Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
作者: Tiancheng Gu, Kaicheng Yang, Ziyong Feng, Xingjun Wang, Yanzhao Zhang, Dingkun Long, Yingda Chen, Weidong Cai, Jiankang Deng
分类: cs.CV
发布日期: 2025-04-24 (更新: 2025-12-08)
备注: 13 pages, 8 figures, Accepted by ACM MM2025, Project page: https://garygutc.github.io/UniME
💡 一句话要点
提出UniME框架,利用多模态LLM学习通用嵌入,提升跨模态检索性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 知识蒸馏 硬负例挖掘 跨模态检索
📋 核心要点
- 现有CLIP框架在多模态表征学习中存在文本截断、孤立编码和组合性不足等问题。
- UniME框架利用MLLM,通过知识蒸馏和硬负例增强的指令调优,学习更具区分性的表征。
- 实验表明,UniME在MMEB基准和多个检索任务上均取得了显著的性能提升,展现了优越的区分和组合能力。
📝 摘要(中文)
对比语言-图像预训练(CLIP)框架在多模态表征学习中被广泛应用,尤其是在图像-文本检索和聚类方面。然而,其有效性受到三个关键限制:(1)文本token截断,(2)孤立的图像-文本编码,以及(3)由于词袋行为导致的组合性不足。虽然最近的多模态大型语言模型(MLLM)在广义视觉-语言理解方面取得了显著进展,但它们在学习可迁移的多模态表征方面的潜力仍未得到充分探索。本文提出了UniME(通用多模态嵌入),这是一个新颖的两阶段框架,利用MLLM来学习用于各种下游任务的可区分表征。在第一阶段,我们执行来自强大的基于LLM的教师模型的文本区分知识蒸馏,以增强MLLM语言组件的嵌入能力。在第二阶段,我们引入了硬负例增强的指令调优,以进一步推进区分表征学习。具体来说,我们首先减轻假负例污染,然后在每个批次内为每个实例采样多个硬负例,迫使模型专注于具有挑战性的样本。这种方法不仅提高了区分能力,还增强了下游任务中的指令遵循能力。我们在MMEB基准和多个检索任务(包括短标题和长标题检索以及组合检索)上进行了大量实验。结果表明,UniME在所有任务中都实现了持续的性能改进,表现出卓越的区分和组合能力。
🔬 方法详解
问题定义:论文旨在解决CLIP等多模态表征学习方法在文本token截断、图像-文本孤立编码以及组合性不足的问题。这些问题限制了模型在复杂跨模态检索任务中的性能,尤其是在处理长文本和需要理解组合关系的场景下。现有方法难以充分利用多模态数据中的细粒度信息和上下文关系。
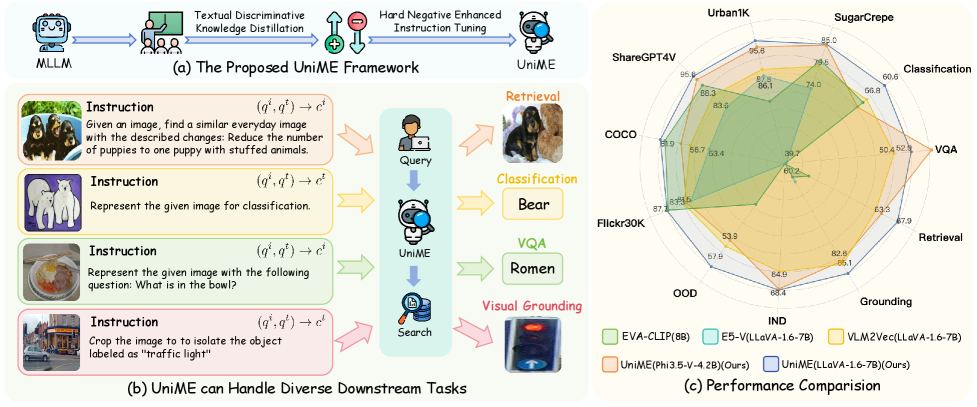
核心思路:UniME的核心思路是利用多模态大型语言模型(MLLM)强大的语言理解和生成能力,通过两阶段训练策略学习更具区分性的通用多模态嵌入。第一阶段通过知识蒸馏增强MLLM的语言表征能力,第二阶段通过硬负例增强的指令调优提升模型的区分能力和指令遵循能力。
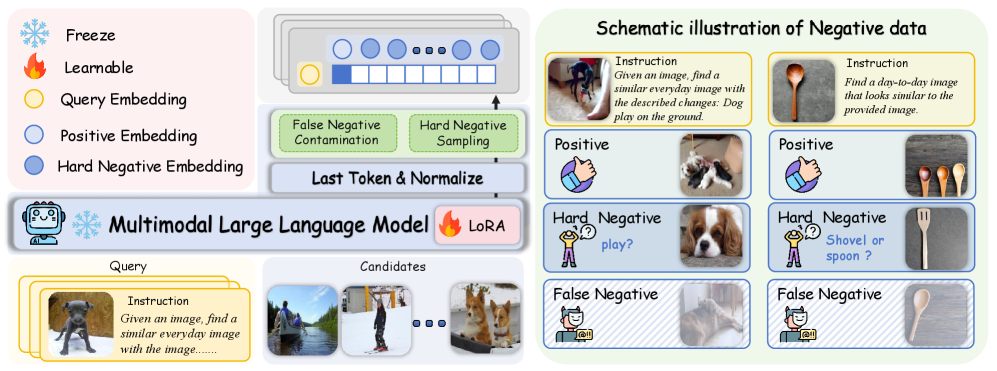
技术框架:UniME框架包含两个主要阶段:1) 文本区分知识蒸馏:使用基于LLM的教师模型生成高质量的文本嵌入,然后将这些嵌入作为目标,训练MLLM的语言编码器,提升其文本表征能力。2) 硬负例增强的指令调优:首先减轻假负例污染,然后针对每个样本,在批次内采样多个硬负例,迫使模型学习区分相似但不同的样本,从而提高区分能力。
关键创新:UniME的关键创新在于结合了知识蒸馏和硬负例挖掘,充分利用了MLLM的潜力。传统的对比学习方法容易受到假负例的影响,而UniME通过减轻假负例污染和引入硬负例,有效地解决了这个问题。此外,通过指令调优,UniME还提升了模型在下游任务中的指令遵循能力。
关键设计:在知识蒸馏阶段,使用了交叉熵损失函数来衡量MLLM语言编码器的输出与教师模型输出之间的差异。在硬负例增强的指令调优阶段,使用了对比损失函数,并动态调整硬负例的采样策略。具体来说,首先使用余弦相似度计算样本之间的相似度,然后选择相似度最高的若干个样本作为硬负例。此外,还设计了特定的指令模板,引导模型学习区分不同模态之间的关系。
🖼️ 关键图片

📊 实验亮点
