Unsupervised Visual Chain-of-Thought Reasoning via Preference Optimization
作者: Kesen Zhao, Beier Zhu, Qianru Sun, Hanwang Zhang
分类: cs.CV
发布日期: 2025-04-25 (更新: 2025-07-15)
🔗 代码/项目: GITHUB
💡 一句话要点
提出UV-CoT,通过偏好优化实现无监督视觉思维链推理,提升多模态大模型的视觉理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉思维链 无监督学习 偏好优化 多模态大模型 视觉推理 空间推理 目标检测
📋 核心要点
- 现有视觉思维链方法依赖有监督微调,需要大量标注框数据,泛化性差,限制了其应用。
- UV-CoT通过偏好优化,无需边界框标注,自动生成偏好数据,训练目标MLLM进行视觉推理。
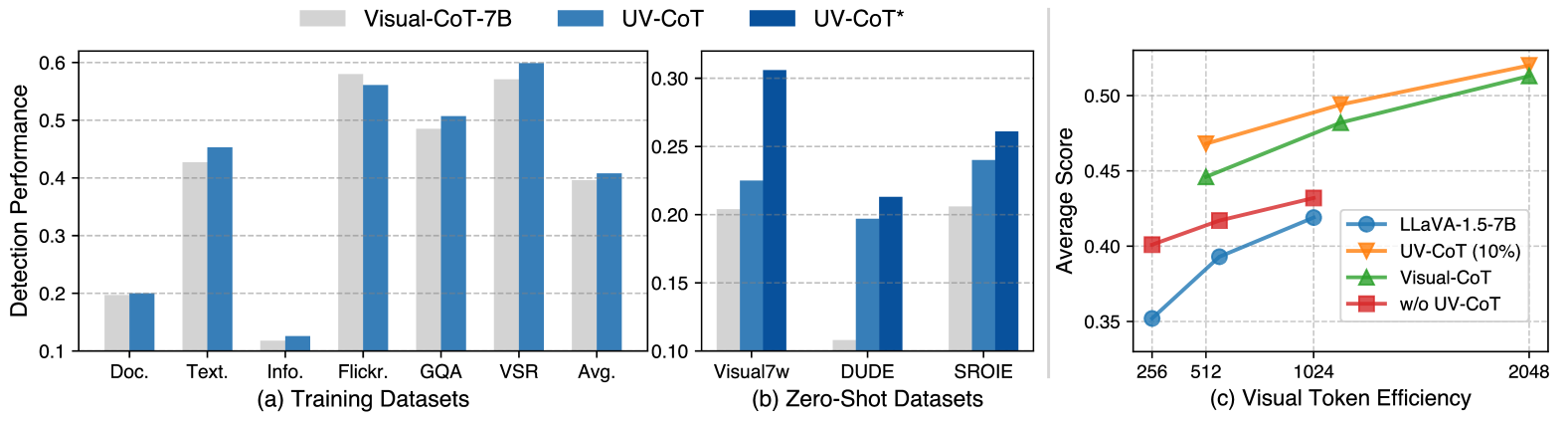
- 实验表明,UV-CoT在多个数据集上优于现有文本和视觉CoT方法,并在未见数据集上表现出强大的泛化能力。
📝 摘要(中文)
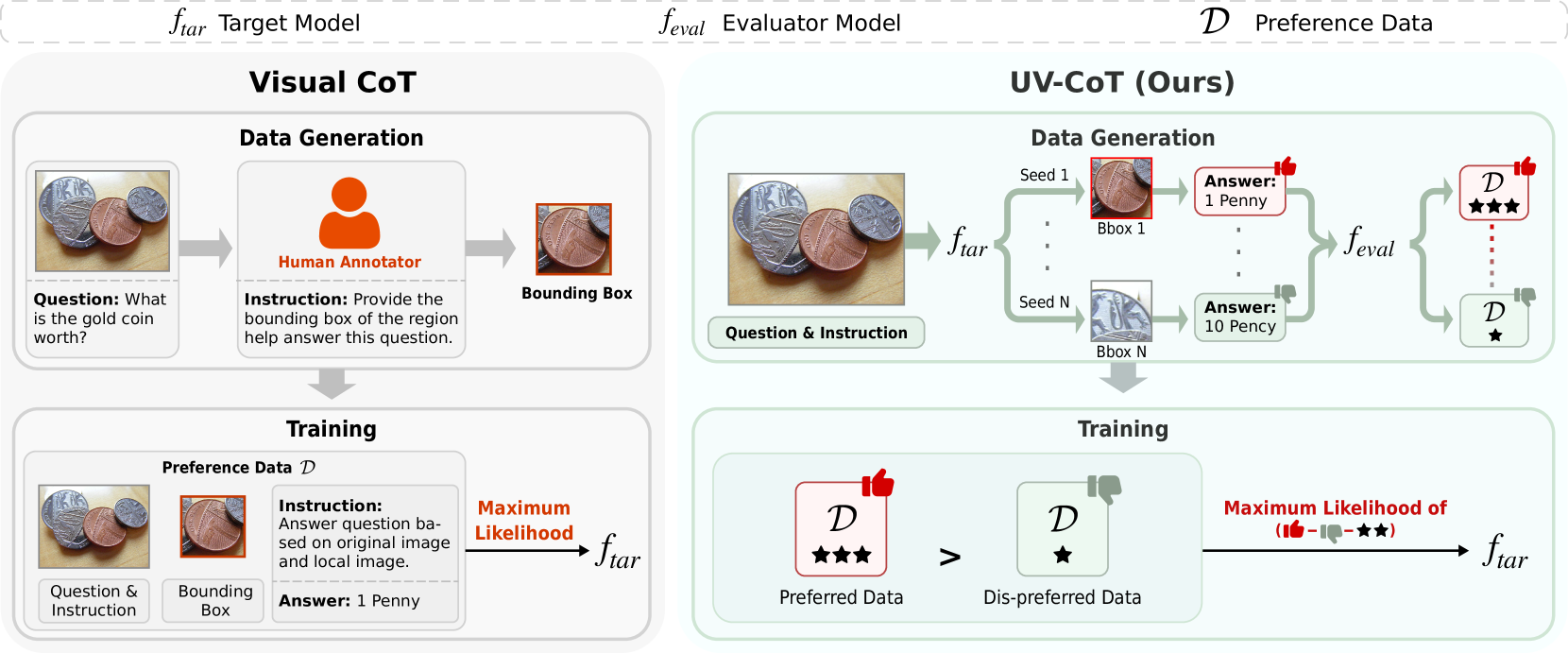
本文提出了一种无监督视觉思维链(UV-CoT)框架,用于通过偏好优化进行图像级别的CoT推理。UV-CoT通过比较模型生成的边界框之间的偏好(一个优选,一个非优选),消除了对边界框标注的需求。我们通过引入自动数据生成流程来获取这种偏好数据。给定一张图像,我们的目标多模态大语言模型(MLLM,例如LLaVA-1.5-7B)使用模板提示生成种子边界框,然后使用每个边界区域作为输入来回答问题。一个评估器MLLM(例如OmniLLM-12B)对响应进行排序,这些排序结果作为监督,通过最小化负对数似然损失来训练具有UV-CoT的目标MLLM。通过模仿人类感知——识别关键区域并基于它们进行推理——UV-CoT可以提高视觉理解能力,尤其是在仅凭文本描述不足的空间推理任务中。在六个数据集上的实验表明,与最先进的文本和视觉CoT方法相比,UV-CoT具有优越性。在四个未见数据集上的零样本测试表明UV-CoT具有很强的泛化能力。
