Token Sequence Compression for Efficient Multimodal Computing
作者: Yasmine Omri, Parth Shroff, Thierry Tambe
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-04-24
💡 一句话要点
提出基于聚类级别token聚合的视觉token压缩方法,提升多模态计算效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态计算 视觉语言模型 Token压缩 聚类聚合 视觉编码器
📋 核心要点
- 现有视觉语言模型计算成本高昂,视觉编码器存在冗余和效率低下的问题。
- 提出一种自适应压缩方法,通过聚类级别的token聚合来减少视觉token的数量。
- 实验表明,该方法优于现有的token选择和合并方法,能有效提升多模态计算效率。
📝 摘要(中文)
大型多模态模型(LMMs)的指数级增长推动了跨模态推理的进步,但也带来了巨大的计算成本。本文关注视觉语言模型,强调了当前视觉编码器中的冗余和低效性,并寻求构建一种用于多模态数据的自适应压缩方法。通过基准测试和定性分析,本文对各种视觉token选择和合并方法进行了表征。特别地,研究表明,简单的聚类级别token聚合在token选择和合并方面优于先前的最先进方法,包括视觉编码器级别的合并和基于注意力的方法。本文强调了当前视觉编码器中的冗余,并通过跨模态注意力可视化揭示了关于视觉token选择原则的一些令人困惑的趋势。这项工作是朝着更有效地编码和处理高维数据迈出的第一步,并为更具可扩展性和可持续性的多模态系统铺平了道路。
🔬 方法详解
问题定义:现有的大型多模态模型,特别是视觉语言模型,在跨模态推理方面取得了显著进展,但其计算成本也呈指数级增长。视觉编码器中存在大量的冗余信息,导致计算效率低下。现有的token选择和合并方法,例如在视觉编码器级别进行合并或使用基于注意力的方法,仍然无法有效地解决这个问题。
核心思路:本文的核心思路是通过对视觉token进行聚类,然后在聚类级别进行聚合,从而减少token的数量,降低计算复杂度。这种方法旨在去除视觉编码器中的冗余信息,同时保留关键的视觉特征,以保证模型的性能。选择聚类级别聚合的原因是其简单有效,并且能够自适应地处理不同类型的视觉信息。
技术框架:本文提出的方法主要包含以下几个阶段:1) 使用现有的视觉编码器(例如ViT)提取视觉特征;2) 对提取的视觉token进行聚类;3) 在每个聚类中,选择一个代表性的token或者将聚类中的token进行合并;4) 将压缩后的token序列输入到后续的多模态模型中进行处理。整个框架可以与现有的视觉语言模型无缝集成。
关键创新:本文最重要的技术创新点在于提出了聚类级别的token聚合方法。与现有的token选择和合并方法相比,该方法更加简单有效,并且能够自适应地处理不同类型的视觉信息。此外,本文还通过跨模态注意力可视化,揭示了关于视觉token选择原则的一些令人困惑的趋势,为未来的研究提供了新的思路。
关键设计:在聚类方面,可以使用例如K-means等经典的聚类算法。在每个聚类中,可以选择距离聚类中心最近的token作为代表,也可以将聚类中的token进行平均或者加权平均。具体的参数设置和损失函数取决于具体的应用场景和模型架构。例如,可以使用交叉熵损失函数来训练多模态模型,并使用验证集来调整聚类的数量和聚合策略。
🖼️ 关键图片


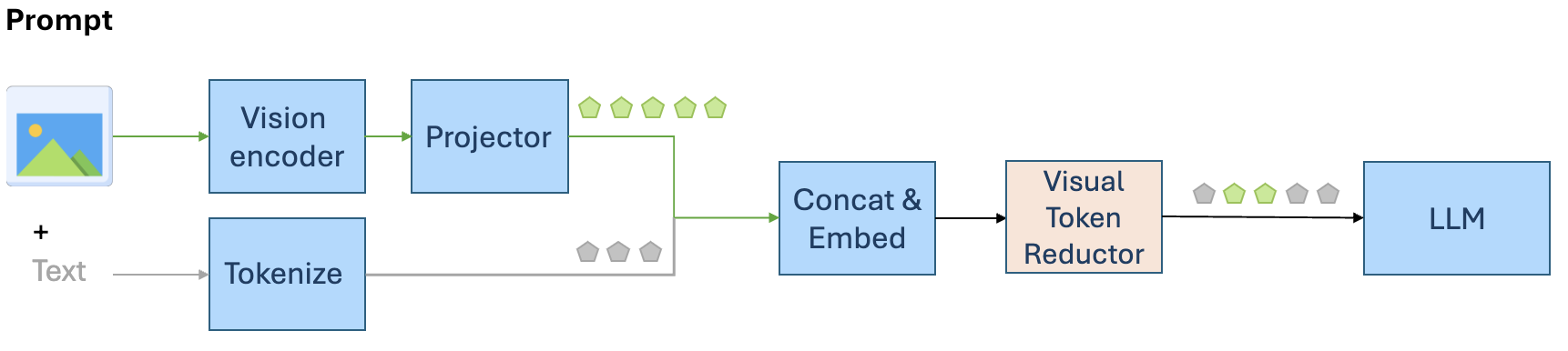
📊 实验亮点
实验结果表明,简单的聚类级别token聚合方法在token选择和合并方面优于先前的最先进方法,包括视觉编码器级别的合并和基于注意力的方法。具体的性能提升幅度取决于具体的任务和数据集,但总体趋势是该方法能够有效地降低计算成本,同时保持甚至提高模型的性能。
🎯 应用场景
该研究成果可广泛应用于各种需要处理高维视觉数据的多模态任务中,例如图像描述、视觉问答、视频理解等。通过降低计算成本,可以使得大型多模态模型在资源受限的设备上运行,并促进更可持续的人工智能发展。未来,该方法可以进一步扩展到其他模态的数据压缩,例如文本和音频。
📄 摘要(原文)
The exponential growth of Large Multimodal Models (LMMs) has driven advancements in cross-modal reasoning but at significant computational costs. In this work, we focus on visual language models. We highlight the redundancy and inefficiency in current vision encoders, and seek to construct an adaptive compression method for multimodal data. In this work, we characterize a panoply of visual token selection and merging approaches through both benchmarking and qualitative analysis. In particular, we demonstrate that simple cluster-level token aggregation outperforms prior state-of-the-art works in token selection and merging, including merging at the vision encoder level and attention-based approaches. We underline the redundancy in current vision encoders, and shed light on several puzzling trends regarding principles of visual token selection through cross-modal attention visualizations. This work is a first effort towards more effective encoding and processing of high-dimensional data, and paves the way for more scalable and sustainable multimodal systems.