Learning to Drive from a World Model
作者: Mitchell Goff, Greg Hogan, George Hotz, Armand du Parc Locmaria, Kacper Raczy, Harald Schäfer, Adeeb Shihadeh, Weixing Zhang, Yassine Yousfi
分类: cs.CV, cs.RO
发布日期: 2025-04-27
💡 一句话要点
提出基于世界模型的端到端自动驾驶学习框架,无需人工规则。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 端到端学习 世界模型 驾驶策略 模拟器
📋 核心要点
- 现有自动驾驶系统依赖手工规则,难以扩展且复杂。
- 提出端到端训练架构,利用真实驾驶数据训练驾驶策略。
- 通过重投影模拟和学习世界模型两种方式进行策略训练。
📝 摘要(中文)
大多数自动驾驶系统依赖于手工编码的感知输出和工程化的驾驶规则。直接从人类驾驶数据中进行端到端学习,可以简化训练架构,并随着计算和数据的增长而良好扩展。本文提出了一种端到端训练架构,该架构使用真实驾驶数据在on-policy模拟器中训练驾驶策略。我们展示了两种不同的模拟方法,一种是重投影模拟,另一种是学习的世界模型。我们证明了这两种方法都可以用来训练策略,从而在没有任何手工编码的驾驶规则的情况下学习驾驶行为。我们在闭环模拟中以及在真实世界的高级驾驶辅助系统中评估了这些策略的性能。
🔬 方法详解
问题定义:现有自动驾驶系统依赖于手工编码的感知输出和人为设计的驾驶规则,这使得系统复杂且难以维护和扩展。此外,手工设计的规则难以适应各种复杂的驾驶场景,泛化能力有限。因此,需要一种能够直接从数据中学习驾驶策略的方法,以简化系统并提高其适应性。
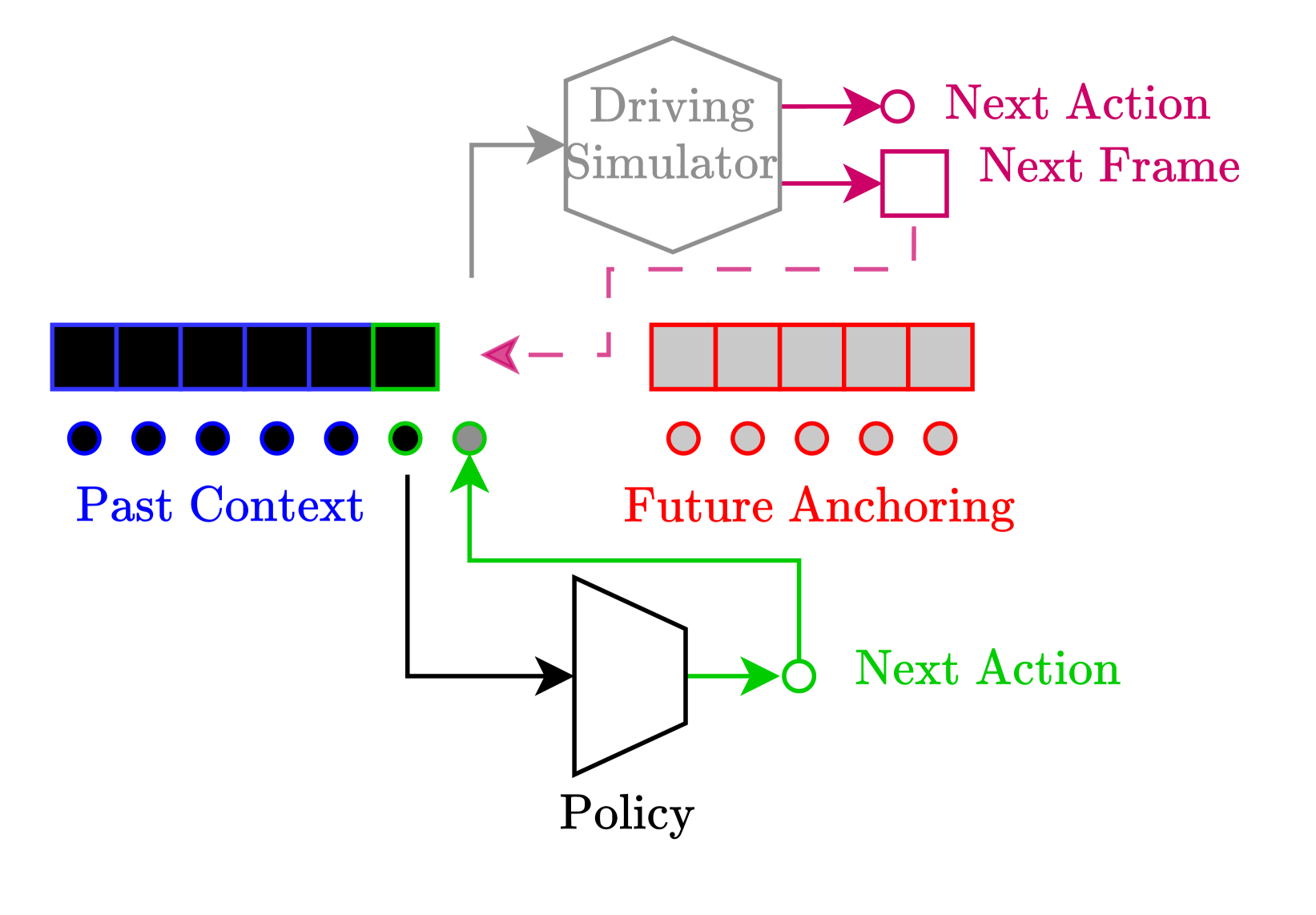
核心思路:本文的核心思路是利用端到端的学习方法,直接从人类驾驶数据中学习驾驶策略。通过构建一个模拟环境,并在该环境中训练驾驶策略,从而避免了手工设计规则的需要。该方法的核心在于如何构建一个能够准确反映真实世界驾驶环境的模拟器,并利用该模拟器进行有效的策略训练。
技术框架:该框架包含两个主要的组成部分:模拟器和策略网络。模拟器负责生成驾驶环境,并提供策略网络与环境交互的接口。策略网络接收来自模拟器的输入(例如,图像),并输出驾驶指令(例如,转向、加速)。该框架使用on-policy的方法进行训练,即策略网络在模拟器中生成数据,并使用这些数据来更新策略网络。论文中提出了两种不同的模拟方法:重投影模拟和学习的世界模型。重投影模拟使用真实世界的驾驶数据来构建模拟环境,而学习的世界模型则通过学习真实世界驾驶数据的潜在表示来构建模拟环境。
