SORT3D: Spatial Object-centric Reasoning Toolbox for Zero-Shot 3D Grounding Using Large Language Models
作者: Nader Zantout, Haochen Zhang, Pujith Kachana, Jinkai Qiu, Guofei Chen, Ji Zhang, Wenshan Wang
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-04-25 (更新: 2025-08-15)
备注: 8 pages, 6 figures, published in IROS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
SORT3D:利用大语言模型进行零样本3D场景理解的空间对象中心推理工具箱
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 零样本学习 大语言模型 空间推理 机器人导航
📋 核心要点
- 现有3D场景理解方法难以处理场景多样性、细粒度对象以及复杂语言描述,且缺乏足够的训练数据。
- SORT3D结合2D对象属性、启发式空间推理工具箱和大语言模型,实现零样本3D场景理解。
- SORT3D在复杂场景下实现了最先进的零样本性能,并在真实自动驾驶车辆上验证了其有效性。
📝 摘要(中文)
本文提出了一种名为SORT3D的方法,用于解释对象相关的语言并在3D场景中定位物体,同时考虑空间关系和属性。该方法对于在人类环境中运行的机器人至关重要。由于场景的多样性、大量细粒度对象以及语言参考的复杂性,这项任务极具挑战性。此外,在3D领域中,获取大量的自然语言训练数据非常困难。因此,方法需要从少量数据中学习并零样本泛化到新环境。SORT3D利用来自2D数据的丰富对象属性,并将基于启发式的空间推理工具箱与大语言模型(LLM)的顺序推理能力相结合。重要的是,该方法不需要文本到3D数据的训练,并且可以零样本应用于未见过的环境。实验表明,SORT3D在两个基准测试上实现了最先进的零样本性能。该流程已在两个自动驾驶车辆上实时运行,证明了该方法可用于先前未见过的真实环境中的目标导向导航。所有系统流程的源代码已公开发布。
🔬 方法详解
问题定义:论文旨在解决零样本3D场景理解问题,即在没有文本到3D训练数据的情况下,根据自然语言描述在3D场景中定位目标对象。现有方法难以泛化到新的、未见过的环境,并且难以处理复杂的空间关系和对象属性。
核心思路:论文的核心思路是将2D视觉信息、启发式空间推理和大语言模型的推理能力结合起来。通过利用2D数据中丰富的对象属性,并结合启发式规则进行空间推理,可以有效地缩小搜索空间。然后,利用大语言模型的强大语言理解能力,对候选对象进行排序和选择。
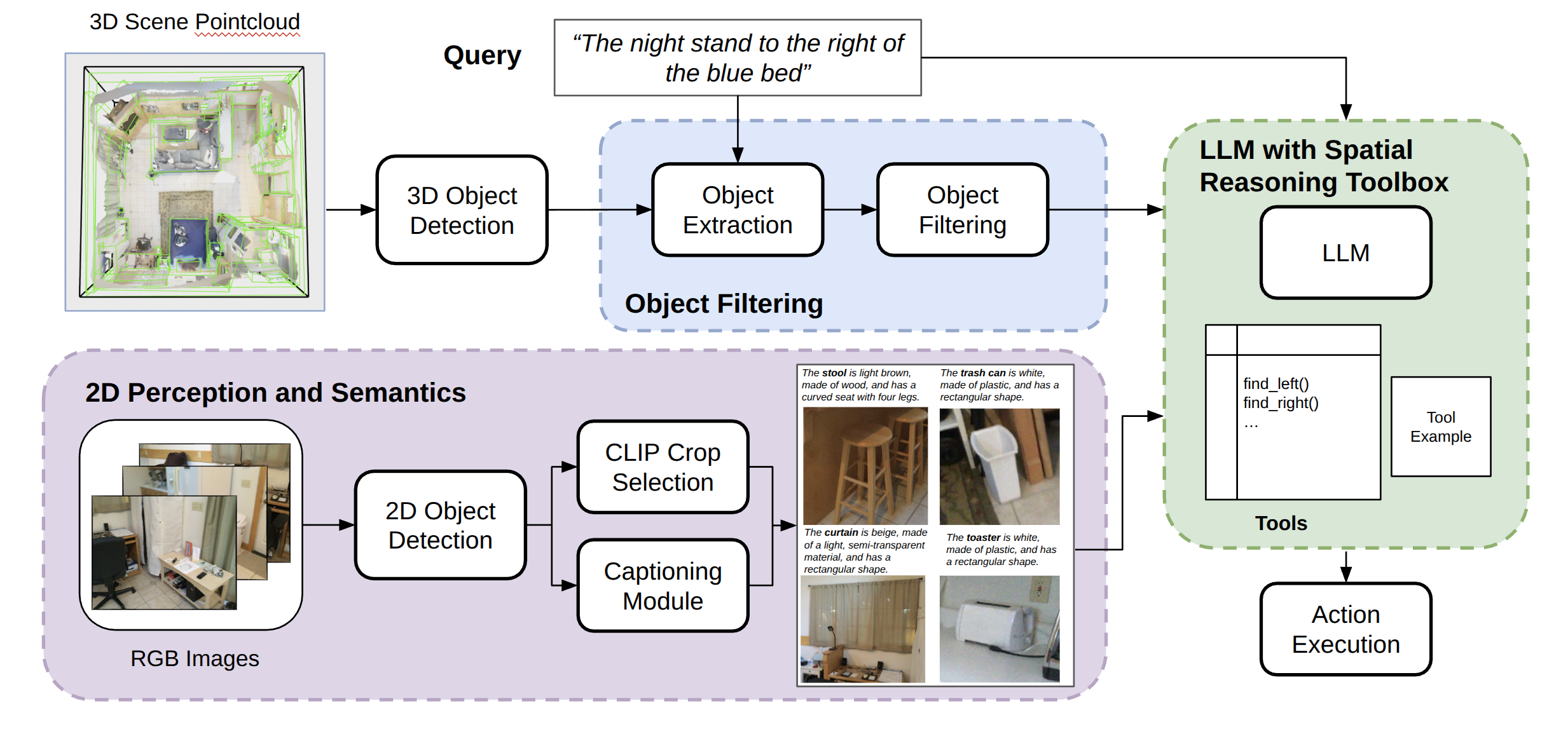
技术框架:SORT3D的整体框架包含以下几个主要模块:1) 2D对象检测与属性提取:利用现有的2D对象检测器提取场景中的对象及其属性。2) 3D场景重建:将2D检测结果投影到3D空间中,构建3D场景表示。3) 空间关系推理:使用启发式规则对3D对象之间的空间关系进行推理,例如“在...的左边”、“在...的上面”等。4) 大语言模型推理:将自然语言描述和候选对象的属性、空间关系等信息输入到大语言模型中,由大语言模型对候选对象进行排序和选择。
关键创新:SORT3D的关键创新在于将启发式空间推理与大语言模型相结合,实现了零样本3D场景理解。与传统的端到端方法相比,SORT3D不需要大量的文本到3D训练数据,并且可以更好地泛化到新的环境。此外,SORT3D利用了2D数据中丰富的对象属性,从而提高了场景理解的准确性。
