Interpretable Affordance Detection on 3D Point Clouds with Probabilistic Prototypes
作者: Maximilian Xiling Li, Korbinian Rudolf, Nils Blank, Rudolf Lioutikov
分类: cs.CV, cs.RO
发布日期: 2025-04-25
💡 一句话要点
提出基于概率原型学习的三维点云可解释Affordance检测方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: Affordance检测 三维点云 原型学习 可解释性 人机交互
📋 核心要点
- 现有Affordance检测模型(如PointNet++)是黑盒,缺乏透明度,难以信任和调试。
- 论文将原型学习引入三维点云Affordance检测,通过学习具有代表性的原型来实现可解释性。
- 实验表明,该方法在3D-AffordanceNet数据集上取得了与SOTA模型相当的性能,同时具备可解释性。
📝 摘要(中文)
机器人需要理解如何与环境中的物体交互,包括自主交互和人机交互。传统上,三维点云上的Affordance检测依赖于PointNet++、DGCNN或PointTransformerV3等深度学习模型,但这些模型是黑盒,无法提供决策过程的洞察。原型学习方法,如ProtoPNet,通过“这看起来像那个”的基于案例的推理方法,为黑盒模型提供了一种可解释的替代方案。然而,它们主要应用于基于图像的任务。本文将原型学习应用于三维点云上的Affordance检测模型。在3D-AffordanceNet基准数据集上的实验表明,原型模型在性能上与最先进的黑盒模型具有竞争力,并提供固有的可解释性。这使得原型模型成为需要更高信任和安全的人机交互场景的有希望的候选者。
🔬 方法详解
问题定义:论文旨在解决三维点云Affordance检测模型缺乏可解释性的问题。现有的深度学习模型,如PointNet++等,虽然性能优异,但其决策过程难以理解,限制了其在人机交互等安全敏感场景中的应用。
核心思路:论文的核心思路是利用原型学习(Prototypical Learning)方法,学习一组具有代表性的原型(Prototypes),每个原型代表一种特定的Affordance。模型通过比较输入点云与这些原型的相似度来进行Affordance预测,从而实现可解释性。模型预测结果可以追溯到最相似的原型,从而理解模型做出决策的原因。
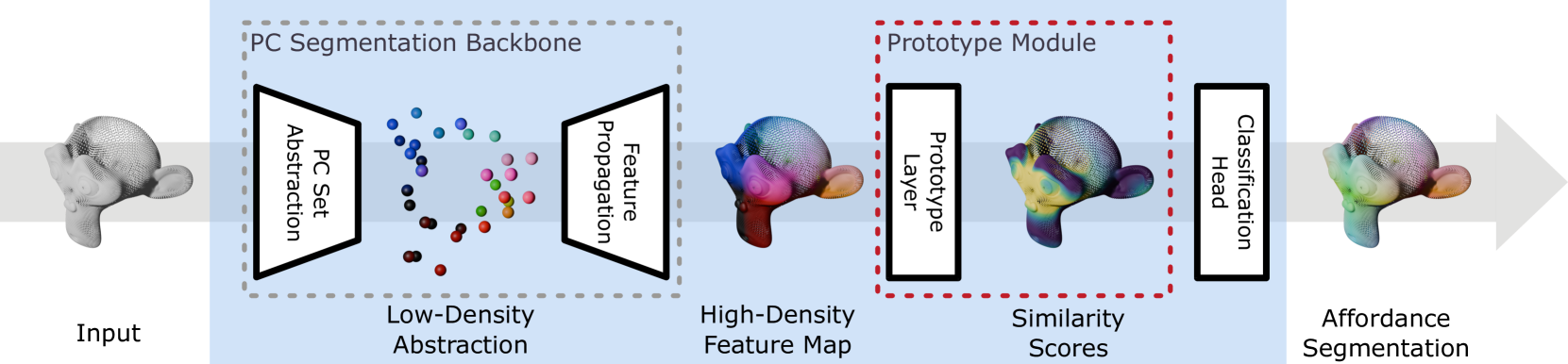
技术框架:该方法的技术框架主要包括以下几个模块:1) 点云特征提取模块:用于提取输入点云的特征表示。可以使用PointNet++等现有的点云处理网络。2) 原型层:包含一组可学习的原型向量,每个原型向量代表一种Affordance。3) 相似度计算模块:计算输入点云特征与每个原型向量之间的相似度。可以使用余弦相似度等度量。4) 分类器:基于相似度得分进行Affordance分类。
关键创新:该方法最重要的技术创新点是将原型学习应用于三维点云Affordance检测。与传统的黑盒模型相比,该方法具有固有的可解释性,可以提供模型决策的依据。此外,论文还探索了概率原型学习,为每个原型赋予概率分布,从而更好地建模Affordance的不确定性。
关键设计:论文的关键设计包括:1) 原型数量的选择:需要根据数据集的复杂度和Affordance的种类进行调整。2) 相似度度量的选择:不同的相似度度量可能会影响模型的性能和可解释性。3) 损失函数的设计:除了分类损失外,还需要引入原型相关的损失,例如原型之间的距离损失,以保证原型的多样性和代表性。4) 概率原型的建模:使用高斯混合模型对每个原型的特征分布进行建模,并使用EM算法进行参数估计。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于概率原型学习的Affordance检测模型在3D-AffordanceNet数据集上取得了与最先进的黑盒模型相当的性能。更重要的是,该模型提供了可解释的Affordance检测结果,可以清晰地展示模型决策的依据。例如,模型可以指出输入点云中哪些区域与某个原型最相似,从而解释为什么模型认为该物体具有某种Affordance。
🎯 应用场景
该研究成果可应用于人机协作机器人、自动驾驶、智能家居等领域。通过提供可解释的Affordance检测结果,可以提高机器人与人类交互的信任度,增强机器人的自主性和安全性。例如,在人机协作场景中,机器人可以向人类解释其对物体交互方式的理解,从而更好地协同完成任务。
📄 摘要(原文)
Robotic agents need to understand how to interact with objects in their environment, both autonomously and during human-robot interactions. Affordance detection on 3D point clouds, which identifies object regions that allow specific interactions, has traditionally relied on deep learning models like PointNet++, DGCNN, or PointTransformerV3. However, these models operate as black boxes, offering no insight into their decision-making processes. Prototypical Learning methods, such as ProtoPNet, provide an interpretable alternative to black-box models by employing a "this looks like that" case-based reasoning approach. However, they have been primarily applied to image-based tasks. In this work, we apply prototypical learning to models for affordance detection on 3D point clouds. Experiments on the 3D-AffordanceNet benchmark dataset show that prototypical models achieve competitive performance with state-of-the-art black-box models and offer inherent interpretability. This makes prototypical models a promising candidate for human-robot interaction scenarios that require increased trust and safety.