关键创新:该论文的关键创新在于提出了一种基于学习的世界模型的端到端自动驾驶学习框架。与传统的依赖手工规则的自动驾驶系统相比,该框架能够直接从数据中学习驾驶策略,从而简化了系统并提高了其适应性。此外,该论文还提出了一种新的模拟方法,即学习的世界模型,该方法能够通过学习真实世界驾驶数据的潜在表示来构建模拟环境,从而提高了模拟器的真实性和有效性。
关键设计:在重投影模拟中,关键在于如何将真实世界的驾驶数据映射到模拟环境中。在学习的世界模型中,关键在于如何设计一个能够准确学习真实世界驾驶数据潜在表示的模型。具体的网络结构和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文展示了两种不同的模拟方法(重投影模拟和学习的世界模型)均可用于训练驾驶策略,而无需任何手工编码的驾驶规则。策略在闭环模拟和真实世界高级驾驶辅助系统中的性能得到了验证,但具体的性能指标和提升幅度未知。
🎯 应用场景
该研究成果可应用于高级驾驶辅助系统(ADAS)和自动驾驶汽车。通过学习人类驾驶行为,可以提高自动驾驶系统的安全性和舒适性。此外,该方法还可以用于训练自动驾驶系统在各种复杂驾驶场景下的行为,例如城市道路、高速公路等。未来,该技术有望推动自动驾驶技术的普及和应用。
📄 摘要(原文)
Most self-driving systems rely on hand-coded perception outputs and engineered driving rules. Learning directly from human driving data with an end-to-end method can allow for a training architecture that is simpler and scales well with compute and data. In this work, we propose an end-to-end training architecture that uses real driving data to train a driving policy in an on-policy simulator. We show two different methods of simulation, one with reprojective simulation and one with a learned world model. We show that both methods can be used to train a policy that learns driving behavior without any hand-coded driving rules. We evaluate the performance of these policies in a closed-loop simulation and when deployed in a real-world advanced driver-assistance system.