UniME在MMEB基准测试和多个检索任务中取得了显著的性能提升。例如,在长标题检索任务中,UniME的性能超越了现有方法,取得了超过5%的提升。此外,在组合检索任务中,UniME展现了卓越的组合能力,能够准确理解复杂的组合关系,并检索到相关的图像或文本。
🎯 应用场景
UniME框架具有广泛的应用前景,可应用于图像-文本检索、视频-文本检索、跨模态内容理解等领域。该方法能够提升搜索引擎的准确性和效率,改善多媒体内容推荐系统的性能,并为智能客服、视觉问答等应用提供更强大的技术支持。未来,该研究有望推动多模态人工智能的发展,实现更智能、更自然的跨模态交互。
📄 摘要(原文)
The Contrastive Language-Image Pre-training (CLIP) framework has become a widely used approach for multimodal representation learning, particularly in image-text retrieval and clustering. However, its efficacy is constrained by three key limitations: (1) text token truncation, (2) isolated image-text encoding, and (3) deficient compositionality due to bag-of-words behavior. While recent Multimodal Large Language Models (MLLMs) have demonstrated significant advances in generalized vision-language understanding, their potential for learning transferable multimodal representations remains underexplored.In this work, we present UniME (Universal Multimodal Embedding), a novel two-stage framework that leverages MLLMs to learn discriminative representations for diverse downstream tasks. In the first stage, we perform textual discriminative knowledge distillation from a powerful LLM-based teacher model to enhance the embedding capability of the MLLMś language component. In the second stage, we introduce hard negative enhanced instruction tuning to further advance discriminative representation learning. Specifically, we initially mitigate false negative contamination and then sample multiple hard negatives per instance within each batch, forcing the model to focus on challenging samples. This approach not only improves discriminative power but also enhances instruction-following ability in downstream tasks. We conduct extensive experiments on the MMEB benchmark and multiple retrieval tasks, including short and long caption retrieval and compositional retrieval. Results demonstrate that UniME achieves consistent performance improvement across all tasks, exhibiting superior discriminative and compositional capabilities.