DRC: Enhancing Personalized Image Generation via Disentangled Representation Composition
作者: Yiyan Xu, Wuqiang Zheng, Wenjie Wang, Fengbin Zhu, Xinting Hu, Yang Zhang, Fuli Feng, Tat-Seng Chua
分类: cs.CV, cs.IR
发布日期: 2025-04-24 (更新: 2025-08-04)
备注: Accepted for publication in ACM MM'25
💡 一句话要点
提出DRC,通过解耦表征组合增强个性化图像生成,缓解指导崩溃问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化图像生成 解耦表征学习 多模态模型 指导崩溃 风格迁移
📋 核心要点
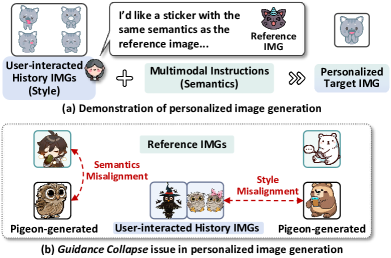
- 现有基于LMM的个性化图像生成方法难以准确捕捉和融合用户风格偏好和语义意图,存在视觉特征纠缠导致的指导崩溃问题。
- DRC通过解耦表征组合增强LMM,显式提取用户风格偏好和语义意图,形成用户特定的潜在指令,指导图像生成。
- 实验表明,DRC在缓解指导崩溃问题上表现出竞争力的性能,验证了解耦表征学习在个性化图像生成中的重要性。
📝 摘要(中文)
个性化图像生成是多模态内容创作中一个很有前景的方向。它旨在通过利用用户交互的历史图像和多模态指令,合成针对个人风格偏好(例如,配色方案、角色外观、布局)和语义意图(例如,情感、动作、场景上下文)量身定制的图像。尽管取得了显著进展,但现有方法——无论是基于扩散模型、大型语言模型还是大型多模态模型(LMM)——都难以准确捕捉和融合用户风格偏好和语义意图。特别是,最先进的基于LMM的方法受到视觉特征纠缠的影响,导致指导崩溃,即生成的图像无法保留用户偏好的风格或反映指定的语义。为了解决这些限制,我们引入了DRC,一种新颖的个性化图像生成框架,通过解耦表征组合来增强LMM。DRC显式地从历史图像和参考图像中分别提取用户风格偏好和语义意图,以形成用户特定的潜在指令,从而指导LMM中的图像生成。具体来说,它涉及两个关键的学习阶段:1) 解耦学习,它采用双塔解耦器来显式分离风格和语义特征,通过具有难度感知重要性采样的重建驱动范式进行优化;2) 个性化建模,它应用语义保留增强来有效地调整解耦表示,以实现鲁棒的个性化生成。在两个基准上的大量实验表明,DRC表现出有竞争力的性能,同时有效地缓解了指导崩溃问题,突出了用于可控和有效的个性化图像生成的解耦表示学习的重要性。
🔬 方法详解
问题定义:个性化图像生成旨在根据用户的历史图像和多模态指令,生成符合用户风格偏好和语义意图的图像。现有方法,特别是基于大型多模态模型(LMM)的方法,存在视觉特征纠缠的问题,导致生成的图像无法准确反映用户的风格和意图,即“指导崩溃”。
核心思路:DRC的核心思路是将风格和语义特征解耦,分别从用户的历史图像和参考图像中提取风格偏好和语义意图,并将它们组合成用户特定的潜在指令。通过这种方式,可以更精确地控制图像生成过程,避免风格和语义的混淆,从而缓解指导崩溃问题。
技术框架:DRC框架包含两个主要阶段:解耦学习和个性化建模。在解耦学习阶段,使用一个双塔解耦器来显式地分离风格和语义特征。该解耦器通过重建驱动的范式进行优化,并采用难度感知重要性采样来提高学习效率。在个性化建模阶段,应用语义保留增强来调整解耦的表示,以提高个性化生成的鲁棒性。整个框架以LMM为基础,利用解耦的风格和语义信息来指导图像生成。
关键创新:DRC的关键创新在于显式地解耦风格和语义特征,并将其用于个性化图像生成。与现有方法相比,DRC能够更有效地分离和控制风格和语义信息,从而避免了特征纠缠和指导崩溃问题。难度感知重要性采样进一步提高了训练效率和解耦效果。
关键设计:双塔解耦器由两个编码器组成,分别用于提取风格和语义特征。重建损失函数用于确保解耦后的特征能够重建原始图像。难度感知重要性采样根据样本的重建误差动态调整采样概率,从而更关注难以重建的样本。语义保留增强包括对图像进行轻微的几何变换和颜色扰动,以提高模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
DRC在两个基准测试上进行了广泛的实验,结果表明DRC能够有效地缓解指导崩溃问题,并表现出与现有方法相比具有竞争力的性能。具体来说,DRC在用户指定的风格和语义的准确性方面取得了显著提升,生成的图像更符合用户的个性化需求。实验结果验证了解耦表示学习对于可控和有效的个性化图像生成的重要性。
🎯 应用场景
DRC可应用于各种个性化内容创作场景,例如定制化头像生成、个性化艺术创作、以及根据用户偏好生成特定风格的商品图像。该技术能够提升用户在内容创作过程中的控制力,并为电商、社交媒体等领域带来更丰富的用户体验和商业价值。未来,DRC可以与虚拟现实、增强现实等技术结合,创造更具沉浸感的个性化体验。
📄 摘要(原文)
Personalized image generation has emerged as a promising direction in multimodal content creation. It aims to synthesize images tailored to individual style preferences (e.g., color schemes, character appearances, layout) and semantic intentions (e.g., emotion, action, scene contexts) by leveraging user-interacted history images and multimodal instructions. Despite notable progress, existing methods -- whether based on diffusion models, large language models, or Large Multimodal Models (LMMs) -- struggle to accurately capture and fuse user style preferences and semantic intentions. In particular, the state-of-the-art LMM-based method suffers from the entanglement of visual features, leading to Guidance Collapse, where the generated images fail to preserve user-preferred styles or reflect the specified semantics. To address these limitations, we introduce DRC, a novel personalized image generation framework that enhances LMMs through Disentangled Representation Composition. DRC explicitly extracts user style preferences and semantic intentions from history images and the reference image, respectively, to form user-specific latent instructions that guide image generation within LMMs. Specifically, it involves two critical learning stages: 1) Disentanglement learning, which employs a dual-tower disentangler to explicitly separate style and semantic features, optimized via a reconstruction-driven paradigm with difficulty-aware importance sampling; and 2) Personalized modeling, which applies semantic-preserving augmentations to effectively adapt the disentangled representations for robust personalized generation. Extensive experiments on two benchmarks demonstrate that DRC shows competitive performance while effectively mitigating the guidance collapse issue, underscoring the importance of disentangled representation learning for controllable and effective personalized image generation.