Sim-to-Real: An Unsupervised Noise Layer for Screen-Camera Watermarking Robustness
作者: Yufeng Wu, Xin Liao, Baowei Wang, Han Fang, Xiaoshuai Wu, Mingyue Chen, Guiling Wang
分类: cs.CV
发布日期: 2025-04-26 (更新: 2025-11-12)
备注: Accepted by AAAI-2026
💡 一句话要点
提出一种无监督噪声层Sim-to-Real方法,提升屏幕-相机水印的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 屏幕相机水印 鲁棒性 无监督学习 Sim-to-Real 噪声建模
📋 核心要点
- 现有屏幕-相机水印方法依赖启发式建模或监督学习,难以准确模拟真实噪声,限制了水印鲁棒性。
- 提出Sim-to-Real方法,利用无监督学习缩小模拟噪声和真实噪声分布的差距,简化了噪声学习过程。
- 实验表明,该方法在水印鲁棒性和泛化性方面优于现有技术,验证了其有效性。
📝 摘要(中文)
未经授权的屏幕捕获和传播构成了严重的安全威胁,例如数据泄露和信息盗窃。一些研究提出了鲁棒的水印方法来追踪屏幕-相机(SC)图像的版权,从而促进对侵权行为的事后认证。这些技术通常采用启发式数学建模或监督神经网络拟合作为噪声层,以增强水印对SC的鲁棒性。然而,这两种策略都无法从根本上实现对SC噪声的有效近似。数学模拟由于噪声的不完全分解以及噪声分量之间缺乏相互依赖性而遭受有偏差的近似。监督网络需要配对数据来训练噪声拟合模型,并且该模型难以学习噪声的所有特征。为了解决上述问题,我们提出了Simulation-to-Real(S2R)。具体而言,一种无监督噪声层采用非配对数据来学习建模的模拟噪声分布与真实世界SC噪声分布之间的差异,而不是直接学习从清晰图像到真实世界图像的映射。学习这种从模拟到现实的转换本质上更简单,因为它主要涉及弥合噪声分布中的差距,而不是重建细粒度图像细节的复杂任务。大量的实验结果验证了所提出方法的有效性,证明了与最先进的方法相比,其具有优越的水印鲁棒性和泛化能力。
🔬 方法详解
问题定义:论文旨在解决屏幕-相机(SC)场景下水印鲁棒性问题。现有方法,如数学建模和监督学习,在模拟真实SC噪声方面存在局限性。数学建模难以完整分解噪声成分及其相互依赖关系,导致模拟噪声与真实噪声存在偏差。监督学习则依赖配对数据,难以捕捉所有噪声特征,泛化能力受限。
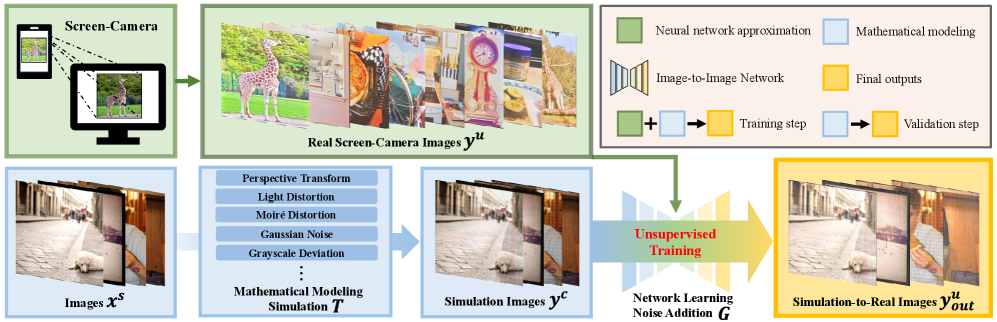
核心思路:论文的核心思路是利用无监督学习,学习模拟噪声分布到真实噪声分布的转换。相比直接学习清晰图像到真实图像的复杂映射,学习噪声分布的转换更为简单,只需弥合噪声分布的差距。这种“Simulation-to-Real”的方法能够更有效地模拟真实SC噪声,从而提升水印的鲁棒性。
技术框架:S2R框架包含两个主要部分:模拟噪声生成器和无监督噪声层。首先,使用传统的数学模型生成模拟的SC噪声。然后,无监督噪声层利用非配对的模拟噪声和真实SC图像数据,学习两者之间的分布差异。该噪声层可以采用生成对抗网络(GAN)或其他无监督学习方法实现。最终,将学习到的噪声层应用于水印嵌入和提取过程,以增强水印的鲁棒性。
关键创新:该论文的关键创新在于提出了一种无监督的噪声层,用于学习模拟噪声到真实噪声的转换。与传统的监督学习方法相比,该方法不需要配对数据,降低了数据收集的成本。同时,通过学习噪声分布的转换,能够更有效地模拟真实SC噪声,提升水印的鲁棒性和泛化能力。
关键设计:具体的网络结构和损失函数选择取决于所采用的无监督学习方法。例如,如果使用GAN,则需要设计生成器和判别器的网络结构,并选择合适的对抗损失函数。此外,还可以引入其他的正则化项,以提高模型的稳定性和泛化能力。论文中可能还涉及到一些针对SC噪声特点的特殊设计,例如针对特定噪声成分的建模或处理。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的Sim-to-Real方法在水印鲁棒性和泛化性方面优于现有技术。具体而言,在各种屏幕-相机噪声条件下,该方法能够显著提高水印的检出率,并降低误检率。与最先进的方法相比,该方法在某些指标上取得了显著的提升,验证了其有效性。
🎯 应用场景
该研究成果可应用于数字版权保护、信息安全等领域。通过提高屏幕-相机水印的鲁棒性,可以有效追踪未经授权的屏幕捕获和传播行为,防止数据泄露和信息盗窃。未来,该技术可进一步应用于移动支付、在线教育等场景,保障用户权益和数据安全。
📄 摘要(原文)
Unauthorized screen capturing and dissemination pose severe security threats such as data leakage and information theft. Several studies propose robust watermarking methods to track the copyright of Screen-Camera (SC) images, facilitating post-hoc certification against infringement. These techniques typically employ heuristic mathematical modeling or supervised neural network fitting as the noise layer, to enhance watermarking robustness against SC. However, both strategies cannot fundamentally achieve an effective approximation of SC noise. Mathematical simulation suffers from biased approximations due to the incomplete decomposition of the noise and the absence of interdependence among the noise components. Supervised networks require paired data to train the noise-fitting model, and it is difficult for the model to learn all the features of the noise. To address the above issues, we propose Simulation-to-Real (S2R). Specifically, an unsupervised noise layer employs unpaired data to learn the discrepancy between the modeled simulated noise distribution and the real-world SC noise distribution, rather than directly learning the mapping from sharp images to real-world images. Learning this transformation from simulation to reality is inherently simpler, as it primarily involves bridging the gap in noise distributions, instead of the complex task of reconstructing fine-grained image details. Extensive experimental results validate the efficacy of the proposed method, demonstrating superior watermark robustness and generalization compared to state-of-the-art methods.