, a TSDF-based real-time 3D semantic-geometric reconstruction system. Our approach refines 3D point clouds by fusing confidence maps from foundational models, dynamically updates global semantic labels via an adaptive cache based on instance area, and employs a dual-path encoding framework that integrates object attributes with environmental context for precise query responses. Experiments on the ICL, Replica, ScanNet, and ScanNet++ datasets demonstrate that OpenFusion++ significantly outperforms the baseline in both semantic accuracy and query responsiveness.