Masked strategies for images with small objects
作者: H. Martin Gillis, Ming Hill, Paul Hollensen, Alan Fine, Thomas Trappenberg
分类: cs.CV, eess.IV
发布日期: 2025-04-24
💡 一句话要点
针对小目标图像,提出基于掩码策略的自监督学习方法,提升分割与分类性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 掩码自编码器 自监督学习 小目标检测 语义分割 Transformer 医学图像分析 血液成分分析
📋 核心要点
- 现有深度学习方法在小目标图像分析中表现不佳,尤其是在领域外图像上。
- 论文提出一种基于掩码自编码器的自监督学习方法,学习图像表征,并用于下游语义分割。
- 实验表明,更小的掩码比例和patch大小能有效提升图像重建效果,预训练权重提升小目标分割性能。
📝 摘要(中文)
在检测和分类小型血液成分的血液学分析中,存在着巨大的挑战,尤其是在大量相似对象背景下,目标仅为几个像素大小。虽然使用预训练权重的监督深度学习方法,如残差网络和视觉Transformer,在许多应用中取得了成功,但当应用于学习表征领域之外的图像时,性能往往不尽如人意。一种解决方案是使用自监督模型,先学习表征,再将权重应用于下游任务。最近,掩码自编码器已被证明能有效地获取捕获全局上下文信息的表征。通过掩盖图像区域,让模型学习重建掩盖和未掩盖的区域,可以将权重用于各种应用。然而,如果图像中对象的大小小于掩码的大小,全局上下文信息就会丢失,几乎不可能重建图像。本研究探讨了使用MAE获取学习的ViT编码器表征时,掩码比例和patch大小对血液成分的影响。然后,我们将编码器权重应用于训练U-Net Transformer进行语义分割,以获得局部和全局上下文信息。实验结果表明,较小的掩码比例和patch大小可以改善使用MAE重建图像的效果。我们还展示了使用和不使用预训练权重的语义分割结果,其中较小的血液成分受益于预训练。总的来说,我们提出的方法为小目标的分割和分类提供了一种高效有效的策略。
🔬 方法详解
问题定义:论文旨在解决血液学图像中小目标(如血液成分)的检测与分类问题。现有方法,特别是依赖预训练权重的监督学习方法,在处理领域外图像或小目标时,性能显著下降。主要痛点在于小目标易受掩码操作影响,导致上下文信息丢失,难以有效重建和分割。
核心思路:论文的核心思路是利用掩码自编码器(MAE)进行自监督学习,学习图像的有效表征,然后将学习到的表征迁移到下游的语义分割任务中。通过调整掩码比例和patch大小,优化MAE的重建效果,从而提升小目标的分割性能。
技术框架:整体框架包含两个主要阶段:1) 使用MAE进行自监督预训练,学习ViT编码器的权重。2) 将预训练的ViT编码器权重迁移到U-Net Transformer中,进行语义分割任务的训练。U-Net Transformer结合了U-Net的局部信息提取能力和Transformer的全局上下文建模能力。
关键创新:论文的关键创新在于针对小目标图像,优化了MAE的掩码策略。通过实验发现,更小的掩码比例和patch大小能够更好地保留小目标的上下文信息,从而提升MAE的重建效果和下游分割性能。这与传统MAE通常采用较大掩码比例的设计有所不同。
关键设计:论文的关键设计包括:1) 探索不同的掩码比例和patch大小对MAE重建效果的影响。2) 使用ViT作为MAE的编码器,学习图像表征。3) 使用U-Net Transformer作为分割模型,结合局部和全局上下文信息。4) 通过实验对比使用和不使用预训练权重的分割性能,验证自监督学习的有效性。
🖼️ 关键图片

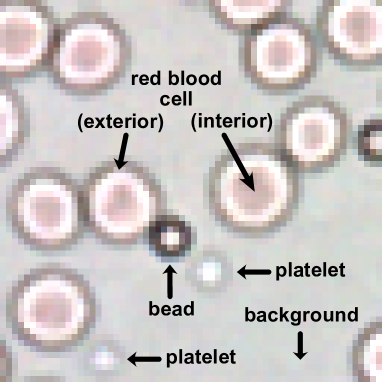
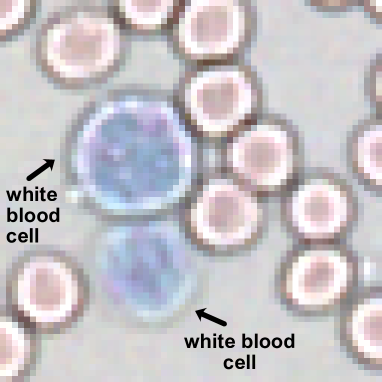
📊 实验亮点
实验结果表明,更小的掩码比例和patch大小能够显著提升MAE的图像重建效果。在语义分割任务中,使用预训练权重的U-Net Transformer在小目标分割上表现更优,验证了自监督学习的有效性。该方法为小目标图像分析提供了一种有效的解决方案。
🎯 应用场景
该研究成果可应用于医学图像分析领域,特别是血液细胞分析、病理切片分析等场景,能够提升小目标的检测、分割和分类精度,辅助医生进行疾病诊断和治疗方案制定。此外,该方法也可推广到其他小目标检测任务,如遥感图像分析、工业质检等。
📄 摘要(原文)
The hematology analytics used for detection and classification of small blood components is a significant challenge. In particular, when objects exists as small pixel-sized entities in a large context of similar objects. Deep learning approaches using supervised models with pre-trained weights, such as residual networks and vision transformers have demonstrated success for many applications. Unfortunately, when applied to images outside the domain of learned representations, these methods often result with less than acceptable performance. A strategy to overcome this can be achieved by using self-supervised models, where representations are learned and weights are then applied for downstream applications. Recently, masked autoencoders have proven to be effective to obtain representations that captures global context information. By masking regions of an image and having the model learn to reconstruct both the masked and non-masked regions, weights can be used for various applications. However, if the sizes of the objects in images are less than the size of the mask, the global context information is lost, making it almost impossible to reconstruct the image. In this study, we investigated the effect of mask ratios and patch sizes for blood components using a MAE to obtain learned ViT encoder representations. We then applied the encoder weights to train a U-Net Transformer for semantic segmentation to obtain both local and global contextual information. Our experimental results demonstrates that both smaller mask ratios and patch sizes improve the reconstruction of images using a MAE. We also show the results of semantic segmentation with and without pre-trained weights, where smaller-sized blood components benefited with pre-training. Overall, our proposed method offers an efficient and effective strategy for the segmentation and classification of small objects.