关键设计:SORT3D的关键设计包括:1) 使用预训练的2D对象检测器提取对象属性。2) 设计了一组启发式规则用于空间关系推理。3) 使用Prompt Engineering来指导大语言模型进行推理。4) 使用简单的排序损失函数来优化大语言模型的参数(如果需要进行微调)。具体参数设置和网络结构的选择取决于具体的应用场景和可用资源。
🖼️ 关键图片


📊 实验亮点
SORT3D在两个基准测试上实现了最先进的零样本性能,证明了其有效性。此外,该方法已在真实自动驾驶车辆上进行了验证,表明其具有实际应用价值。具体性能数据和对比基线在论文中有详细描述,展示了SORT3D相对于现有方法的显著提升。
🎯 应用场景
SORT3D可应用于机器人导航、人机交互、智能家居等领域。例如,机器人可以根据用户的自然语言指令,在3D环境中找到目标对象并执行相应的任务。该研究有助于提升机器人在复杂环境中的自主性和智能化水平,促进人与机器的协同工作。
📄 摘要(原文)
Interpreting object-referential language and grounding objects in 3D with spatial relations and attributes is essential for robots operating alongside humans. However, this task is often challenging due to the diversity of scenes, large number of fine-grained objects, and complex free-form nature of language references. Furthermore, in the 3D domain, obtaining large amounts of natural language training data is difficult. Thus, it is important for methods to learn from little data and zero-shot generalize to new environments. To address these challenges, we propose SORT3D, an approach that utilizes rich object attributes from 2D data and merges a heuristics-based spatial reasoning toolbox with the ability of large language models (LLMs) to perform sequential reasoning. Importantly, our method does not require text-to-3D data for training and can be applied zero-shot to unseen environments. We show that SORT3D achieves state-of-the-art zero-shot performance on complex view-dependent grounding tasks on two benchmarks. We also implement the pipeline to run real-time on two autonomous vehicles and demonstrate that our approach can be used for object-goal navigation on previously unseen real-world environments. All source code for the system pipeline is publicly released at https://github.com/nzantout/SORT3D.