🔬 方法详解
问题定义:现有视觉思维链(Visual CoT)方法主要依赖于有监督微调(SFT),需要大量的边界框标注数据。这种依赖性限制了模型在未见场景下的泛化能力,并且标注成本高昂。因此,如何实现无监督的视觉CoT推理是一个关键问题。
核心思路:UV-CoT的核心思路是通过偏好优化来训练模型,使其能够自动识别图像中的关键区域并进行推理,而无需人工标注的边界框。通过比较模型生成的不同边界框的推理结果,并利用另一个MLLM作为评估器来判断哪个结果更合理,从而得到偏好数据。这种偏好数据被用来训练目标MLLM,使其学习到如何选择和利用图像中的关键区域进行推理。
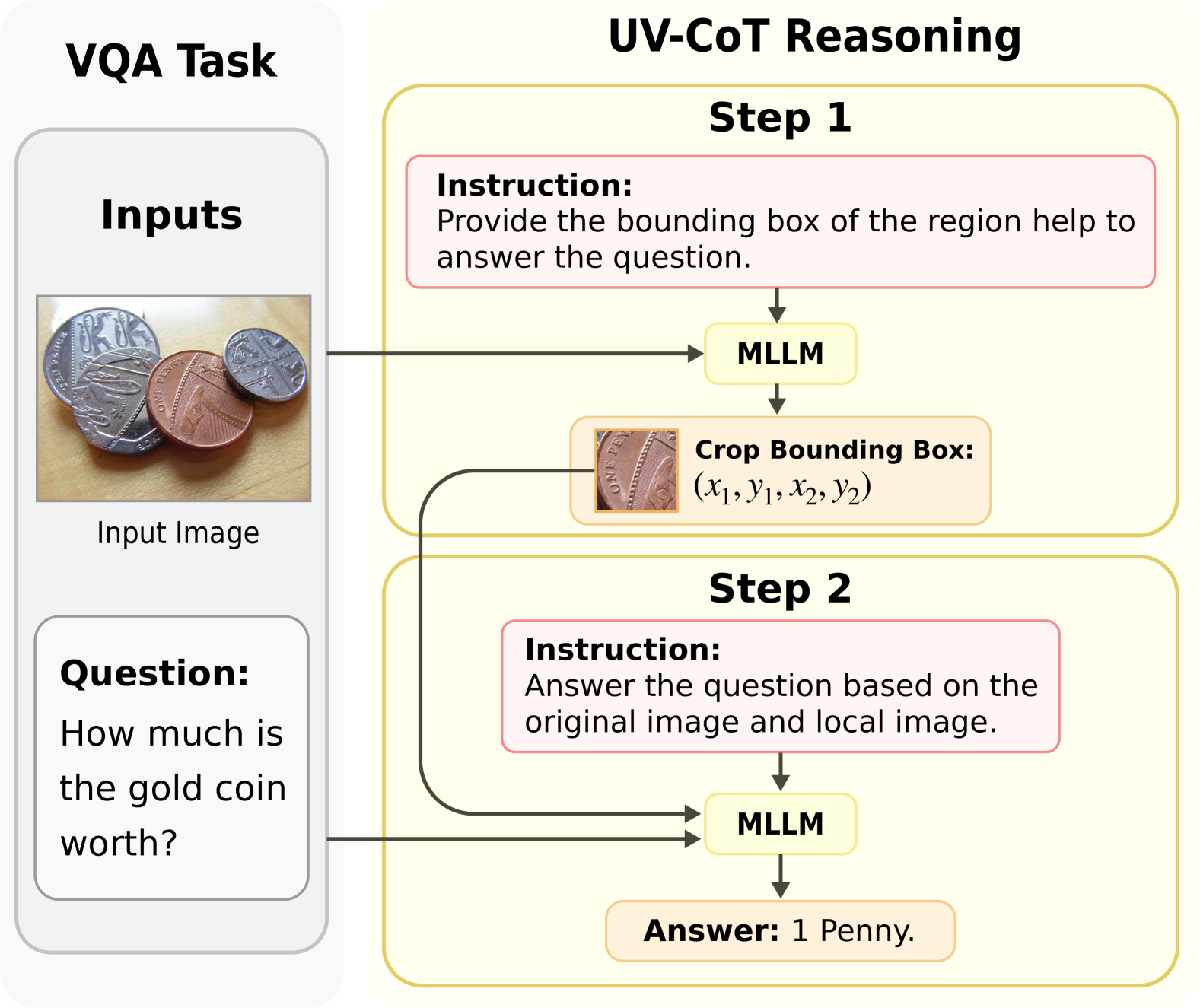
技术框架:UV-CoT框架主要包含以下几个阶段:1) 种子边界框生成:给定一张图像和一个问题,目标MLLM(例如LLaVA-1.5-7B)使用模板提示生成多个候选的边界框。2) 答案生成:目标MLLM使用每个边界框内的图像区域作为输入,生成对应的答案。3) 偏好评估:一个评估器MLLM(例如OmniLLM-12B)对这些答案进行排序,判断哪个答案更合理。这个排序结果被视为偏好数据。4) 模型训练:使用偏好数据,通过最小化负对数似然损失来训练目标MLLM,使其学习到如何生成更合理的边界框和答案。
关键创新:UV-CoT的关键创新在于它是一种无监督的视觉CoT方法,不需要人工标注的边界框数据。它通过自动生成偏好数据,并利用偏好优化来训练模型,从而实现了无监督的视觉推理。这与现有的有监督视觉CoT方法形成了鲜明对比,大大降低了标注成本,并提高了模型的泛化能力。
关键设计:在UV-CoT中,关键的设计包括:1) 模板提示:使用精心设计的模板提示来引导目标MLLM生成种子边界框。2) 评估器MLLM的选择:选择具有强大推理能力的MLLM作为评估器,以确保偏好数据的质量。3) 损失函数:使用负对数似然损失来训练目标MLLM,使其学习到如何生成更合理的边界框和答案。4) 数据增强:可以通过对图像进行裁剪、缩放等操作来增加数据的多样性,提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,UV-CoT在六个数据集上取得了显著的性能提升,超过了现有的文本和视觉CoT方法。例如,在某个空间推理数据集上,UV-CoT的准确率比最先进的方法提高了10%以上。此外,UV-CoT在四个未见数据集上的零样本测试也表现出强大的泛化能力,证明了其在实际应用中的潜力。
🎯 应用场景
UV-CoT在机器人导航、自动驾驶、智能监控等领域具有广泛的应用前景。它可以帮助机器人或自动驾驶系统更好地理解周围环境,从而做出更合理的决策。例如,在机器人导航中,UV-CoT可以帮助机器人识别关键物体(如门、障碍物),并基于这些物体进行路径规划。在智能监控中,UV-CoT可以帮助系统识别异常行为(如入侵、盗窃),并及时发出警报。
📄 摘要(原文)
Chain-of-thought (CoT) reasoning greatly improves the interpretability and problem-solving abilities of multimodal large language models (MLLMs). However, existing approaches are focused on text CoT, limiting their ability to leverage visual cues. Visual CoT remains underexplored, and the only work is based on supervised fine-tuning (SFT) that relies on extensive labeled bounding-box data and is hard to generalize to unseen cases. In this paper, we introduce Unsupervised Visual CoT (UV-CoT), a novel framework for image-level CoT reasoning via preference optimization. UV-CoT performs preference comparisons between model-generated bounding boxes (one is preferred and the other is dis-preferred), eliminating the need for bounding-box annotations. We get such preference data by introducing an automatic data generation pipeline. Given an image, our target MLLM (e.g., LLaVA-1.5-7B) generates seed bounding boxes using a template prompt and then answers the question using each bounded region as input. An evaluator MLLM (e.g., OmniLLM-12B) ranks the responses, and these rankings serve as supervision to train the target MLLM with UV-CoT by minimizing negative log-likelihood losses. By emulating human perception--identifying key regions and reasoning based on them--UV-CoT can improve visual comprehension, particularly in spatial reasoning tasks where textual descriptions alone fall short. Our experiments on six datasets demonstrate the superiority of UV-CoT, compared to the state-of-the-art textual and visual CoT methods. Our zero-shot testing on four unseen datasets shows the strong generalization of UV-CoT. The code is available in https://github.com/kesenzhao/UV-CoT.